Как удалить дубли страниц в вордпресс. Как убрать дубли страниц в WordPress и вернуть All in One SEO Pack. Используем плагин Yoast SEO
Мощь? Ну тогда получите еще одну! Не менее мощную. Кучу дублей replytocom вы нашли, это хорошо!
Вот сегодня найдете еще кучу других дублей, которые так же убивают, отравляют ваш блог и плодятся эти дубли все быстрее и быстрее с каждым днем...
Вообще! То что я сейчас расскажу в этой статье это фишки взятые из курса и по идее я не хотел писать эту статью, выставляя ее на всеобщее обозрение. Как говориться, не хотел палить тему. НО! Посидев, подумав, я пришел к выводу, что это просто необходимо сделать.
Почему? А потому что после статьи про дубли replytocom я увидел, что многие начали тупо копировать мой файл robots.txt и думать, что теперь у них все будет в шоколаде. Смотреть на это просто так я не могу, так что приходится вот этой статьей спасать тех засранцев, которые скопировали мой роботс даже ни о чем не думая.
Ну да ладно, в курсе 3.0 есть и так много интересных и полезных фишек. Все естественно на блоге этом спалены никогда не будут.
Итак ок! Поехали. Вспоминаем идею моей прошлой статьи про дубли replytocom. Идея заключается в том, что не надо закрывать в robots.txt доступ к чему либо на блоге. Мы наоборот все открываем, мол, — «Привет робот заходи, все смотри», он приходит и видит метатег:
Таким образом он уже не будет брать страницу в сопли. А если в роботсе будет закрыто, то возьмет все равно на всякий пожарный. =) По количеству комментариев к прошлой статье я понял, что многие ни чего не поняли. было куча вопросов и про robots и про плагин и про редирект и т.д.
Короче ребята, вот тут все ответы на ваши вопросы. Посмотрите это видео перед тем, как читать статью дальше.
Гут! Теперь вспоминаем как мы находили дубли replytocom в выдаче google! Вот так:
site:site.ru replytocom
Как найти дубли страниц на wordpress?
Ок, теперь давайте будем искать другие дубли страниц. А именно дубли:
feed
tag
page
comment-page
attachment
attachment_id
category
trackback
Искать их так же как и replytocom. Снова давайте я поиздеваюсь над уже не просто легендарным, а легендарнейшим Александром Быкадоровым . Захожу в google и вбиваю вот так:
Жму - «Показать скрытые результаты» и вижу вот что:

490 дублей страниц. Feed — это отростки на конце url статей. В любой вашей статье нажмите ctr + u и в исходном коде увидите ссылку с feed на конце. Короче от них надо тоже избавляться. Вопрос — как? Что нам все рекомендуют делать в интернете? Правильно, добавлять что-то подобное в robots.txt:
Disallow: */*/feed/*/
Disallow: */feed
Но если мы посмотрим на блоги, то у всех есть feed в выдаче google. Ну так получается не работает запрет в Роботсе верно? Как тогда от них избавляться? Очень просто — открытием feed в robots.txt + редирект. Об этом дальше.
Хорошо! Это мы проверили только дубли страниц feed, а давайте еще другие проверим. В общем набирайте вот так в google:
site:site.ru feed
site:site.ru tag
site:site.ru attachment
site:site.ru attachment_id
site:site.ru page
site:site.ru category
site:site.ru comment-page
site:site.ru trackback
Все как обычно! Сначала вбиваем, потом идем в конце и нажимаем «показать скрытые результаты» . Вот что я вижу у Александра:




Ну дублей tag, comment-page и trackback у Саши я не нашел. Ну как вы свои блоги проверили? У вас сейчас случайно не такое же лицо, которое я показал в прошлой статье в конце (см. фото)? Если такое, то печально. Ну ни чего, сейчас все поправим.
Как избавиться от дублей страниц?
Итак! Что надо сделать? Первым делом берем вот этот файл robots.txt и ставим его себе:
User-agent: * Disallow: /wp-includes Disallow: /wp-feed Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Host: site.ru Sitemap: http://site.ru/sitemap.xml User-agent: Googlebot-Image Allow: /wp-content/uploads/ User-agent: YandexImages Allow: /wp-content/uploads/
Только не забудьте site.ru заменить на ваш блог. Так, ок. Роботс поставили. То есть открыли все, что было закрыто. А у многих закрыто было многое и category и tag и feed и page и comment и т.д. и т.п. Теперь нам надо на страницах дублей где есть возможность поставить метатег noindex тот самый:
А где этой возможности нет, там ставим редирект со страницы дубля на основную страницу. Сейчас чтобы вы не сошли с ума о того, что я тут буду рассказывать, лучше сделайте следующее:
Шаг №1: Добавьте вот эти строки в свой файл.htaccess:
RewriteRule (.+)/feed /$1 RewriteRule (.+)/comment-page /$1 RewriteRule (.+)/trackback /$1 RewriteRule (.+)/comments /$1 RewriteRule (.+)/attachment /$1 RewriteCond %{QUERY_STRING} ^attachment_id= RewriteRule (.*) $1?
Файл этот лежит у вас в корне блога где и папки wp-admin, wp-content и т.д. Вот качните его на пк, откройте блокнотиком и добавьте. Вот так все должно примерно быть:
# BEGIN WordPress RewriteEngine On RewriteBase / RewriteCond %{QUERY_STRING} ^replytocom= RewriteRule (.*) $1? RewriteRule (.+)/feed /$1 RewriteRule (.+)/comment-page /$1 RewriteRule (.+)/trackback /$1 RewriteRule (.+)/comments /$1 RewriteRule (.+)/attachment /$1 RewriteCond %{QUERY_STRING} ^attachment_id= RewriteRule (.*) $1? RewriteRule ^index\.php$ - [L] RewriteCond %{REQUEST_FILENAME} !-f RewriteCond %{REQUEST_FILENAME} !-d RewriteRule . /index.php [L] # END WordPress
Шаг №2: Вот этот код добавьте в файл function.php сразу в начале после
/*** ДОБАВЛЯЕМ meta robots noindex,nofollow ДЛЯ СТРАНИЦ ***/ function my_meta_noindex () { if (is_paged() // Все и любые страницы пагинации) {echo ""." "."\n";} } add_action("wp_head", "my_meta_noindex", 3); // добавляем свой noindex,nofollow в head
Шаг №3: Заходим в плагин All in One Seo Pack и ставим вот так:

Шаг №4: Заходим в админку — Настройки — Обсуждения и убираем галочку с "Разбивать комментарии верхнего уровня на страницы":

Окей. Это все. Теперь надо ждать переиндексации, чтобы все дубли опять же вылетели из выдачи.
Что мы сделали? Повторю, в robots.txt мы все открыли, о есть теперь робот будет заходить беспрепятственно. Далее на таких страницах как page, tag и category он будет видеть тот самый запрещающий метатег noindex и соответственно не будет брать страницу в выдачу.
На страницы page мы добавили метатег руками вот тем кодом, который вы вставили в файл function.php из шага №2, а страницы tag и category закрылись метатегом благодаря тому, что в плагине All in One Seo Pack мы поставили галочки там где надо, как я показал в шаге №3.
На страницах feed, attachment, attachment_id, comment-page и trackback этот метатег мы не ставили, мы поставили 301 редирект добавлением нескольких строк в.htaccess, что я вам дал в шаге №1.
В админке в настройках обсуждения мы сняли галочку, чтобы у нас комментарии не разбивались на страницы и не создавали новые url.
В общем теперь робот приходя на эти страницы (feed, attachment, attachment_id, trackback), будет автоматически перебрасываться на основные страницы и как правило, дублированные не забирать в выдачу. Редирект — сила! Ну вот собственно и все.
Если вы будете использовать эту схему, то дублей у вас не будет. Схема рабочая и проверена. Кстати пользуясь случаем хочу немного похвастаться. Вот что у меня было по проиндексированным страницам в вебмастере google в апреле:

А вот что сейчас:

А вот что по трафику с Google:

Как видите дублей все меньше становится и трафик все выше и выше. Короче все работает! Честно говоря так обидно, что аж 2 года сидел с этими дублями, не знал про них вообще, как от них избавиться и как следствие сидел на 140-150 посетителях в сутки с google. =))
Кстати трафик с Яндекса тоже заметен уже.
Естественно не все сразу. Жду год. Поставил себе такой срок. Уверен, что за год все дубли уйдут. Вот за 2 месяца ушло более 7200. А как обстоят дела у вас? =) Мне тут уже люди пишут кстати, поставили мою схему и посещалка вверх пошла.
Ребята, схема понятна? Если что вот еще видео специально записал, посмотрите, может быть тут я объяснил по понятнее:
На этом тему дублированного контента на блоге я заканчиваю. Что еще не сказал. Мы с вами рассмотрели нахождение только, так скажем, официальных =))) дублей. Есть еще кроме дублей — шлак и прочий мусор. Его тоже нужно уметь находить и удалять. Вот например некоторые мусорные страницы блога Александра Быкадорова:

И таких вот кривых соплей может быть очень и очень много! У кого-то их тысячи. Как находить этот мусор и много еще чего интересного, я рассказывал в курсе Как стать блоггером тысячником 3.0 . Сегодня последний день цена 2370 и 2570, завтра будет 3170 и 3470.
Помните — хороший сайт — это сайт, на который пришел робот, загрузил главную страницу index, все стальные страницы вашего блога типа «Об авторе», «Контакты»..., и все ваши статьи! Все, больше ни чего в выдачу забирать он не должен. Если забирает, но это печально и плохо.
В заключение статьи хотелось бы поблагодарить Сашу Алаева , мега супер-пупер крутого SEOшника, за помощь в создании и robots.txt и.htaccess. Эти рекомендации и не только эти, очень помогли мне в написании этих двух статей про дубли, а так же в создании курса КСБТ 3.0.
Ну все! Напишите в комментариях кто сколько у себя дублей нашел! =) Может быть у вас еще есть какие-то дубли в выдаче? Можно попробовать разобраться в их устранении!
P.S. Давайте поржем еще раз в завершении. Вот лицо человека, который через несколько лет ведения блога узнал, что у него куча дублей и мусора в выдаче:

Всем пока и удачных выходных!
С уважением, Александр Борисов
Всем привет! На днях обнаружил баг в WordPress, который создает бесчисленное множество дублей страниц. Проблема касается всех, у кого есть сайты на этой CMS. Да-да, многими любимый движок может создать большое количество идентичных документов.
Напугал? Не переживайте =) . Баг, действительно, серьезный, но исправить его можно достаточно просто. Ниже я расскажу, что это за зверь и как от него избавиться.

И вот, зайдя в статистику для блога, был неприятно шокирован - сотни дублей несуществующих документов.


Оказывается, если к любому посту в блоге добавить любые цифры, то WordPress создаст такую страницу - она будет идентична основной записи. Баг с постраничной навигацией отдельных постов - сотни или тысячи вероятных дублей.
На таких страницах нет мета-тега robots и есть canonical, который в качестве канонического документа указывает именно дубль.
Проверьте, у вас также?
Усугубляет ситуацию связь с плагином All in one SEO pack, который дополнительно дает ссылку на предыдущую запись: поисковый робот не только заходит, по сути, на несуществующую страницу, но и начинает ходить по другим таким же. Добавлялось и удалялось сотни подобных "постов".

Я начал копать глубже и создал топик на wordpress.org. Оказалось, что еще в 2014 был баг при создании многостраничных постов с помощью тега . Тогда также создавались несуществующие документы, но canonical для 2-й, 3-й или последующих страниц, наоборот, указывали всегда на первую, то есть не индексировались.
Начиная с WordPress 4.4 баг с canonical убрали (у каждой "пагинированной" страницы поста появился свой каноникал), а вот ошибку с созданием несуществующих документов не убрали. Поэтому сейчас индексируется больше, чем нужно .
Что делать и как убрать дубли?
Сперва, хочу сказать, что в одной из ближайших версий вордпресса этот баг постараются исправить.

Пока же нам придется убирать его, так называемыми, "костылями" . Существует 2 варианта.
1) Плагин After Last Page Fix от Белотицкого Юрия. Скачать можно . Установка в один клик, настроек нет. Скрипт вместо создания множества дублированных документов отдает 404-ошибку. На мой взгляд, самый удачный вариант. Недостатки:
- плагин добавляет дубль rel="canonical";
- и shortlink.
2) Дополнительная настройка All in One SEO Pack. Разработчики этого плагина, скорее всего, оказались в курсе данного бага и в новых версиях появились дополнительные чекбоксы.

Несуществующие записи будут создаваться, но в них будет указан мета-тег robots, запрещающий их индексирование.
В других SEO-плагинах для wordpress не смотрел. Вероятно, в Yoast SEO или подобных будут такие же настройки. UPD . Да, действительно, в плагине от Yoast прописывается каноникал на основную запись.
Вот и все ! Баг достаточно серьезный, но исправляется, можно сказать, в один клик. Вам остается проверить, создаются ли у вас подобные страницы. Если да, то выбрать один из вариантов решения проблемы.
Получается, что, обновляясь на новую версию wordpress, не только устраняешь старые ошибки CMS, но можешь и получить новые. Интересно, какая у вас версия движка и создаются ли такие несуществующие посты? Поделитесь статистикой в комментариях .
Доброго времени суток!
Дубликаты страниц , или дубли — одна из тех проблем, о которой не подозревают многие вебмастера. Из-за такой ошибки, некоторые полезные WordPress-блоги теряют позиции по ряду запросов, и порою их владельцы даже не догадываются об этом. Каждый видит в статистике, что посещаемость веб-страницы упала, но разыскать и исправить ошибку могут не все. В этой статье пойдет речь о том, как найти дубли страниц сайта.
Что такое дубликаты страниц?
Дубли – это две и больше страниц с одинаковым контентом, но разными адресами. Существует понятие полных и частичных дублей. Если полные — это стопроцентный дублированный контент исходной (канонической ) страницы, то частичным дублем может стать страница, повторяющая ее отдельные элементы. Причины появления дублей могут быть разными. Это могут быть ошибки вебмастера при составлении или изменении шаблона сайта. Но чаще всего дубли возникают автоматически из-за специфики работы движков, таких как WordPress и Joomla. О том, почему это происходит, и как с этим справляться я расскажу ниже. Очень важно понимать, что вебсайты с такими повторениями могут попасть под и понижаться в выдаче, поэтому дублей стоит избегать.
Как проверить сайт на дубли страниц?
Практика показывает, что отечественный поисковик Яндекс относится к дублям не так строго, как зарубежный Гугл. Однако и он не оставляет такие ошибки вебмастеров без внимания, поэтому для начала нужно разобраться с тем, как найти дубликаты страниц.
Во-первых, нам нужно определить, какое количество страниц нашего сайта находится в индексе поисковых систем. Для этого воспользуемся функцией site:my-site.ru, где вместо my-site.ru вам нужно подставить свой url. Покажу, как это работает на примере своего блога. Начнем с Яндекса. Вводим в строку поиска site:сайт

Как видим, Яндекс нашел 196 проиндексированных страниц. Теперь проделаем то же самое с Google.

Мы получили 1400 страниц в общем индексе Гугл. Кроме основных страниц, участвующих в ранжировании, сюда попадают так называемые «сопли». Это дубли, либо малозначимые страницы. Чтобы проверить основной индекс в Google, нужно ввести другой оператор: site:сайт/&

Итого в основном индексе 165 страниц. Как видим, у моего блога есть проблема с количеством дублей. Чтобы их увидеть, нужно перейти на последнюю страницу общей выдачи и нажать «показать скрытые результаты ».

Снова перейдя в конец выдачи, вы увидите примерно такое:

Это и есть те самые дубли, в данном случае replycom . Такой тип дублей в WordPress создается при появлении комментариев на странице. Есть множество разных видов дублей, их названия и способы борьбы с ними, будут описаны в следующей статье.
Наверняка у вас возник вопрос, почему в Яндексе мы не увидели такого количества дублей, как в Google. Все дело в том, что в файле robots.txt (кто не знает что это, читайте « ») на блоге стоит запрет на индексацию подобных дублей с помощью директивы Disallow (подробнее об этом в следующем посте). Для Яндекса этого достаточно, но Гугл работает по своим алгоритмам и все равно учитывает эти страницы. Но их контент он не показывает, говорит, что «Описание веб-страницы недоступно из-за ограничений в файле robots.txt».
Проверка на дубли страниц по отрывку текста, по категориям дублей
Кроме вышеописанного способа, вы можете проверять отдельные страницы сайта на наличие дублей. Для этого в окне поиска Яндекс и Google, можно указать отрывок текста страницы, после которого употребить все тот же site:my-site.ru. Например, такой текст с одной из моих страничек: «Eye Dropper - это дополнение позволяет быстро узнать цвет элемента, чем-то напоминает пипетку в Photoshop». Его вставляем в поиск Гугл, а после через пробел site:my-site

Google не нашел дублей это страницы. Для Яндекса проделываем то же самое, только текст страницы берем в кавычки «».
Кроме фрагментов текста, вы можете вставлять ключевые фразы, по которым, к примеру, у вас снизились позиции.
Есть другой вариант такой же проверки через расширенный поиск. Для Яндекса — yandex.ru/advanced.html .
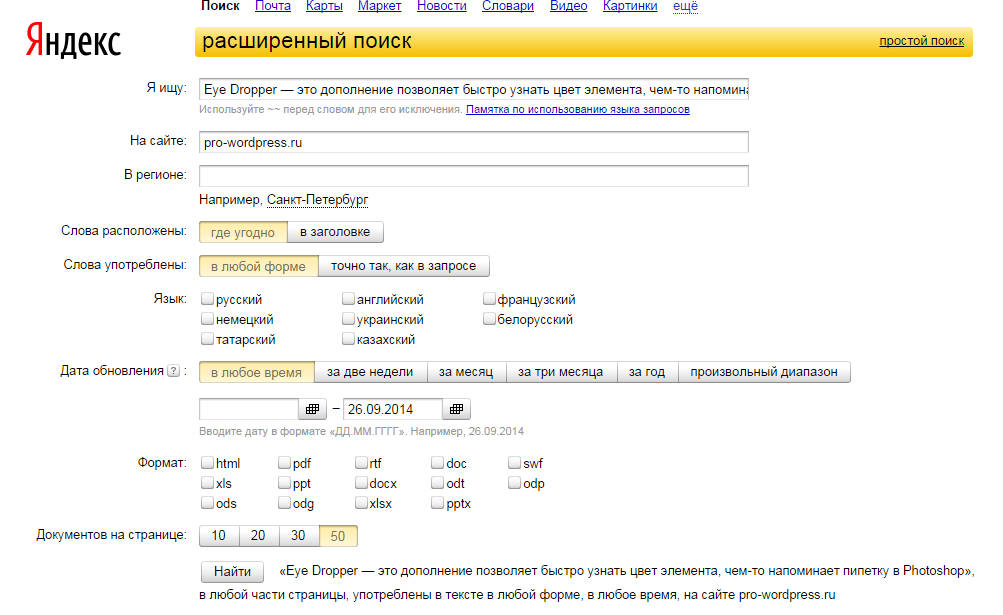
Вводим тот же текст, url сайта и жмем «Найти ». Получим такой же результат, как и с оператором site:my-site .
Либо такой поиск можно осуществить, нажав кнопку настроек в правой части окна Яндекс.
Для Гугла есть такая же функция расширенного поиска.

Теперь посмотрим, как можно выявить группу дублей одной категории. Возьмем, к примеру, группу tag.

И увидим на странице выдачи по данному запросу следующее:

А если попросить Гугл вывести скрытые результаты, дублей группы tag станет больше.
Как вы успели заметить, дубликатов страниц создается очень много и наша задача – предотвратить их попадание в индекс поисковиков.
Поиск дублей страниц сайта: дополнительные способы
Кроме ручных способов, есть также возможность автоматически проверить сайт на дубли страниц.
Например, это программа Xenu , предназначенная для технического аудита сайта. Кроме дубликатов страниц, она выявляет . Это не единственная программа для решения таких задач, но наиболее распространенная.
Также в поиске дублей страниц помогает Google Webmaster, здесь можно выявить страницы с повторяющимися мета-тегами:

Тут вы посмотрите список урлов с одинаковыми тайтлами или описанием. Часть из них может оказаться дублями.
На сегодня все. Теперь вы знаете, как найти дубликаты страниц. В мы подробно разберем, как предотвратить их появление и удалить имеющиеся дубли.
Страницы с одинаковыми адресами – это распространенная техническая проблема, которая довольно таки серьезно может негативно повлиять на поисковую выдачу Вашего сайта в поисковых системах.
Что такое дубли страниц?
Причин появления дублей на сайте может быть несколько: если страница имеет несколько подстраниц, присутствие комментариев (особенно если для них активна функция постраничного отображения или древовидный вид), прикрепленные картинки, начилие календаря в сайдбаре, и др.
Как удалить дубли?
Наиболее простой и универсальный способ – использовать плагины, которые корректно и безболезненно решают данную проблему.
Удаляем дубли страниц в комментариях
Присутствие кнопки “Ответить ” в блоке комментариев порождает самый злосчастный вид дублей – replytocom. К примеру, если в одной статье 50 раз нажмут на “Ответить ” и оставят свой комментарий, то на сайте будет присутствовать 50 дублей этой статьи. Чтобы обезопасить Ваш сайт от подобной беды, необходимо в админ-панели перейти Настройки -> Обсуждение и убрать галочки напротив пунктов Разрешить древовидные (вложенные) комментарии глубиной и Разбивать комментарии верхнего уровня на страницы по .
Используем плагин Yoast SEO
После установки и активации плагина Yoast SEO в админ-панели необходимо перейти SEO -> Возможности , в разделе Дополнительные настройки страницы перетянуть ползунок в состояние Включено и нажать кнопку Сохранить изменения . У Вас в разделе SEO появятся новые подменю, из которых нужно выбрать Дополнительно -> Постоянные ссылки . На этой вкладке необходимо поставить ползунки в положения, согласно рисунку ниже:

Для вступления изменений в силу следует нажать кнопку Сохранить изменения .
Если Вы используете плагин , то для удаления дублей страниц необходимо в админ-панели перейти Clearfy -> Основные -> Дубли страниц и отметить все пункты меню в этом окне.
Всех приветствую! Сегодня я вам расскажу как добавить мета тег (noindex, pofollow) и как избавиться от дублей страниц в Вордпресс. Вы же не ждете той минуты, когда вам вдруг скажут, что ваш блог обречен и его ждет провал? Тогда читайте пост очень внимательно.
C проблемой дублей я столкнулась сама, когда на моем блоге количество статей перевалило за цифру 10. На блоге стали появляться дубли страниц. Чтобы проверить свой блог на дубли, зайдите в аддурилку Гугл в раздел «Оптимизация HTML».

Это сейчас у меня (смотрите скриншот) два повторяющихся заголовка, потому что я не так давно изменила адрес поста. О том как его изменить можно прочитать в разделе «Дополнительные возможности». В то время когда я забила тревогу у меня было 11 дублей, а потом и 15.
В панике я отправилась на поиски необходимой информации и нашла много советов. Вот один из них: в файле robots.txt пропишите строку — Disallow: /page/ и с этого момента будет индексироваться только главная страница с анонсами статей. Стоит ли закрывать pade в ? Этот вопрос волнует многих и обсуждается на форумах.

Не буду однозначно говорить о том, что этот метод хорош или о том, что этот метод бесполезен. Скажу одно — мне он не помог. Даже после того, как я прописала в robots.txt строку запрещающую индексирование page, количество записей с одинаковыми заголовками только прибавлялись.
Дело все в GOOGLE! Он не обращает внимание на запреты в файле robots.
Чем больше статей вы публикуете, тем больше дублей главных страниц у вас будет.

За дубли страниц поисковые системы нас рано или поздно накажут, поэтому приступим к закрытию подстраниц архивов в noindex.
Вот такую строчку нам надо будет прописать.
Чтобы разместить данный тег можно воспользоваться двумя способами.
Первый способ
Воспользуемся помощью плагина WordPress Seo by Yoast, о том как его установить и настроить я писала . Сейчас я вам напомню, о чем шла речь в моей статье.
Для этого переходим в админку сайта в раздел «SEO» — «Заголовки и метаданные», переходим на вкладку «Остальное» и видим, что у нас стоит галочка напротив Noindex для подстраниц и архивов.

Если мы уберем эту галочку, почистим и перейдем на вторую страницу нашего блога, то в коде страницы увидим, что мета тег pofollow исчез и остался только на ссылках. Если мы снова поставим галочку, то увидим, что мета тег появился снова.
Существует еще один способ и сейчас мы его с вами рассмотрим.
Для тех кто использует другой плагин для seo — оптимизации, можно воспользоваться вторым способом.
Второй способ
Сейчас нам необходимо скопировать код:
function my_meta_noindex () {
if (is_paged()){
echo «».».»\n»;
}
}add_action(‘wp_head’, ‘my_meta_noindex’, 3);
По FTP подключаемся к серверу и в папке с вашей темой находим файл functions.php. Вставляем скопированный тег в свободное место.
Если мы сейчас отключим галочку в плагине WordPress Seo by Yoast, почистим кэш и просмотрим код второй страницы, то данный код отобразится в заголовке нашего сайта.
Я предпочитаю, чтобы все настройки моего блога находились в одном месте, поэтому этот код я удаляю, а буду закрывать подстраницы архивов первым способом с помощью плагина.
Бейте тревогу, если на вашем сайте всего 20-30 статей, а в индексе более двухсот. Скорее всего у вас есть дубли. У меня сейчас нет желания продать вам какой-то инфопродукт или похвалиться своими достижениями. Сегодня моя цель рассказать вам о важных моментах сайтостроительства.
Воспользуйтесь одним из выше перечисленных способов и в скором будущем, если у вас есть дубли главной страницы, количество проиндексированных страниц будет намного меньше. В этом случае такой спад только к лучшему.
Воспользуйтесь советами и забудьте про дубли, не забывайте закрывать от индексации. Чтобы подписаться на обновление перейдите по . Анекдот сегодня будет в видеоформате. До скорых встреч! .
Анекдот: