Jak zjistit, která stránka je kanonická. Co je atribut rel="canonical", kdy a jak jej použít? Jak správně používat kanonické adresy URL
Vyhledávače se k duplicitnímu obsahu staví velmi negativně a neustále se s tímto problémem potýkají. Jedinečnost obsahu je jeho hlavní hodnotou a kopie mohou být snadno sankcionovány. Abyste tomu zabránili, můžete použít několik metod řešení duplikátů. V tomto článku rozebereme jednu z nich – kanonické adresy URL.
Důvodů pro vytváření duplicit je více, například CMS umí vytvářet další kopie, kde je stránka dostupná na adrese s www i bez. Zvláště často se kopie objevují v internetových obchodech, kde se produktové stránky liší pouze fotkou.
Kanonická adresa URL- toto je preferovaná adresa stránky, to znamená, že bude indexována ze skupiny podobných.
Kanonické URL v boji proti duplikátům.
Řekněme, že na stejnou stránku vede několik adres:
- mysite.ru/main
- mysite.ru/blog/2364
- mysite.ru/blog/page?id=2364
Pokud chceme indexovat pouze jeden z nich, musíme použít atribut rel=kanonický.
Pokud je například hlavní stránka mysite.ru/main, pak se v kódu dalších dvou objeví následující řádek:
Nutno podotknout, že vyhledávače nezaručují 100% dodržování tohoto pravidla. Pokud však nezadáte kanonickou stránku, PS to může udělat sám. V takovém případě ztratíte kontrolu nad indexováním, protože vyhledávací robot náhodně vybere stránku a přidá ji do indexu.
Neměl by být zneužit ani atribut rel=canonical. Byly weby, které ztratily pozice ve výsledcích vyhledávání poté, co vývojáři omylem napsali stejnou adresu URL do rel=canonical všech stránek webu.
Jak správně používat kanonické adresy URL?
- Vyberte hlavní stránku (kanonickou).
- Chcete-li na něj odkazovat z jiných duplicitních stránek, použijte atribut rel=canonical. Je důležité napsat absolutní cesty: http:// mysite.ru/blog/page?id=2364, nikoli /blog/page?id=2364.
- Zadejte kanonické stránky v souboru Sitemap.xml. To nezaručuje správné indexování, ale pomůže to prohledávači určit, které stránky by měly být považovány za hlavní.
Jaký je rozdíl mezi kanonickým odkazem a přesměrováním 301?
Rozdíl je v principu jejich působení. Atribut rel=canonical říká vyhledávači, kterou stránku má indexovat a zobrazit ve vyhledávání. Zbývající stránky nejsou hodnoceny, ale jsou viditelné pro uživatele na webu. Při použití přesměrování 301 jste automaticky přesměrováni na hlavní stránku. Při pohledu z pohledu přenášení hmotnosti pak obě možnosti přenesou určitou část hmotnosti na kanonickou stránku.
Použití rel=canonical a přesměrování 301 současně může být špatný nápad. Mluvíme o případech, kdy na stránku ukážete jako na kanonickou, přesměrováváte z ní naopak na jinou s přesměrováním 301. S největší pravděpodobností to vyhledávací robot bude považovat za chybu. Je možné, že se přenesená váha ztratí uvnitř tohoto řetězce, což povede ke ztrátě pozic ve výsledcích vyhledávání. Kanonické odkazy je lepší neřetězit, ale použít je pouze v rámci jednoho kroku na hlavní stránku.
A ještě pár pravidel
- Nezavírejte kanonické adresy URL v souboru robots.txt.
- Ujistěte se, že se hlavní adresa v souboru Sitemap.xml a v rel=canonical shodují.
- Na stránku lze zadat pouze jednu kanonickou stránku.
- Nezadávejte kanonickou stránku z jiné domény.
Použití kanonických adres URL je volitelné. Ale pokud máte duplicitní obsah, je nejlepší problém vyřešit sami. Jinak si to vyhledávač vyřeší po svém.
Prvek infobloku lze propojit s několika sekcemi. Ale zároveň tam může být nároky Propojení s několika sekcemi vede k tomu, že stránka webu může existovat v síti pod dvěma nebo více různými adresami. Vyhledávače zacházejí s duplicitním obsahem negativně a snižují jej ve výsledcích vyhledávání.
Pomozte takovým situacím předejít kanonický Odkazy.
Kanonický(hlavní) odkazy označují hlavní stránku vyhledávacího robota. Pokud robot najde kopie kanonické stránky na webu, označí je jako nevýznamné. podle duplikátů stránek ze SEO. Takový koncept jako "hlavní sekce" prvku pomáhá tomu zabránit. Dříve byla hlavní sekce považována za sekci s minimálním identifikátorem, což nebylo příliš pohodlné. Od verze 15.5.0 se vše změnilo, nyní si můžete sami nastavit hlavní sekci a tedy označit požadovanou stránku prvku jako kanonický. Kanonická stránka je původní stránka nebo zdroj.
Krok 1. Povolte nastavení výběru sekce v editačním formuláři infobloku na záložce pole:
Krok 2 Ve formuláři pro vytvoření/úpravu prvku zadejte do stejnojmenného pole hlavní sekci:
Důležité! Pokud pole formuláře Hlavní sekce chybí tedy změnit vzhled.
Při práci se zbožím, materiály k článkům, adresáři, často Usnadněte si práci, využijte nástroj pro přizpůsobení formuláře infobloku. Nástroj
věnujte pozornost následujícímu bodu: ve formuláři jsou pole, která nejsou
používané na webu. Další pole zvětšují velikost editačního formuláře a
ztížit zadávání dat.
zohledňuje individuální potřeby, umožňuje přizpůsobení editačních formulářů
sekce a prvky infobloku pro sebe:
Pro každý konkrétní infoblok vytvořte své vlastní jedinečné formuláře a
pracovat s radostí.
Poznámka: hlavní sekce je vybrána pouze mezi těmi sekcemi, ke kterým je prvek vázán.
Označte stránku prvku v hlavní sekci jako kanonickou (tj. nechte ji vyniknout jako hlavní stránku mezi duplikáty). Pro tohle:
- V komponentě, která vytvořila veřejné rozhraní stránky s podrobnostmi o položce, zaškrtněte volbu
 .
.
Poznámka: tato možnost byla přidána ke komponentám Zprávy Složitá komponenta umožňuje vytvořit na webu sekci novinek. K dispozici je prohlížení podrobných informací, seznam prvků, nastavení exportu do rss, organizace hlasování o novinkách (nebo jiných prvků infobloků), nastavení recenzí, zobrazování materiálů k tématům, nastavení CNC a mnoho dalšího. Komponenta obsahuje 3 šablony: .výchozí, web20 A byt. Komponenta je standardní a je součástí distribuční sady modulu.
: Obsah > Články a zprávy > Zprávy.
, Katalog Komplexní komponenta zobrazuje úplný katalog zboží z konkrétního infobloku. Jeho funkčnost kombinuje možnosti několika jednostránkových komponent: filtr, porovnávací komponenta, zobrazení prvků sekce, top prvků, souvisejících prvků atd. Umístěním složité komponenty na stránku získáte plně funkční katalog. Komponenta je standardní a je součástí distribuční sady modulu.
Pozornost! Komponenta nefunguje s infobloky, které nemají strukturu sekce. Pokud by informace dle logiky projektu neměly mít strukturní členění, pak je nutné vytvořit jednu nadúrovňovou sekci a do ní již umístit prvky infobloku.
Ve vizuálním editoru je komponenta umístěna podél cesty Obsah > Katalog > Katalog.
Komponenta patří do modulu Informační bloky.
Pořadí sekcí ve formuláři nastavení komponenty se může změnit v závislosti na vybrané šabloně.
, Novinky v detailu Jednostránková komponenta, která zobrazuje podrobný popis novinek. Komponenta je standardní a je součástí distribuční sady modulu.
Obsah > Články a novinky > Novinky podrobně.
Komponenta patří do modulu Informační bloky.
A Detail položky katalogu Komponenta zobrazuje podrobné informace o položce katalogu. Komponenta je standardní, je součástí distribuční sady modulů a obsahuje tři šablony: .výchozí, deska A old_version_16(template.default před verzí 17.0).
Ve vizuálním editoru je komponenta umístěna podél cesty Obsah > Katalog > Detail položky katalogu.
Komponenta patří do modulu Informační bloky.
- Zkontrolujte také, zda je pole správně vyplněno. Kanonická adresa URL prvku
 v editačním formuláři infobloku.
v editačním formuláři infobloku.
Poznámka: ve výše uvedených složkách a také ve složkách Sekce s horními prvky Komponenta vykreslí horní prvky seskupené podle sekcí; prvky jsou zobrazeny v tabulce. Komponenta je standardní a je součástí distribuční sady modulu.
Ve vizuálním editoru je komponenta umístěna podél cesty Obsah > Katalog > Sekce s horními prvky.
Komponenta patří do modulu Informační bloky.
A Prvky sekce Komponenta zobrazí seznam prvků řezu se zadanou sadou vlastností. Komponenta obsahuje pět šablon: .výchozí, deska, Odkazy, seznam A old_version_16(template.default před verzí 17.0). Komponenta je standardní a je součástí distribuční sady modulu.
Ve vizuálním editoru je komponenta umístěna podél cesty Obsah > Adresář > Položky sekce.
Komponenta patří do modulu Informační bloky.
Přidána možnost Pro zobrazení prvku použijte hlavní sekci. Umožňuje zobrazit prvek pouze v hlavní sekci, přestože přechod do pohledu byl proveden z jiné sekce, na kterou je prvek navázán.
Při konfiguraci komponenty věnujte pozornost dvěma dalším užitečným možnostem v Další nastavení:
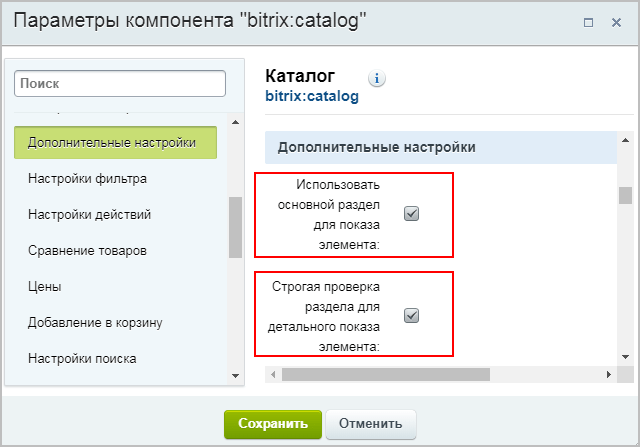

| Pokud bylo vše provedeno tak, jak je popsáno výše, ale kanonický odkaz se neobjevil v šabloně stránky s podrobnostmi o produktu, pak v případě použití přizpůsobené šablony komponenty může být problém v nesprávném přizpůsobení. Řešení Například bitrix.katalog:
|
Vyhněte se duplicitním stránkám a vylepšete svůj web z hlediska SEO. Použijte mechanismus výběru hlavní sekce k flexibilnějšímu vytvoření kanonického odkazu pro prvek:
- Zkontrolujte vlajku Povolit výběr primárního oddílu pro vazbu.
- U prvku určete, která sekce je považována za hlavní.
- Zkontrolujte vlajku Nastavte kanonickou adresu URL v nastavení komponent.
Mechanismus pro výběr hlavní sekce umožňuje větší flexibilitu při vytváření kanonické vazby pro prvek. Vyhněte se duplicitám a vylepšete svůj web z hlediska SEO.
Aby bylo možné správně propagovat stránky webu ve vyhledávačích, je nutné sdělit robotům, které adresy URL jsou pro vstup do indexu vhodnější. To se nastavuje pomocí speciálních značek.
Co je rel kanonický?
Podívejme se blíže na značku rel="canonical". Jeho hlavním cílem je bojovat s duplicitními stránkami a neinformativními stránkami (například stránkovací stránky) a také zlepšit kvalitu indexování předepsáním prioritní adresy.
Měl jsem web s omezeným rozpočtem na procházení. To znamená, že ve skutečnosti bylo 10 tisíc stránek, ale v indexu mohly být jen 2 tisíce (protože web byl mladý a nedůvěryhodný). V důsledku toho se stránky, které jsem potřeboval v indexu, často nedostaly. Pomohlo to kanonické – odstranění kanonických stránek ze stránek stránkování na hlavní adresy URL umožnilo jasně umožnit vyhledávačům pochopit, které stránky by měly být v indexu.
Co je kanonický odkaz?
Kanonická značka bude mimořádně užitečná, pokud má váš web duplicitní stránky, které jsou dostupné na různých adresách URL. S ním musíte předepsat prioritní kanonickou adresu URL pro vnímání vyhledávači.
Co je důležité - bude přenášena i váha odkazu a další charakteristiky stránky (PageRank atd.).
Tento atribut je uveden uvnitř značky
na duplicitních adresách URL s preferovanou adresou URL. Je naformátován takto:
K čemu je kanonický?
Pokud existují podobné stránky, jsou všechny současně indexovány vyhledávači. Výsledkem je, že žádná z nich není plně propagována, protože na obě stránky existují interní odkazy. Vyhledávač neví, kterému z nich dát přednost.
Totéž platí pro externí odkazy – nepropaguje se jedna URL, ale několik a mezi ně je také rozdělena váha. A web je na nižších pozicích, než by mohl být.
Díky kanonickému bude mít index vyhledávače preferovanou kanonickou URL.
Příklady použití
Máte například tištěnou verzi stránky na svém webu. Nebo samostatnou adresu URL pro mobilní verzi. A dáte z nich na hlavní stránku kanonickou stránku, ve výsledku tato hlavní stránka získá větší váhu a plus při hodnocení a z indexu se odstraní hromada odpadků.
Jak se kanonický používá pro stránkování
Musíte vložit rel canonical ze stránek stránkování (site.ru/category/page/2) na první z nich (site.ru/category).
Názory na nastavení stránkování se různí – někteří odborníci tvrdí, že je nutné zavřít všechny stránkovací stránky z vyhledávačů, jiní, že je lepší nechat je k dispozici robotům vyhledávačů.
Yandex doporučuje nastavit kanonický odkaz na první stránku ze všech stránkovacích stránek. Výsledkem je, že robot Yandex bude vnímat, že je to první stránka, kterou je třeba indexovat. Pokud jde o indexaci zboží, je uvedeno, že Yandex bude stále sledovat další odkazy.
Specialisté Google dávají přednost následujícím možnostem:
- nechat vše při starém – vyhledávač rozpoznává a vnímá různé typy stránek odlišně;
- vytvořte samostatnou "Zobrazit vše" URL a nastavte ji jako kanonickou - zvláště doporučeno pro vícestránkové články;
- přidáním atributů rel="prev" a rel="next" do značky odkazu opravíte vztah mezi adresami URL; Vyhledávač vrátí první.
A zde je Devakiho video, kde podrobně vysvětluje stránkování:
atributy rel="next" a rel="prev".
Existuje také jiný názor - například stránkovací stránky není třeba zavírat, naopak by měly získat další provoz. A důležité jsou zde dvě věci:
- Všechny adresy URL musí mít jedinečný parametr značky Title, jedinečný text a značky metadat;
- Pokud se více orientujete na Google, pak se doporučuje povinné používání atributů rel="next" a rel="prev", které je nutné nakonfigurovat tak, aby každá předchozí stránka odkazovala na následující. URL dalšího se nastavuje na kořenovou adresu, URL předchozího a následujícího na následujících a pouze předchozí na poslední.
Pomocí těchto značek můžete předepsat stránkování a umístit kanonický odkaz na první nebo hlavní stránku v závislosti na vlastnostech zdroje.

Téma s stránkováním SEO
Řekněme, že jeden z blogů (Sawynih nebo něco takového, už si to nepamatuji) psal o případu, kdy stránkovací stránky zvýšily návštěvnost.
Pokud se podobný produkt objeví na různých adresách URL, navigaci lze nastavit následujícími způsoby:
- Automaticky zapisujte jedinečné hodnoty parametrů a shromažďujte záhlaví z jednotlivých částí, například:
(koupit|objednat|koupit) sukně v (saratov|rostov|astrakhan) (za nízkou cenu|výhodné|levné) se slevou (v obchodě|v internetovém obchodě)
Budou vygenerovány jedinečné hodnoty metaznaček.
- Nejúčinnější a časově nejnáročnější je nezávislé předepisování těchto parametrů ručně. Všechny nadpisy budou jedinečné a budou se od sebe velmi lišit, včetně významu. To vám umožní propagovat každou URL pro nízkofrekvenční a málo konkurenční klíčové dotazy v TOP výsledcích vyhledávače. Díky použití této metody se rozšíří sémantické jádro. Navíc je také nevhodné psát mnoho článků pro internetový obchod.
Je důležité provést tuto práci jednou samostatně pro každou adresu URL. Parametry budou stanoveny vyhledávači.
Nastavení Canonical pro WordPress
Mnoho pluginů WordPress funguje s touto značkou skvěle.

Většina z nich se snadno používá - aktivujeme plugin a kanonické odkazy se přidávají automaticky. V ostatních SEO pluginech stačí v nastavení zaškrtnout políčko u tohoto parametru. Pokud článek patří do různých kategorií současně, pak je kanonický odkaz pevně stanoven nezávisle.
Při použití pluginu Yoast SEO a umístění příspěvku do různých kategorií se vyhledávači zobrazí pouze jedna stránka.
Co dalšího je užitečné vědět o Canonicalu?
Je důležité zdůraznit následující body:
- Kanonický tag není direktiva, ale nápověda, která by měla být vzata v úvahu a analyzována, zvýrazňující nejvhodnější URL pro výsledky vyhledávání.
- Co se týče návrhu kanonických odkazů, neexistuje žádný zakazující moment v podobě relativní cesty. I když je značka zavedena
s odkazem na dokument se s relativními cestami zachází tak, jak je uvedeno v základní adrese URL. - Kanonické stránky nemusí obsahovat úplně stejný obsah a to je logické. Mohou existovat drobné rozdíly.
- I když dojde k chybě 404, obsah bude indexován. Doporučuje se však zadat pracovní adresy URL jako kanonické.
- Pokud kanonická adresa URL ještě nebyla indexována, stále se čeká – obvykle ne dlouho. Když je rozpoznán, nápověda bude revidována.
- Můžete použít přesměrování – vyhledávač přesměrování přijme a zohlední jinou adresu.
- Pro nejlepší výsledek kanonizace se doporučuje nastavit identický tag rel canonical.
- Kanonickou adresu URL lze zapsat pouze z aktuální domény. Chcete-li zadat adresu URL z jiné domény, měli byste použít přesměrování 301.
- Formátování kanonických adres URL lze prostudovat na příkladu webu wikia.com otevřením zdrojového kódu stránky http://starwars.wikia.com/wiki/Nelvana_Limited obsahující kanonickou adresu URL http://starwars.wikia .com/wiki/Nelvana
Oba odkazy jsou téměř stejné, ale první má atribut canonical – a Google zobrazí verzi uvedenou v tomto parametru. - Na oficiálním blogu pro webmastery vyhledávače Google se můžete ptát na otázky týkající se používání kanonik.

V tomto případě je kanonický připojen k černé ovci
Výhody spojené se schopností správně nastavit indexování pomocí kanonické značky:
- zbavení se podobného obsahu spojeného s nedostatky motoru, stejně jako uměle vytvořené účelové akce konkurentů;
- není třeba používat robots.txt k zamezení indexování jednotlivých stránek a potěšit všechny vyhledávače.
Dobrý den, přátelé!
Dnes tu bude velmi důležitý článek, který se velmi úzce prolíná s tématem duplicitních stránek.
Takže se do toho pečlivě ponoříme a pokud něco není jasné, napište do komentářů. Tématem diskuze je atribut pálení rel="canonical", který má zabránit duplicitnímu obsahu a usnadnit vyhledávačům indexování.
Pojďme si projít každou otázku, abychom si udělali celkový obrázek.
Jak funguje atribut rel="canonical".
Kanonický atribut nebo značka (jak se také nazývá) se používá k tomu, aby vyhledávače věděly, která adresa je správná a je hlavní pro každou stránku na webu.
Rel="canonical" je jednou z nejdůležitějších věcí při optimalizaci jakékoli webové stránky pro vyřešení problému duplicitního obsahu. Zvláštní potřeba jeho použití se objevuje při použití různých disků k vytváření stránek, jako je WordPress, phpBB a další.
Různé motory kromě hlavních stránek generují také další dokumenty s přesně stejným obsahem, ale provádějící zcela odlišné úkoly, například:
- verze stránky pro tisk;
- mobilní verze článku;
- a jakékoli další stránky se stejným obsahem, ale s různými adresami.
Pokud vezmete web na WordPress, pak se zapnutou funkcí stromových komentářů je pod každým komentářem k dispozici tlačítko „Odpovědět“.

Zcela odlišuje adresu, ale obsah se nikde nemění. Je zde jasná duplikace obsahu, což je velmi špatné.
Jedním z nejúčinnějších způsobů, jak zabránit tomu, aby se taková stránka objevila v indexu vyhledávače, je přidat na všechny takové stránky atribut rel="canonical", který bude indikovat, že pouze článek je preferovaným dokumentem pro indexování a všechny ostatní by neměl být indexován.
Jak napsat rel="canonical"
Na různých motorech (například WordPress) se přidávání atributu rel="canonical" děje automaticky. Atribut se také přidává pomocí různých SEO pluginů.
Pokud chceme přidat canonical v manuálním režimu, tak v oblasti
zdroj by měl přidat následující řádek.< link rel = "canonical" href = "адрес страницы" / > |
Tento řádek musí být přidán do sekce záhlaví webu, tedy mezi otvor
a uzavírací značku. V opačném případě budou vyhledávače vaši indikaci ve formě tohoto atributu ignorovat. Vyplatí se také přidat na každou stránku, která není hlavní a je dostupná na jiné adrese.Vezmeme-li jako příklad výše uvedenou situaci s adresami stránek vytvořenými tlačítky pro odpověď na komentář na WordPress, pak ve zdrojovém kódu každé takové stránky můžete vidět atribut rel="canonical".
Jak můžete vidět, kanonická adresa ukazuje na hlavní stránku, když jsem si prohlížel zdrojový kód na:
http://i-am-kulinar.ru/poleznoe-obzory-intervyu/ne-proigral-nikto.html?replytocom=5499#respond
http: //i-am-kulinar.ru/poleznoe-obzory-intervyu/ne-proigral-nikto.html?replytocom=5499#respond |
Taková stránka se kvůli atributu kanonických adres do indexu nedostane. Vyhledávače vezmou v úvahu vaše pokyny.
Po zvážení základního principu tohoto atributu můžete přejít k další otázce materiálu.
V jakých případech použít?

Nyní stojí za to zvážit hlavní chyby, kterých se lze dopustit a kterých je třeba se vyvarovat.
Základní chyby

Když jsme vytřídili hlavní chyby, kterých je třeba se vyvarovat a které se nejčastěji používají, stojí za zmínku pluginy WordPress a některé body práce s atributem rel="canonical" na daném enginu.
Canonical v pluginech WordPress
Začněme jedním z nejoblíbenějších řešení na trhu – vše v jednom seo balení. Plugin je dobrý a přidává tento atribut do kódu každé stránky, přičemž odstraňuje standardní kanonický vytvořený enginem. Chcete-li to provést, povolte příslušné nastavení.

Existují 2 problémy, které mohou zasahovat do běžného indexování webu a pomoci konkurentům nás obtěžovat.
První bod se týká nesprávného fungování atributu se stránkovacími stránkami. Výše jsem napsal, že každá stránka by měla být kanonická. Plugin v rel="canonical" zadá adresu na první stránce (na hlavní adrese omen) z celého seznamu stránkování.

Taková možnost může existovat, ale není zcela správná, protože všechny stránky stránkování lze s největší pravděpodobností vyloučit z indexu PS. Pokud je to nepřijatelné, je třeba problém vyřešit.
Druhým bodem je převýšení, které jsem popsal v odpovídajícím článku (). Našim konkurentům může pomoci přidat nežádoucí stránky do indexu pomocí nástrojů addurl do indexu vyhledávání. Toto převýšení je samozřejmě opraveno a je dobré, že pomocí samotného pluginu, aktivací určitého nastavení "No Pagination for Canonical URLs".
Na tomto místě se zde nebudu podrobně zdržovat, protože otázka není malá. Pokud se chcete vyhnout druhému problému při používání tohoto pluginu, pak si přečtěte článek na odkazu v předchozím odstavci. Všechno je tam velmi podrobné, co a jak.
Druhým recenzovaným pluginem je Platinum seo pack. Se stránkovacími stránkami zachází s respektem. Problém je jen duplikace rel="canonical". Když se podíváte na zdrojový kód stránky, můžete vidět, že když je povolena funkce přidání atributu, standardní atribut zobrazený modulem není odstraněn.
