Построение регрессии в excel. Регрессия в Excel: уравнение, примеры. Линейная регрессия
На мой взгляд, как студента, эконометрика – это одна из самых прикладных наук из всех, с которыми мне удалось познакомиться в стенах своего университета. С помощью неё, действительно, можно решать задачи прикладного характера в масштабах предприятия. Насколько эффективными будут эти решения – вопрос третий. Суть в том, что большая часть знаний так и останется теорией, а вот эконометрика и регрессионный анализ всё-таки стоит изучить с особым вниманием.
Что объясняет регрессия?
Прежде, чем мы приступим к рассмотрению функций MS Excel, позволяющих, решать данные задачи, хотелось бы вам на пальцах объяснить, что, в сущности, предполагает регрессионный анализ. Так вам проще будет сдавать экзамен, а самое главное, интересней изучать предмет.
Будем надеяться, вы знакомы с понятием функции из математики. Функция – это взаимосвязь двух переменных. При изменении одной переменной что-то происходит с другой. Изменяем X, меняется и Y, соответственно. Функциями описываются различные законы. Зная функцию, мы можем подставлять произвольные значения X и смотреть на то, как при этом изменится Y.
Это имеет большое значение, поскольку регрессия – это попытка объяснить с помощью определённой функции на первый взгляд бессистемные и хаотичные процессы. Так, например, можно выявить взаимосвязь курса доллара и безработицы в России.
Если данную закономерность обнаружить удастся, то по полученной нами в ходе расчетов функции, мы сможем составить прогноз, какой будет уровень безработицы при N-ом курсе доллара по отношению к рублю.
Данная взаимосвязь будет называться корреляцией. Регрессионный анализ предполагает расчет коэффициента корреляции, который объяснит тесноту связи между рассматриваемыми нами переменными (курсом доллара и числом рабочих мест).
Данный коэффициент может быть положительным и отрицательным. Его значения находятся в пределах от -1 до 1. Соответственно, мы может наблюдать высокую отрицательную или положительную корреляцию. Если она положительная, то за увеличением курса доллара последует и появление новых рабочих мест. Если она отрицательная, значит, за увеличением курса, последует уменьшение рабочих мест.
Регрессия бывает нескольких видов. Она может быть линейной, параболической, степенной, экспоненциальной и т.д. Выбор модели мы делаем в зависимости от того, какая регрессия будет соответствовать конкретно нашему случаю, какая модель будет максимально близка к нашей корреляции. Рассмотрим это на примере задачи и решим её в MS Excel.
Линейная регрессия в MS Excel
Для решения задач линейной регрессии вам понадобится функционал «Анализ данных». Он может быть не включен у вас поэтому его нужно активировать.
- Жмём на кнопку «Файл»;
- Выбираем пункт «Параметры»;
- Жмём по предпоследней вкладке «Надстройки» с левой стороны;

- Снизу увидим Надпись «Управление» и кнопку «Перейти». Жмём по ней;
- Ставим галочку на «Пакет анализа»;
- Жмём «ок».

Пример задачи
Функция пакетного анализа активирована. Решим следующую задачу. У нас есть выборка данных за несколько лет о числе ЧП на территории предприятия и количестве трудоустроенных работников. Нам необходимо выявить взаимосвязь между этими двумя переменными. Есть объясняющая переменная X – это число рабочих и объясняемая переменная – Y – это число чрезвычайных происшествий. Распределим исходные данные в два столбца.

Перейдём во вкладку «данные» и выберем «Анализ данных»
В появившемся списке выбираем «Регрессия». Во входных интервалах Y и X выбираем соответствующие значения.
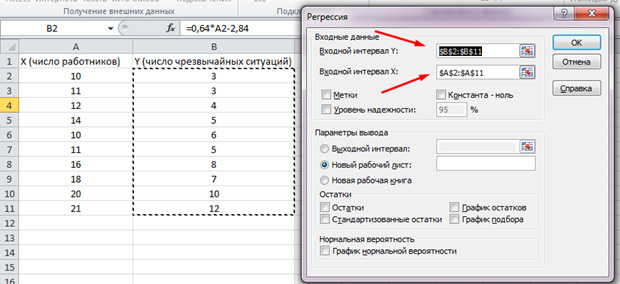
Нажимаем «Ок». Анализ произведён, и в новом листе мы увидим результаты.
Наиболее существенные для нас значения отмечены на рисунке ниже.

Множественный R – это коэффициент детерминации. Он имеет сложную формулу расчета и показывает, насколько можно доверять нашему коэффициенту корреляции. Соответственно, чем больше это значение, тем больше доверия, тем удачнее наша модель в целом.
Y-пересечение и Пересечение X1 – это коэффициенты нашей регрессии. Как уже было сказано, регрессия – это функция, и у неё есть определённые коэффициенты. Таким образом, наша функция будет иметь вид: Y = 0,64*X-2,84.
Что нам это даёт? Это даёт нам возможность составить прогноз. Допустим, мы хотим нанять на предприятие 25 работников и нам нужно примерно представить, каким при этом будет количество чрезвычайных происшествий. Подставляем в нашу функцию данное значение и получаем результат Y = 0,64 * 25 – 2,84. Примерно 13 ЧП у нас будет происходить.
Посмотрим, как это работает. Взгляните на рисунок ниже. В полученную нами функцию подставлены фактические значения по вовлеченным работникам. Посмотрите, как близки значения к реальным игрекам.

Вы так же можете построить поле корреляции, выделив область игреков и иксов, нажав на вкладку «вставку» и выбрав точечную диаграмму.

Точки идут вразброс, но в целом двигаются вверх, как будто посередине лежит прямая линия. И эту линию вы так же можете добавить, перейдя во вкладку «Макет» в MS Excel и выбрав пункт «Линия тренда»
Щелкните дважды по появившейся линии и увидите то, о чем говорилось ранее. Вы можете изменять тип регрессии в зависимости от того, как выглядит ваше поле корреляции.
Возможно, вам покажется, что точки рисуют параболу, а не прямую линию и вам целесообразней выбрать другой тип регрессии.

Заключение
Будем надеяться, что данная статья дала вам большее понимание о том, что такое регрессионный анализ и для чего он нужен. Всё это имеет большое прикладное значение.
Регрессионный анализ является одним из самых востребованных методов статистического исследования. С его помощью можно установить степень влияния независимых величин на зависимую переменную. В функционале Microsoft Excel имеются инструменты, предназначенные для проведения подобного вида анализа. Давайте разберем, что они собой представляют и как ими пользоваться.
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.


Теперь, когда мы перейдем во вкладку «Данные» , на ленте в блоке инструментов «Анализ» мы увидим новую кнопку – «Анализ данных» .

Виды регрессионного анализа
Существует несколько видов регрессий:
- параболическая;
- степенная;
- логарифмическая;
- экспоненциальная;
- показательная;
- гиперболическая;
- линейная регрессия.
О выполнении последнего вида регрессионного анализа в Экселе мы подробнее поговорим далее.
Линейная регрессия в программе Excel
Внизу, в качестве примера, представлена таблица, в которой указана среднесуточная температура воздуха на улице, и количество покупателей магазина за соответствующий рабочий день. Давайте выясним при помощи регрессионного анализа, как именно погодные условия в виде температуры воздуха могут повлиять на посещаемость торгового заведения.
Общее уравнение регрессии линейного вида выглядит следующим образом: У = а0 + а1х1 +…+акхк. В этой формуле Y означает переменную, влияние факторов на которую мы пытаемся изучить. В нашем случае, это количество покупателей. Значение x – это различные факторы, влияющие на переменную. Параметры a являются коэффициентами регрессии. То есть, именно они определяют значимость того или иного фактора. Индекс k обозначает общее количество этих самых факторов.


Разбор результатов анализа
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.

Одним из основных показателей является R-квадрат . В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты» . Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Это наиболее распространенный способ показать зависимость какой-то переменной от других, например, как зависит уровень ВВП от величины иностранных инвестиций или от кредитной ставки Нацбанка или от цен на ключевые энергоресурсы .
Моделирование позволяет показать величину этой зависимости (коефициенты), благодаря которым можно делать непосредственно прогноз и осуществлять какое-то планирование, опираясь на эти прогнозы. Также, опираясь на регрессионный анализ, можно принимать управленческие решения направленные на стимулирование приоритетных причин влияющих на конечный результат, собственно модель и поможет выделить эти приоритетные факторы.
Общий вид модели линейной регрессии:
Y=a 0 +a 1 x 1 +...+a k x k
где a - параметры (коэффициенты) регрессии, x - влияющие факторы, k - количество факторов модели.
Исходные данные
Среди исходных данных нам необходим некий набор данных, который бы представлял из себя несколько последовательных или связанных между собой величин итогового параметра Y (например, ВВП) и такое же количество величин показателей, влияние которых мы изучаем (например, иностранные инвестиции).
На рисунке выше показана таблица с этими самыми исходными данными, в качестве Y выступает показатель экономически активного населения, а количество предприятий, размер инвестиций в капитал и доходов населения - это влияющие факторы, то бишь иксы.
По рисунку также можно сделать ошибочный вывод, что речь в моделировании может идти только о динамических рядах, то есть моментным рядам зафиксированных последовательно во времени, но это не так, с тем же успехом можно моделировать и в разрезе структуры, например, величины указанные в таблице могут быть разбиты не годам, а по областям.
Для построения адекватных линейных моделей желательно чтобы исходные данные не имели сильных перепадов или обвалов, в таких случаях желательно проводить сглаживание, но о сглаживании поговорим в следующий раз.
Пакет анализа
Параметры модели линейной регрессии можно рассчитать и вручную с помощью Метода наименьших квадратов (МНК), но это довольно затратно по времени. Немного быстрее это можно посчитать по этому же методу с помощью применения формул в Excel, где сами вычисления будет делать программа, но проставлять формулы все равно придется вручную.
В Excel есть надстройка Пакет анализа , который является довольно мощным инструментом в помощь аналитику. Этот инструментарий, помимо всего прочего, умеет рассчитывать параметры регрессии, по тому же МНК, всего в несколько кликов, собственно, о том как этим инструментом пользоваться дальше и пойдет речь.
Активируем Пакет анализа
По умолчанию эта надстройка отключена и в меню вкладок вы ее не найдете, поэтому пошагово рассмотрим как ее активировать.

В эксель, слева вверху, активируем вкладку Файл , в открывшемся меню ищем пункт Параметры и кликаем на него.

В открывшемся окне, слева, ищем пункт Надстройки и активируем его, в этой вкладке внизу будет выпадающий список управления, где по умолчанию будет написано Надстройки Excel , справа от выпадающего списка будет кнопка Перейти , на нее и нужно нажать.

Всплывающее окошко предложит выбрать доступные надстройки, в нем необходимо поставить галочку напротив Пакет анализа и заодно, на всякий случай, Поиск решения (тоже полезная штука), а затем подтвердить выбор кликнув по кнопочке ОК .
Инструкция по поиску параметров линейной регрессии с помощью Пакета анализа
После активации надстройки Пакета анализа она будет всегда доступна во вкладке главного меню Данные под ссылкой Анализ данных
В активном окошке инструмента Анализа данных из списка возможностей ищем и выбираем Регрессия

Далее откроется окошко для настройки и выбора исходных данных для вычисления параметров регрессионной модели. Здесь нужно указать интервалы исходных данных, а именно описываемого параметра (Y) и влияющих на него факторов (Х), как это на рисунке ниже, остальные параметры, в принципе, необязательны к настройке.

После того как выбрали исходные данные и нажали кнопочку ОК, Excel выдает расчеты на новом листе активной книги (если в настройках не было выставлено иначе), эти расчеты имеют следующий вид:

Ключевые ячейки залил желтым цветом именно на них нужно обращать внимание в первую очередь, остальные параметры значимость также немаловажны, но их детальный разбор требует пожалуй отдельного поста.
Итак, 0,865 - это R 2 - коэффициент детерминации, показывающий что на 86,5% расчетные параметры модели, то есть сама модель, объясняют зависимость и изменения изучаемого параметра - Y от исследуемых факторов - иксов . Если утрировано, то это показатель качества модели и чем он выше тем лучше. Понятное дело, что он не может быть больше 1 и считается неплохо, когда R 2 выше 0,8, а если меньше 0,5, то резонность такой модели можно смело ставить под большой вопрос.
Теперь перейдем к коэффициентам модели
:
2079,85
- это a 0
- коэффициент который показывает какой будет Y в случае, если все используемые в модели факторы будут равны 0, подразумевается что это зависимость от других неописанных в модели факторов;
-0,0056
- a 1
- коэффициент, который показывает весомость влияния фактора x 1 на Y, то есть количество предприятий в пределах данной модели влияет на показатель экономически активного населения с весом всего -0,0056 (довольно маленькая степень влияния). Знак минус показывает что это влияние отрицательно, то есть чем больше предприятий, тем меньше экономически активного населения, как бы это ни было парадоксальным по смыслу;
-0,0026
- a 2
- коэффициент влияния объема инвестиций в капитал на величину экономически активного населения, согласно модели, это влияние также отрицательно;
0,0028
- a 3
- коэффициент влияния доходов населения на величину экономически активного населения, здесь влияние позитивное, то есть согласно модели увеличение доходов будет способствовать увеличению величины экономически активного населения.
Соберем рассчитанные коэффициенты в модель:
Y = 2079,85 - 0,0056x 1 - 0,0026x 2 + 0,0028x 3
Собственно, это и есть линейная регрессионная модель, которая для исходных данных, используемых в примере, выглядит именно так.
Расчетные значения модели и прогноз
Как мы уже обсуждали выше, модель строится не только чтобы показать величину зависимостей изучаемого параметра от влияющих факторов, но и чтобы зная эти влияющие факторы можно было делать прогноз. Сделать этот прогноз довольно просто, нужно просто подставить значения влияющих факторов в место соответствующих иксов в полученное уравнение модели. На рисунке ниже эти расчеты сделаны в экселе в отдельном столбце.

Фактические значения (те что имели место в реальности) и расчетные значения по модели на этом же рисунке отображены в виде графиков, чтобы показать разность, а значит погрешность модели.
Повторюсь еще раз, для того чтобы сделать прогноз по модели нужно чтобы были известные влияющие факторы, а если речь идет о временном ряде и соответственно прогнозе на будущее, например, на следующий год или месяц, то далеко не всегда можно узнать какие будут влияющие факторы в этом самом будущем. В таких случаях, нужно еще делать прогноз и для влияющих факторов, чаще всего это делают с помощью авторегрессионной модели - модели, в которой влияющими факторами являются сам исследуемый объект и время, то есть моделируется зависимость показателя от того каким он был в прошлом.
Как строить авторегрессионную модель рассмотрим в следующей статье, а сейчас предположим, что, то какие будут величины влияющих факторов в будущем периоде (в примере 2008 год) нам известно, подставляя эти значения в расчеты мы получим наш прогноз на 2008 год.
Пакет MS Excel позволяет при построении уравнения линейной регрессии большую часть работы сделать очень быстро. Важно понять, как интерпретировать полученные результаты. Для построения модели регрессии необходимо выбрать пункт Сервис\Анализ данных\Регрессия (в Excel 2007 этот режим находится в блоке Данные/Анализ данных/Регрессия). Затем полученные результаты скопировать в блок для анализа.
