SEO-блог Сергея Людкевича. Что такое непот фильтр и как его избежать? Непот фильтр яндекса
(если быть точнее, то это платное наращивание ссылочной массы). Любые массовые работы, позволяющие искусственно повышать позиции сайта в поисковой выдаче, оказывают не самое лучшее воздействие на ранжирование . Ввиду этого разработчиками Яндекса предпринимаются специальные меры борьбы с данным инструментом продвижения. Именно такой мерой является наложение непот-фильтра, который позволяет не принимать во внимание ссылки с определенных доноров при подсчете уровня релевантности веб-документа.
Итак,непот представляет собой фильтр поисковой системы Yandex , который был специально создан для того, чтобы уменьшать влияние SEO-ссылок на на результаты поисковой выдачи. Наложение непота может быть вызвано нарушением лицензии на использование Яндекса (пункт 3.5. "Поисковый спам").
Под данный фильтр попадают те ресурсы, которые слишком много и, как правило, не моделируемо продают ссылочные места на своих страницах.
Известно две версии Непот-фильтра:
- версия 1.0 – для обнаружения некачественных ссылок и последующего снижения их веса;
- версия 2.0 – это обновленная версия 1.0 с добавлением новых критериев выявления плохих по качеству ссылок. К примеру, частота изменения ссылок с одной страницы, их положение на ней, число и качество и пр.
Факторы попадания под Непот-фильтр
Все возможные факторы известны лишь самому поисковику Яндекс, однако некоторые отличительные особенности все-таки можно определить:
- число ссылок различного вида и их расположение на странице;
- частая смена ссылок;
- тема ссылок и самого сайта-донора;
- практически полное отсутствие между ссылками контента .
Как выбраться из-под действия фильтра?
Как только будут устранены ошибки в сайте (неестественные ссылки будут удалены или изменено их положение), фильтр автоматически исчезнет. Другой способ – написать службе поддержки Yandex, чтобы вам сняли непот, если автоматического снятия его не произошло.
Оформление блока ссылок
Важно, чтобы продажные ссылки не отличались от естественных . Это можно сделать, основываясь на следующем:
- поддержание одинаковой тематики ссылок и сайта;
- один блок не может содержать свыше пяти ссылок;
- блоки следует размещать в основной части веб-страницы;
- между ссылками обязательно ставятся разделительные знаки или текст;
- ссылки не должны сливаться с фоном веб-страницы, поэтому их следует выделять другим цветом;
- чем меньше будет ссылок, тем лучше.
Непот-фильтр накладывается на сайты-доноры, однако

Непот-фильтр – это уже порядком позабытый термин из 2000-х годов. Строго говоря, непот-фильтр – это механизм полного неучета или частичного понижения вклада ссылки в ссылочные факторы ранжирования для акцептора.
Но название это приклеилось к конкретному явлению, наблюдавшемуся в поисковой выдаче Яндекса до февраля 2008 года. Заключалось оно в том, что в ряде случаев страница-акцептор не находилась в поисковой выдаче по тексту ссылки, ведущей на неё, несмотря на то, что эта ссылка была проиндексирована на странице-доноре. То есть, страница-донор по тексту ссылки находилась, а вот страница-акцептор – нет. В таких случаях и делался вывод о неучете данной ссылки в ранжировании. Исследования тех лет показывали, что накладывался данный фильтр на кластер (совокупность страниц, обладающих некими общими свойствами) сайта-донора. Например, имели место случаи, когда фильтровались ссылки только с главной страницы сайта-донора или только из каталога обменных ссылок, расположенного на нем, а со всех других страниц этого сайта – нет.
С мая 2014-го по октябрь 2015-го года в Яндексе наблюдалось явление, очень похожее на тот старый классический непот-фильтр. Назовем это новое явление «непот-фильтром-2014». О нем я писал в статье « » и последующей серии статей о методике определения отключения ссылочного ранжирования по запросу ( , ). Явление это обнаружилось после объявления сотрудниками Яндекса в апреле 2014 года о полном отключении ссылочных факторов в ряде тематик московской выдачи Яндекса и обладало аналогичными непот-фильтру основными свойствами – страница-акцептор не находилась по тексту проиндексированной ссылки. Только вот явление это было довольно ограниченным. Во-первых, запросозависимым (наблюдалось только для некоторых коммерческих запросов). Во-вторых, регионозависимым (наблюдалось только в выдаче для Москвы). А, в-третьих, имела место и зависимость от наличия сохраненной ссылки – для документов без сохраненной копии данное явление не наблюдалось ни при каких условиях.
3 ноября 2015 года, во время своего доклада «Плохие методы продвижения сайтов», читаемого в рамках Школы вебмастеров Яндекса, аналитик отдела безопасного поиска Яндекса Екатерина Гладких объявила о возвращении учета ссылочных факторов, тех самых, отключенных для ряда коммерческих тематик в московской выдаче в апреле 2014 года. Индустрия ссылкоторговли поспешила водрузить этот факт на свой рекламный щит, пропагандируя мысль, что Яндекс «включил заднюю передачу» и все ссылки опять заработали. Скромно умалчивая о том, что на эти «возвращенные» ссылки также распространяется новая, «минусинская» ссылочная концепция Яндекса, заключающаяся в полном неучете так называемых SEO-ссылок.
Тем временем, явления, присущие «непот-фильтру 2014», в поисковой выдаче прекратились, но им на смену пришли новые, уже гораздо больше напоминающие старый классический непот-фильтр 2000-х годов. А именно: отсутствие страницы-акцептора в поисковой выдаче по тексту проиндексированной ссылки, ведущей на него, уже не зависящее от запроса, региона и наличия сохраненной копии. Именно это явление некоторые SEO-специалисты и окрестили «возвращением непот-фильтра». Мы же назовем его «непот-фильтром-2015».
На данный момент существует достаточно простой способ определения непот-фильтра-2015, однако, ограниченный в использовании только лишь для страниц-акцепторов, не содержащих проверяемую фразу в тексте, т.е. имеющих для нее нулевую текстовую релевантность. Данная методика заключается в проверке наличия разных результатов при разном построении запроса с использованием оператора << («неранжирующее И») для поиска на странице по анкору проверяемой ссылки. Вот так акцептор находится:

А вот так (поменяв местами правую и левую части запроса относительно оператора <<) – нет:

С помощью недокументированных операторов inlink: и intext: (о них я рассказывал в своих статьях « » и « » удостоверимся, что искомая фраза действительно находится в тексте ссылок на документ:


Небольшая справка. Оператор inlink: осуществляет поиск только по анкор-файлу. Обнуляет значения текстовых динамических (т.е. зависящих от запроса) факторов. К сожалению, он работает только справа от оператора << («неранжирующее И»). Оператор intext: осуществляет поиск только по тексту. Он обнуляет значения ссылочных динамических факторов. Работает полноценно.
Интересная особенность непот-фильтра 2015 заключается в том, что он накладывается на конкретную ссылку. Так, например, наблюдаются случаи, когда из разных ссылок на внешний сайт, расположенных на одной странице-доноре, одни попадают под фильтр, а другие – нет. Также пока не обнаружено случаев попадания под этот фильтр внутренних ссылок.
Наблюдая свойства нового непот-фильтра, во многом аналогичные старому классическому, возникает соблазн интерпретировать его действие также по аналогии — как полное обнуление ссылочных факторов. В случае, когда текстовая релевантность страницы-акцептора поисковой фразе нулевая, это, в общем-то не вызывает сомнения – ведь акцептор просто не находится по ссылке. Но хотелось бы проверить эту гипотезу и для случая, когда текстовая релевантность акцептора не равна нулю. К сожалению, вышеупомянутая простая методика тут уже не может помочь. В этой задаче мог бы помочь оператор inlink: , если б он работал и слева от оператора << , но, увы, его использование имеет неприятные ограничения. Однако существует возможность специальным образом сконструировать альтернативный запрос для поиска по анкор-файлу. Причем, используя только документированные операторы языка запросов Яндекса, что не накладывает никаких ограничений на его использование. К сожалению, я пока не могу опубликовать этот запрос из-за опасений за его дальнейшую работоспособность, поэтому назову его «секретным запросом» и попрошу читателя поверить мне на слово в том, что он действительно существует.
В пользу того, что этот запрос действительно является аналогом оператора inlink: , свидетельствуют следующие факты:
- Логика построения запроса, учитывающая специфические особенности организации анкор-файла.
- Аналогичные результаты поисковой выдачи при использовании справа его от оператора << («неранжирующее И»).
- Корректность получаемых с его помощью результатов, при определении непот-фильтра-2015 для документов с нулевой текстовой релевантностью запросу.
На основании этих фактов логично предположить, что «секретный запрос» также корректно определяет наличие непот-фильтра-2015 и для документов с ненулевой текстовой релевантностью запросу.
Для проверки гипотезы о полном обнулении непот-фильтром-2015 динамических ссылочных факторов для документов с ненулевой текстовой релевантностью я буду использовать метод «ортогональных запросов», о котором я писал в своей статье « ». Суть его заключается в том, чтобы сконструировать запрос, состоящий из двух частей, разделяемых оператором | («логическое ИЛИ»). По одну сторону от оператора будем использовать выдачу, состоящую из одного результата для «контрольного документа», по другую сторону будет формироваться своеобразная «линейка» из многих результатов. Таким образом, измеряя позицию контрольного документа в общей выдаче по «линейке», мы сможем делать определенные выводы об изменении численного значения его релевантности запросу из первой части.
Итак, гипотеза следующая. Если динамические ссылочные факторы, в случае срабатывания непот-фильтра-2015 для документов с ненулевой текстовой релевантностью, действительно полностью обнуляются, то позиции в «ортогональной» выдаче для контрольного документа по базовому запросу и по запросу с использованием оператора intext: будут совпадать. Убедимся, что именно так и происходит для документа с нулевой ссылочной релевантностью запросу (т.е. не имеющего входящих ссылок с анкорами, содержащими текст запроса). Найдем подходящий документ c ненулевой текстовой релевантностью и нулевой ссылочной (контрольный документ #1):


«Взвесим» по ортогональной сетке варианты с базовым запросом и оператором intext: (отдельно подчеркиваю важность построения стабильной сетки, в которой не меняются позиции документов при изменении второй части запроса). Для данного случая получаем одинаковые результаты:


Теперь найдем документ (контрольный документ #2) с ненулевой текстовой релевантностью, имеющий вхождение запроса в анкор-лист, но попадающий под непот-фильтр-2015 согласно выдаче по «секретному запросу»:



И таким же образом пробиваем варианты выдачи для базового запроса и примененного к нему оператора intext: по ортогональной сетке. Обнаруживаем, что контрольный документ #2 по запросу с оператором intext: находится ниже, чем по базовому:


Таким образом, гипотеза о полном обнулении ссылочных динамических факторов для случая ненулевой текстовой релевантности запросу не подтверждается.
То есть, к сожалению, мы не можем с уверенностью утверждать о том, что попадающие под непот-фильтр-2015 ссылки не учитываются полностью. Вариантов здесь может быть масса:
- Учитывается пусть не ноль, но практически не значащая величина, мизер.
- Наблюдаемое явление – какой-то странный артефакт, по наличию которого нельзя сделать никаких практических выводов о природе учета оцениваемых ссылок. Тогда, естественно, возникает следующий вопрос – почему этот артефакт возник и есть ли в его существовании хоть какая-то логика?
- Используемая методика определения наличия нулевого ссылочного веса на самом деле некорректна и дает ничего не значащий результат. Надо искать более совершенную методику.
- И т.д. и т.п.
В общем, пока что вопросов сильно больше, чем ответов. Что ж, будем их искать. Ведь надежда на возвращение столь простой возможности оценки работоспособности ссылок, как старый классический непот-фильтр, ну, очень соблазнительна.
Что такое непот-фильтр?
Основным из элементов сео-продвижения сайтов является покупка ссылок (а точнее, платное размещение ссылок на других ресурсах). А, как известно, любые работы, связанные с искусственным повышением позиций сайта в поисковике, негативно влияют на объективность ранжирования . И с этим разработчики активно борются. Одним из способов борьбы и является непот-фильтр – специальный алгоритм, выявляющий вредоносные внешние ссылки на сайтах и исключающий их из индекса.
Непот-фильтр существовал еще до появления понятия SEO. В прошлом, когда покупки ссылок как явления в Интернете просто не существовало, непот-фильтр не был настолько совершенным и жестким, как сейчас. В то время действительно из индекса убирались вредоносные и просто неестественные ссылки, что приносило только пользу ресурсу.
С момента, когда покупкой ссылок стали активно пользоваться для раскрутки сайта с одной стороны и заработка на сайтах с другой, непот-фильтры были значительно усовершенствованы ведущими поисковыми системами. Это привело к тому, что большое количество покупных ссылок было исключено из индекса, многие сателлиты (сайты-доноры) – подверглись бану, а продвигаемые сайты обрушились с занятых ранее позиций. На их место пришли сайты с более-менее естественной ссылочной массой, которые не попали под непот-фильтр.
Что представляет собой непот-фильтр сейчас?
Сегодня этот фильтр является инструментом проверки внешних ссылок на неестественность. Это главное оружие поисковых систем в борьбе с теми, кто торгует ссылками и продвигает сайты с их помощью, т.е. главное оружие против практически всех seo-специалистов и многих веб-мастеров.
Когда применяется непот-фильтр?
Непот-фильтр представляет главную опасность для тех, кто продает и покупает ссылки . За одно это, а также за спам ссылок можно получить некоторые санкции. Однако санкции эти не ведут к серьезным последствиям для сайта-донора и продвигаемого ресурса: либо сами ссылки, либо страница с этими ссылками вылетает из индекса поисковой системы, а сайт в целом, как правило, остается. Продвигаемый ресурс из-за действий непот-фильтра не получает нужной ссылочной массы и может даже потерять завоеванные прежде позиции.
Поисковые системы и их алгоритмы далеко не идеальны. Да и сами seo-специалисты придумывают все более изощренные пути обхода алгоритмов, поэтому с почти 100%-ной эффективностью непот-фильтр действовал лишь несколько месяцев. После этого специалисты уже разработали ряд правил, позволяющих обойти этот фильтр, и выявили несколько факторов, влекущих за собой санкции с его стороны:
Нетематичность ссылок (фильтр учитывает тематику страницы-донора, страницы, куда ведет ссылка, и текста самой ссылки);
Неестественность ссылок на разных ресурсах, ведущих на один сайт (так, появление сразу большого количества внешних ссылок или использование доноров одного типа и с одними и теми же показателями);
Большое количество внешних ссылок на одной странице (более 10-15 однозначно ведут к подпаданию под непот-фильтр или вовсе бану сайта).
Как снять непот-фильтр?
Как правило, этот вопрос интересует владельцев сайтов-доноров, которые и продают ссылки. И в этом нет ничего сложного, так как непот-фильтр накладывается автоматически и автоматически же снимается. Ни к кому обращаться за ручным снятием санкций не нужно.
Довольно сложно советовать что-то определенное для того, чтобы снять этот фильтр: поисковые системы предпочитают держать подобные вещи в секрете, и все технологии seo-специалисты разрабатывают опытным путем. Однако в данном случае все более чем просто. Для того, чтобы снять непот-фильтр, стоит для начала выявить причину наложения санкций.
Это может быть и большое количество исходящих ссылок, и их нетематичность, и неестественное их расположение на страницах. Для того, чтобы с полной уверенность добиться устранения непот-фильтра, можно постепенно снять все проданные ссылки с сайта. Если сделать это невозможно по каким-либо причинам, можно лишь уменьшить их количество, либо заменить нетематические ссылки на тематические с соответствующим тематическим окружением. Если все причины наложения санкций были устранены, сайт избавляется от влияния непот-фильтра и уже может снова использоваться для продажи ссылок.
Лучше всего, конечно, не доводить до такого и покупать/продавать только тематически подходящие ссылки в умеренных количествах, помещать ссылки в подходящий контекст и «разбрасывать» их по всей странице, а не помещать в какую-то ее отдельную часть.
, что URL, закрытые от индексации в файле robots.txt , не влияют на краулинговый бюджет этого сайта:Вместе с тем в ответе на один из вопросов к этому посту в твиттере Гэри признал, что если запретить к индексации бесполезные страницы, то краулинговый бюджет будет «возвращен» (« will gain back »), открытым для индексации полезным страницам:
Все эти «словесные кульбиты» натолкнули меня на мысль порассуждать на тему краулингового бюджета и его эффективного использования. Оговорюсь сразу, что тема оптимизации краулингового бюджета актуальна только для сайтов с достаточно большим числом страниц – счет должен идти на десятки, а то и сотни тысяч. Небольшим сайтам заморачиваться на эту тема смысла не имеет – поисковики их будут переиндексировать довольно шустро в любом случае.
Итак, вводные данные следующие. Мы определились, какие страницы на сайты мы считаем полезными для индексации, а какие – бесполезными, т.е. по сути мусором, который, находясь в индексе, может являться источником различного рода проблем. В терминах Google это называется low-value-add URL . И наша задача – убрать из индекса бесполезные страницы наиболее эффективным образом. В том числе и с точки зрения оптимизации краулингового бюджета.
Для начала уточним, что же подразумевается под краулинговым бюджетом? Если коротко, то это число страниц с кодом статуса 200 ОК , которое индексирующий робот поисковой системы отсканирует за одну сессию. Это число (равно как и частота сканирования) зависит от различных факторов, например, таких как популярность сайта, уже имеющееся число страниц в индексе и т.п.
Судя по всему, Гэри Илш, говоря, что запрещенные к индексации файлом robots.txt страницы никак не влияют на краулинговый бюджет, имел в виду то, что, так как поисковая система заведомо знает о том, что они запрещены к индексированию (а значит, индексирующему роботу не нужно их сканировать), то никоим образом не учитывает их при расчете краулингового бюджета.
В ситуации же описываемой в последующем вопросе, когда осуществляется запрет к индексации уже известных поисковой системе страниц, на которые в том числе расходовался краулинговый бюджет, произойдет следующее – выделенный краулинговый бюджет начнет расходоваться только на страницы, которые не запрещены к индексации. Это Гэри Илш и называет «возвращением» бюджета полезным страницам, т.к. в вопросе явно указано, что происходит закрытие бесполезных страниц. Кстати, теоретически при закрытии страниц от индексации краулинговый бюджет в абсолютных цифрах может и уменьшиться, т.к. уменьшится число проиндексированных страниц на сайте, но он будет расходоваться более эффективно именно для полезных страниц.
Поэтому для оптимизации краулингового бюджета может быть действительно хорошим вариантом закрытие к индексации файлом robots.txt бесполезных страниц, имеющих код статуса 200 ОК . Однако здесь могут быть нюансы. Так, например, если какие-то их этих страниц имеют входящие ссылки или ненулевой целевой трафик, то исключение таких страниц из индекса повлечет исключение из ранжирования этих значений, что теоретически может негативно сказаться на расчетных показателях релевантности проиндексированных страниц сайта. В общем, запрет для индексации в файле robots.txt может быть хорошим решением только для тех URL, которые с точки зрения ссылочных и поведенческих факторов абсолютно неинтересны.
Также следует иметь в виду, что запрет к индексации страниц с помощью мета-тега robots со значением noindex на оптимизацию краулингового бюджета существенно не повлияет. Потому что этом случае закрываемая от индексации страница имеет код статуса 200 ОК , и поисковик исключит ее из индекса только после того, как индексирующий робот ее просканирует. И в последующем индексирующий робот будет все равно вынужден такие страницы переобходить. Единственное, на что можно надеяться – так это на то, что он это будет делать с меньшей частотой чем для страниц, которые не были запрещены к индексированию с помощью мета-тега robots . Ну, хотя бы по крайней мере для тех страниц, которые имеют такой запрет на индексацию на протяжении нескольких сканирований подряд. Хотя, на мой взгляд, подобные надежды основываются на очень зыбкой почве.
Поэтому, на мой взгляд, наилучший способ исключить бесполезные страницы из краулингового бюджета – это изменить для них код статуса с 200 ОК на 301 Moved Permanently с редиректом на разрешенную к индексации полезную страницу, имеющую отклик 200 ОК . В таком случае страница с кодом статуса 301 должна «подклеиться» к странице, на которую ведет редирект с нее, причем с передачей некоторых характеристик, которые относятся к нетекстовым факторам ранжирования (например, такие как ссылочные или поведенческие). Google называет это консолидацией URL . Запомним этот термин и будем его в последующем применять. Кстати, в случае Яндекса необходимо иметь в виду следующий нюанс – подклеить страницу к странице, расположенной на другом поддомене сайта, в общем случае не получится.
Да, пожалуй, это было бы идеальное решение, оптимально закрывающее две задачи – избавления индекса от бесполезных страниц и оптимизации краулингового бюджета. Например, оно хорошо применимо для решения проблемы устаревших страниц, которые когда-то имели трафик и до сих пор имеют входящие ссылки. Но, к сожалению, оно применимо далеко не во всех случаях. Есть масса вариантов, когда страница с точки зрения владельца сайта должна по той или иной причине иметь код статуса 200 ОК , но при этом с точки зрения поисковика ее можно считать бесполезной, например:
дубликаты четкие, например, отличающиеся только наличием get-параметров в URL, которые важны владельцу сайта с точки зрения веб-аналитики;
дубликаты нечеткие, например, результаты многокритериальной фильтрации листингов товаров интернет-магазина, по факту слабо отличающие друг от друга по набору удовлетворяющих различным значениям фильтров товаров;
страницы пагинации листингов товаров в интернет магазинах
и т.п.
С точки зрения склейки страниц с сопутствующей ей консолидацией тут есть прекрасный заменитель 301 -му редиректу – директива canonical . Однако с точки зрения краулингового бюджета это не самый оптимальный вариант, т.к. неканоническая страница должна иметь код статуса 200 ОК .
В этом случае краулинговый бюджет можно оптимизировать с помощью специальной обработки запросов от поисковика, имеющих заголовок If-Modified-Since . Алгоритм действий следующий – убедившись, что поисковик посчитал конкретную страницу неканонической (это можно сделать через сервисы Яндекс.Вебмастер и Google Search Console), необходимо запомнить дату, и в последствии на запросы индексирующего робота с заголовком If-Modified-Since , содержащим дату позднее запомненной, отдавать код статуса Кстати, тот же самый прием можно применить для оптимизации краулингового бюджета в случае, о котором я писал несколько выше – когда бесполезные страницы по той или иной причине закрываются от индексации с помощью мета-тега robots со значением noindex. В этом случае нам нужно запомнить дату, когда поисковик исключил запрещенную к индексации страницу из индекса, чтоб потом использовать ее при специальной обработке запросов от индексирующего робота с заголовком If-Modified-Since .
В общем-то, специальная обработка запроса If-Modified-Since очень полезна с точки оптимизации краулингового бюджета и для полезных страниц с сайта, для которых известна дата последнего изменения их контента. Всем запросам индексирующих роботов поисковых систем с заголовком If-Modified-Since , содержащим дату позднее известной нам даты последнего изменения контента страницы, следует отдавать код статуса 304 Not Modified . Однако тут тоже есть один нюанс – такие страницы лишаются возможности попадать в так называемую «быстроботовскую» примесь для свежих результатов. Поэтому для тех страниц, которые релевантны запросам, имеющим быстроботовскую примесь, все-таки я бы рекомендовал отдавать всегда код статуса 200 ОК . Ибо возможность попадания в топ выдачи как свежий результат намного важнее оптимизации краулингового бюджета.
1. Введение
В последнее время ведется очень активное обсуждение такого явления, как наложение Яндексом «непот-фильтра» на сайты. Такая заинтересованность связана, прежде всего, с несколькими обстоятельствами:
- Покупка платных ссылок в последнее время стала основной технологией, используемой для продвижения сайтов. Многие фирмы-новички не прикладывают порой никаких усилий, связанных с оптимизацией сайта, только лишь занимаются покупкой платных ссылок.
- Вслед за увеличением спроса увеличилось и предложение. Администраторы поняли, что продажа ссылок с их сайтов достаточно прибыльное дело. Заодно возросли значительно и цены.
- Многие оптимизаторы стали замечать, что платные ссылки уже не дают того эффекта, что раньше. Теперь покупка нескольких ссылок для продвижения отдельно взятого запроса не означает автоматического попадания его в топ.
В данном мастер-классе будет сделана попытка, во-первых, разобраться с терминологией, уяснить точное значение слова «непот-фильтр», а также будет пояснена методика проверки на непот, которая активно обсуждалась на форумах в последнее время. Также будет предложен план эксперимента по выявлению непот-фильтра.
2. Что такое «непот-фильтр»?
Попробуем разобраться со значением термина. В seo-сообществе принята следующая трактовка: «Непот-фильтр» - фильтр, обнуляющий (или сводящий к минимуму) вес исходящих ссылок с площадки, на которую он наложен. Ссылки с площадки, попавшей под «непот-фильтр», не влияют на ссылочное ранжирование сайта-акцептора.
Остаются неясными несколько моментов:
- фильтр оказывает влияние на отдельные ссылки или на все внешние ссылки?
- фильтр накладывается только на отдельные страницы или на весь сайт?
«Непот-фильтр» не нужно путать с пессимизацией . Пессимизация – это искусственное понижение поисковой системой в результатах поиска позиций страниц определенного сайта, который злоупотребляет оптимизацией.
Пессимизация может быть реализована по-разному:
- отключение ссылочной составляющей для сайта;
- ввод коэффициента понижения релевантности страниц сайта;
- искусственное перенесение страниц сайта в конец выдачи (обнуление релевантности).
Также факт пессимизации (или вообще бана) официально признается Яндексом. Например, в ответ на жалобу в службу поддержки можно получить такое письмо: «…Ваш сайт использует ссылочный спам, то есть размещает и получает ссылки, предназначенные исключительно для воздействия на алгоритмы поисковой системы».
А вот наложение «непот-фильтра» службой поддержки Яндекса никак не комментируется. Ведь на самом деле - сайт продолжает корректно ранжироваться Яндексом, соответственно, и люди по ссылкам могут попасть на друзей-партнеров. Другое дело, что такие ссылки не влияют на ссылочное ранжирование «друзей-партнеров».
3. Возможные причины непота
Причина наложения фильтра – нарушение лицензии на использование поисковой системы Яндекс, п. 3.5. «Поисковый спам». В частности, к нарушению приводит простановка на сайте ссылок, единственным назначением которых является накрутка сайтов, на которые такие ссылки ведут.
- платные ссылки обычно идут блоком. Блок ссылок - это набор тегов, расположенных подряд или довольно близко в рамках одной объединяющей структуры;
- ссылки ведут на ресурсы, по тематике не совпадающие с тематикой ссылающегося сайта;
- у ссылки нет текстового окружения;
- размещают такие ссылки внизу страницы, в футере;
- обычно оформляются мелким шрифтом.
4. Как определить непот?
Методика с форума
В последнее время на форумах активно обсуждается методика, позволяющая определить наличие непот-фильтра на сайте. Суть методики в следующем:
- Проверяется отдельной взятой ссылки на платной площадке
- Задается следующий запрос ("запрос"
- Далее задается запрос anchor#link="www.мойсайт.ru"["запрос"]
- Возьмем сайт www.lenty.ru . Проверим ссылку «пластиковые окна rehau монтаж окон пвх». Ссылка расположена справа, под колонкой «новости недвижимости».
- Зададим следующий запрос: ("пластиковые окна rehau монтаж окон пвх"
3.Далее задаем запрос: anchor#link="www.sm-okna.ru"["пластиковые окна rehau монтаж окон пвх"]. Ссылка найдена, сайт www.lenty.ru показан в ссылающихся!
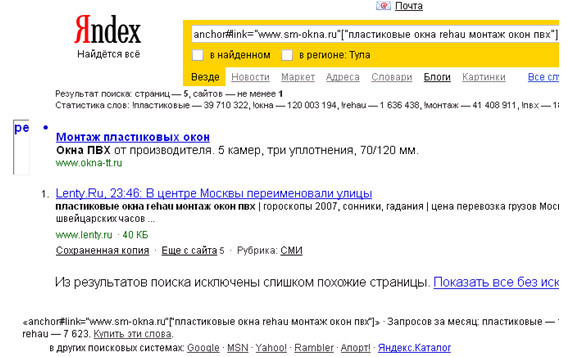
В итоге проверенная ссылка говорит о том, что на площадку наложен «непот-фильтр». Таким же образом нужно проверить все ссылки на сайте www.lenty.ru . Однако данный способ проверки наличия «непот-фильтра» сам нуждается в проверке. Ее можно провести следующим способом…
Эксперимент
- Итак, первое – нам нужен сайт с «непот-фильтром». А как определить, что он есть? Можно так - ссылка сначала действовала, а потом перестала – нам нужно смоделировать данную ситуацию.
- Сначала создаем сайт, спамим хорошенько главную страницу, чтобы у сайта появился вес.
- Ставим с сайта 5 ссылок на какие-либо проекты. Ссылка должна быть уникальная, т.е. сайт-акцептор не должен находиться по тексту ссылки.
- Теоретически сайты по своим запросам должны значительно подняться в выдаче. Поэтому надо правильно подобрать запрос, чтобы он не был конкурентным. Также надо с самого начала отслеживать позиции проектов по группе запросов, чтобы потом выбрать самые стабильные и проекты, и запросы.
- После простановки ссылок и их индексации добавляем на страницу еще много внешних ссылок, штук 20. Следим за позициями проектов, как только они резко упали – проверяем на непот. Здесь также надо учитывать «бонус новичка», т.е. проекты в любом случае после 3-4 апдейтов просядут в выдаче.
5. Заключение
В заключении приведем цитату с форума «Александр Садовский отвечает на вопросы оптимизаторов».
Вопрос: На форуме неоднократно описывался эксперимент по выявлению «непота»: на сайте А устанавливается ссылка с уникальным текстом (абракадаброй), ведущая на сайт Б. Далее, после переиндексации страницы со ссылкой, пытаемся искать абракадабру в Яндексе. Если в выдаче находится сайт А, но не находится сайт Б с пометкой «найден по ссылке» - делаем вывод, что на сайт А наложен непот-фильтр. Верно ли такое утверждение? Верно ли обратное (т.е. если в выдаче 2 сайта - непота нет)?
Ответ : Конечно, неверно. По ссылке может быть найден далеко не каждый документ, ссылка могла быть сочтена малозначимой, страницы сайта Б могут плохо ранжироваться по другим причинам и т.д. Верно ли обратное? Полного фильтра, конечно, нет, но автоматический фильтр может сильно уменьшать вес ссылок, не подавляя их полностью. Это не видно по запросу «абракадабра», но будет видно по частотным запросам.Конечно, Садовский вряд ли признался бы, что «да, так можно проверить наличие «непот-фильтра», но с другой стороны, аргументы он приводит вполне весомые…
Итак, резюмируя…
- «Непот-фильтр» есть, однако его действие до конца не изучено.
- Яндекс официально не признает существование «непот-фильтра», однако дает понять, что фильтрация ссылок есть.
- Определить «непот-фильтр» по косвенным признакам, т.е. через формирование различных запросов Яндексу и проч., затруднительно – такая методика сама еще нуждается в проверке.
- Единственный способ проверки фильтра – отслеживание влияния ссылок с проверяемого сайта.