Excel örneğinde regresyon analizi. Psikolojide Matematiksel Yöntemler
Bu yazılım yardımcı programının çalışmada kullanıldığı ekonometri gibi bir disiplin de dahil olmak üzere çeşitli faaliyet alanlarında faydalı olduğu bilinmektedir. Temel olarak, pratik ve laboratuvar alıştırmalarının tüm eylemleri, belirli eylemlerin ayrıntılı açıklamalarını vererek işi büyük ölçüde kolaylaştıran Excel'de gerçekleştirilir. Bu nedenle, analiz araçlarından biri olan "Regresyon", en küçük kareler yöntemini kullanarak bir dizi gözlem için bir grafik seçmek için kullanılır. Programın bu aracının ne olduğunu ve kullanıcılar için faydasının ne olduğunu düşünelim. Aşağıda ayrıca bir regresyon modeli oluşturmak için kısa ama anlaşılır bir yönerge bulunmaktadır.
Ana görevler ve gerileme türleri
Regresyon, verilen değişkenler arasındaki bir ilişkidir, bu nedenle bu değişkenlerin gelecekteki davranışlarının tahminini belirlemek mümkündür. Değişkenler, insan davranışı da dahil olmak üzere çeşitli periyodik olaylardır. Bu Excel analizi, bir veya daha fazla değişkenin değerlerinin belirli bir bağımlı değişken üzerindeki etkisini analiz etmek için kullanılır. Örneğin, bir mağazadaki satışlar, ürün çeşitliliği, fiyatlar ve mağazanın konumu gibi çeşitli faktörlerden etkilenir. Excel'de regresyonu kullanarak, mevcut satışların sonuçlarına göre bu faktörlerin her birinin etki derecesini belirleyebilir ve ardından elde edilen verileri başka bir ayın veya yakınlarda bulunan başka bir mağazanın satışlarını tahmin etmek için uygulayabilirsiniz.
Tipik olarak regresyon, bir grubun bağımlı veya içsel, diğerinin bağımsız veya dışsal olduğu iki değişken grubu arasındaki ilişkinin gücünü ve ilişkisini ortaya koyan basit bir denklem olarak sunulur. Birbiriyle ilişkili göstergeler grubu varsa, bağımlı değişken Y muhakeme mantığına göre belirlenir ve geri kalanı bağımsız X değişkenleri olarak hareket eder.
Bir regresyon modeli oluşturmanın ana görevleri şunlardır:
- Anlamlı bağımsız değişkenlerin seçimi (Х1, Х2, …, Xk).
- İşlev türünün seçilmesi.
- Katsayılar için tahminlerin oluşturulması.
- Güven aralıklarının ve regresyon fonksiyonlarının oluşturulması.
- Hesaplanan tahminlerin ve oluşturulan regresyon denkleminin anlamlılığının kontrol edilmesi.
Birkaç tür regresyon analizi vardır:
- eşleştirilmiş (1 bağımlı ve 1 bağımsız değişken);
- çoklu (birkaç bağımsız değişken).
İki tür regresyon denklemi vardır:
- Doğrusal, değişkenler arasında katı bir doğrusal ilişkiyi gösteren.
- Doğrusal Olmayan—Kuvvetleri, kesirleri ve trigonometrik fonksiyonları içerebilen Denklemler.
Model oluşturma talimatları
Belirli bir yapıyı Excel'de gerçekleştirmek için talimatları izlemelisiniz:

Daha fazla hesaplama için, Y Değerlerini, X Değerlerini, Const ve istatistikleri belirterek "Linear()" işlevi kullanılmalıdır. Bundan sonra, "Trend" işlevini kullanarak regresyon çizgisindeki noktaları belirleyin - Y değerleri, X değerleri, Yeni değerler, Sabit. Verilen parametreleri kullanarak, problemin verilen koşullarına göre katsayıların bilinmeyen değerini hesaplayın.
İÇİNDE mükemmel doğrusal bir regresyon çizmenin daha da hızlı ve daha kolay bir yolu vardır (ve hatta ana doğrusal olmayan regresyon türleri için aşağıya bakın). Bu şu şekilde yapılabilir:
1) veri içeren sütunları seçin X Ve Y(bu sırada olmalılar!);
2) çağrı Grafik Sihirbazı ve bir grupta seçin Tip – noktalı ve hemen basın Hazır;
3) diyagramın seçimini kaldırmadan beliren ana menü öğesini seçin Diyagram, içinde öğeyi seçmeniz gereken Trend çizgisi ekle;
4) beliren iletişim kutusunda trend çizgisi sekme Tip seçmek Doğrusal;
5) sekmesi Seçenekler anahtarı etkinleştirilebilir Denklemi grafikte göster katsayıların (4.5) hesaplanacağı doğrusal regresyon denklemini (4.4) görmenizi sağlayacak.
6) Aynı sekmede, anahtarı etkinleştirebilirsiniz Yaklaşım güveninin (R^2) değerini diyagrama koyun. Bu değer korelasyon katsayısının (4.3) karesidir ve hesaplanan denklemin deneysel bağımlılığı ne kadar iyi tanımladığını gösterir. Eğer R 2 bire yakınsa, o zaman teorik regresyon denklemi deneysel bağımlılığı iyi tanımlar (teori deneyle uyumludur) ve eğer R 2 sıfıra yakınsa, bu denklem deneysel bağımlılığı açıklamak için uygun değildir (teori deneyle uyuşmaz).
Açıklanan eylemleri gerçekleştirmenin bir sonucu olarak, regresyon grafiğini ve denklemini içeren bir diyagram elde edeceksiniz.
§4.3. Ana doğrusal olmayan regresyon türleri
Parabolik ve polinom regresyon.
Parabolik değer bağımlılığı Y değerden X ikinci dereceden bir fonksiyonla (2. dereceden parabol) ifade edilen bağımlılık şu şekilde adlandırılır:
Bu denklem denir parabolik regresyon Y Açık X. Seçenekler A, B, İle isminde parabolik regresyon katsayıları. Parabolik regresyon katsayılarının hesaplanması her zaman külfetlidir, bu nedenle hesaplamalar için bir bilgisayar kullanılması önerilir.
Parabolik regresyonun Denklem (4.8), polinom adı verilen daha genel bir regresyonun özel bir halidir. polinom değer bağımlılığı Y değerden X polinom tarafından ifade edilen bağımlılık olarak adlandırılır N-inci sıra:
sayılar nerede bir ben (Ben=0,1,…, N) arandı polinom regresyon katsayıları.
Güç gerilemesi.
Güç değer bağımlılığı Y değerden X formun bağımlılığı olarak adlandırılır:
Bu denklem denir güç regresyon denklemi Y Açık X. Seçenekler A Ve B isminde güç regresyon katsayıları.
ln=ln A+B ln X. (4.11)
Bu denklem, düzlemde logaritmik koordinat eksenleri ln olan düz bir çizgiyi tanımlar. X ve ln. Bu nedenle, güç regresyonunun uygulanabilirliği için kriter, ampirik verilerin logaritma noktalarının ln olması gerekliliğidir. x ben ve ln Ben düz çizgiye en yakındı (4.11).
üstel regresyon.
örnek(veya üstel) miktarın bağımlılığı Y değerden X formun bağımlılığı olarak adlandırılır:
(veya ). (4.12)
Bu denklem denir üstel denklem(veya üstel) regresyon Y Açık X. Seçenekler A(veya k) Ve B isminde üstel(veya üstel) gerileme.
Güç regresyon denkleminin her iki tarafının logaritmasını alırsak, denklemi elde ederiz.
ln = X ln A+ln B(veya ln = k x+ln B). (4.13)
Bu denklem, bir ln niceliğinin logaritmasının başka bir niceliğe doğrusal bağımlılığını tanımlar. X. Bu nedenle, güç regresyonunun uygulanabilirliği için kriter, ampirik veri noktalarının aynı büyüklükte olması gerekliliğidir. x ben ve ln başka bir değerin logaritmaları Ben düz çizgiye en yakındı (4.13).
logaritmik regresyon.
Logaritmik değer bağımlılığı Y değerden X formun bağımlılığı olarak adlandırılır:
=A+B ln X. (4.14)
Bu denklem denir logaritmik regresyon Y Açık X. Seçenekler A Ve B isminde logaritmik regresyon katsayıları.
hiperbolik regresyon.
hiperbolik değer bağımlılığı Y değerden X formun bağımlılığı olarak adlandırılır:
Bu denklem denir hiperbolik regresyon denklemi Y Açık X. Seçenekler A Ve B isminde hiperbolik regresyon katsayıları ve en küçük kareler yöntemi ile belirlenir. Bu yöntemi uygulamak formüllere yol açar:
Formüllerde (4.16-4.17), toplama indeks üzerinden gerçekleştirilir Ben birden gözlem sayısına N.
maalesef mükemmel hiperbolik regresyon katsayılarını hesaplayan bir fonksiyon yoktur. Ölçülen değerlerin ters orantılılıkla ilişkili olduğunun kesin olarak bilinmediği durumlarda, hiperbolik regresyon denklemi yerine bir güç regresyon denklemi aranması önerilir, bu nedenle mükemmel bulmak için bir prosedür var. Ölçülen değerler arasında hiperbolik bir bağımlılık varsayılırsa, regresyon katsayılarının yardımcı hesaplama tabloları ve formüller (4.16-4.17) kullanılarak toplama işlemleri kullanılarak hesaplanması gerekecektir.
Doğrusal regresyon yöntemi, bir dizi sıralı çifte (x, y) en iyi uyan düz bir çizgiyi tanımlamamızı sağlar. Doğrusal denklem olarak bilinen düz bir çizginin denklemi aşağıda verilmiştir:
ŷ, belirli bir x değeri için y'nin beklenen değeridir,
x bağımsız bir değişkendir,
a - düz bir çizgi için y eksenindeki segment,
b düz çizginin eğimidir.
Aşağıdaki şekilde, bu kavram grafiksel olarak temsil edilmektedir:
Yukarıdaki şekil, ŷ =2+0,5x denklemiyle açıklanan bir çizgiyi göstermektedir. y eksenindeki doğru parçası, doğrunun y eksenini kestiği noktadır; bizim durumumuzda, a = 2. Doğrunun eğimi, b, çizgi yükselişinin çizgi uzunluğuna oranı, 0,5 değerine sahiptir. Pozitif bir eğim, çizginin soldan sağa doğru yükseldiği anlamına gelir. b = 0 ise çizgi yataydır, yani bağımlı ve bağımsız değişkenler arasında ilişki yoktur. Başka bir deyişle, x'in değerini değiştirmek y'nin değerini etkilemez.
ŷ ve y genellikle karıştırılır. Grafik, verilen denkleme göre 6 sıralı nokta çiftini ve bir çizgiyi göstermektedir.

Bu şekil, x = 2 ve y = 4 sıralı çiftine karşılık gelen noktayı göstermektedir. X= 2 ŷ'dir. Bunu aşağıdaki denklemle doğrulayabiliriz:
ŷ = 2 + 0,5х =2 +0,5(2) =3.
y değeri gerçek noktadır ve ŷ değeri, belirli bir x değeri için doğrusal bir denklem kullanılarak beklenen y değeridir.
Bir sonraki adım, sıralı çiftler kümesine maksimum olarak karşılık gelen doğrusal denklemi belirlemektir, denklemin biçimini ile belirlediğimiz önceki makalede bundan bahsetmiştik.
Doğrusal Regresyonu Tanımlamak için Excel'i Kullanma
Excel'de yerleşik olan regresyon analizi aracını kullanmak için eklentiyi etkinleştirmeniz gerekir. Analiz paketi. Sekmesine tıklayarak bulabilirsiniz Dosya -> Seçenekler(2007+), görüntülenen iletişim kutusunda Seçeneklermükemmel sekmeye git eklentiler sahada Kontrol seçmek eklentilermükemmel ve tıklayın Gitmek. Görünen pencerede, yanındaki kutuyu işaretleyin. analiz paketi, tıklamak TAMAM.

sekmesinde Veri grup içinde Analiz yeni bir düğme görünecek Veri analizi.

Eklentinin nasıl çalıştığını göstermek için, bir erkek ve bir kızın banyoda aynı masayı paylaştığı verileri kullanalım. Banyo örneğimizin verilerini boş bir sayfanın A ve B sütunlarına girin.
sekmeye git Veri, grup içinde Analiz tıklamak Veri analizi. Görünen pencerede Veri analizi seçme gerilemeşekilde gösterildiği gibi ve Tamam'a tıklayın.

Pencerede gerekli regresyon parametrelerini ayarlayın gerileme, resimde gösterildiği gibi:

Tıklamak TAMAM. Aşağıdaki şekil elde edilen sonuçları göstermektedir:
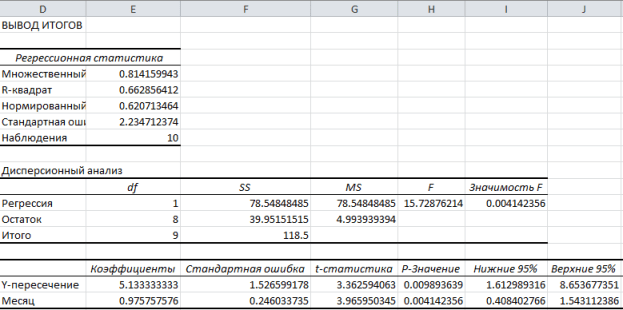
Bu sonuçlar, içinde bağımsız hesaplamalarla elde ettiğimiz sonuçlarla tutarlıdır.
Doğrusal bir regresyon oluşturmak, parametrelerini ve bunların önemini tahmin etmek, Excel analiz paketi (Regression) kullanıldığında çok daha hızlı yapılabilir. Elde edilen sonuçların yorumunu genel durumda ele alalım ( k açıklayıcı değişkenler) örnek 3.6'ya göre.
Masa regresyon istatistikleri değerler verilir:
çoklu R – çoklu korelasyon katsayısı;
R- kare- determinasyon katsayısı R 2 ;
normalleştirilmiş R - kare- ayarlandı R 2 serbestlik derecesi sayısına göre ayarlanmıştır;
standart hata regresyonun standart hatasıdır S;
gözlemler - gözlem sayısı N.
Masa varyans analizi verilen:
1. Sütun df - serbestlik derecesi sayısı, eşittir
dize için gerileme df = k;
dize için kalandf = N – k – 1;
dize için Toplamdf = N– 1.
2. Sütun SS- kare sapmaların toplamı, eşittir
dize için gerileme ;
dize için kalan ;
dize için Toplam .
3. Sütun HANIM formül tarafından belirlenen varyanslar HANIM = SS/df:
dize için gerileme– faktör varyansı;
dize için kalan kalan varyanstır.
4. Sütun F - hesaplanan değer F-formül ile hesaplanan kriterler
F = HANIM(gerileme)/ HANIM(kalan).
5. Sütun önemi F hesaplanan değere karşılık gelen anlamlılık düzeyi değeridir. F-İstatistik .
önemi F= İLK( F-İstatistik, df(gerileme), df(kalan)).
eğer önem F < стандартного уровня значимости, то R 2 istatistiksel olarak anlamlıdır.
| katsayılar | standart hata | t-istatistikleri | p değeri | alt %95 | İlk %95 | |
| Y | 65,92 | 11,74 | 5,61 | 0,00080 | 38,16 | 93,68 |
| X | 0,107 | 0,014 | 7,32 | 0,00016 | 0,0728 | 0,142 |
Bu tablo şunları gösterir:
1. Oranlar– katsayı değerleri A, B.
2. Standart hata regresyon katsayılarının standart hatalarıdır SA, Şb.
3. T-İstatistik– hesaplanan değerler T - şu formülle hesaplanan kriterler:
t-istatistik = Katsayılar / Standart hata.
4.R-değer (önem T) hesaplanan değere karşılık gelen anlamlılık düzeyi değeridir. T-İstatistik.
R-değer = STUDRASP(T-İstatistik, df(kalan)).
Eğer R-Anlam< стандартного уровня значимости, то соответствующий коэффициент статистически значим.
5. Alt %95 ve Üst %95 teorik doğrusal regresyon denkleminin katsayıları için %95 güven aralıklarının alt ve üst sınırlarıdır.
| KALAN ÇEKİM | ||
| Gözlem | tahmin edilen y | e kalır |
| 72,70 | -29,70 | |
| 82,91 | -20,91 | |
| 94,53 | -4,53 | |
| 105,72 | 5,27 | |
| 117,56 | 12,44 | |
| 129,70 | 19,29 | |
| 144,22 | 20,77 | |
| 166,49 | 24,50 | |
| 268,13 | -27,13 |
Masa KALAN ÇEKİM belirtilen:
bir sütunda Gözlem– gözlem numarası;
bir sütunda tahmin edilen y bağımlı değişkenin hesaplanan değerleridir;
bir sütunda Kalıntılar e bağımlı değişkenin gözlenen ve hesaplanan değerleri arasındaki farktır.
Örnek 3.6. Gıda harcamalarına ilişkin mevcut veriler (arb. birimler) y ve kişi başına düşen gelir X dokuz aile grubu için:
| X | |||||||||
| y |
Excel analiz paketinin (Regresyon) sonuçlarını kullanarak, gıda maliyetlerinin kişi başına gelir değerine bağımlılığını analiz ediyoruz.
Regresyon analizinin sonuçları genellikle şu şekilde yazılır:
![]()
burada parantez içinde regresyon katsayılarının standart hataları bulunmaktadır.
Regresyon katsayıları A = 65,92 ve B= 0.107. arasındaki iletişim yönü y Ve X regresyon katsayısının işaretini belirler B= 0.107, yani ilişki doğrudan ve pozitiftir. katsayı B= 0,107, kişi başına gelirde 1 arb artış olduğunu göstermektedir. birimler gıda maliyetleri 0,107 dönüşüm artar. birimler
Elde edilen modelin katsayılarının önemini tahmin edelim. Katsayıların önemi ( bir, b) karşı kontrol edilir T- Ölçek:
p değeri ( A) = 0,00080 < 0,01 < 0,05
p değeri ( B) = 0,00016 < 0,01 < 0,05,
dolayısıyla katsayılar ( bir, b) %1 düzeyinde, hatta %5 düzeyinde daha da anlamlıdır. Dolayısıyla, regresyon katsayıları anlamlıdır ve model orijinal verilere uygundur.
Regresyon tahmin sonuçları, sadece regresyon katsayılarının elde edilen değerleri ile değil, aynı zamanda setlerinin bir kısmı (güven aralığı) ile de uyumludur. %95 olasılıkla, katsayılar için güven aralıkları (38,16 - 93,68)'dir. A ve (0,0728 - 0,142) için B.
Modelin kalitesi belirleme katsayısı ile değerlendirilir R 2 .
Değer R 2 = 0,884, kişi başına gelir faktörünün gıda harcamalarındaki değişimin (dağılımın) %88,4'ünü açıklayabileceği anlamına gelir.
önemi R 2 tarafından kontrol edildi F- test: anlamlılık F = 0,00016 < 0,01 < 0,05, следовательно, R 2 %1 düzeyinde, hatta %5 düzeyinde daha da anlamlıdır.
İkili doğrusal regresyon durumunda, korelasyon katsayısı şu şekilde tanımlanabilir: ![]() . Korelasyon katsayısından elde edilen değer, gıda harcamaları ile kişi başına düşen gelir arasındaki ilişkinin çok yakın olduğunu göstermektedir.
. Korelasyon katsayısından elde edilen değer, gıda harcamaları ile kişi başına düşen gelir arasındaki ilişkinin çok yakın olduğunu göstermektedir.
Bölge toprakları için 200X için veri verilmiştir.
| bölge numarası | Sağlıklı bir kişi için günlük minimum kişi başına ortalama geçim, ovmak, x | Ortalama günlük maaş, ovmak, en |
|---|---|---|
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
Egzersiz yapmak:
1. Bir korelasyon alanı oluşturun ve bağlantının biçimi hakkında bir hipotez formüle edin.
2. Doğrusal regresyon denkleminin parametrelerini hesaplayın
4. Ortalama (genel) esneklik katsayısını kullanarak, faktör ile sonuç arasındaki ilişkinin gücünün karşılaştırmalı bir değerlendirmesini yapın.
7. Faktörün tahmin edilen değeri ortalama seviyesinden %10 artarsa sonucun tahmin edilen değerini hesaplayınız. Anlamlılık düzeyi için tahminin güven aralığını belirleyin.
Çözüm:
Excel kullanarak bu sorunu çözelim.
1. Mevcut x ve y verilerini karşılaştırarak, örneğin x faktörünün artan sırasına göre sıralayarak, kişi başına düşen asgari geçim miktarındaki bir artışın ortalama günlük ücreti artırdığı zaman, işaretler arasında doğrudan bir ilişki gözlemlenebilir. Buradan hareketle burçlar arasındaki ilişkinin doğrudan olduğu varsayılabilir ve bir doğru denklemi ile açıklanabilir. Aynı sonuç, grafiksel analiz temelinde de doğrulanmaktadır.
Bir korelasyon alanı oluşturmak için Excel PPP'yi kullanabilirsiniz. Sıradaki ilk verileri girin: önce x, sonra y.
Verileri içeren hücrelerin alanını seçin.
Ardından şunları seçin: İşaretçilerle Ekle / Dağıt / DağıtŞekil 1'de gösterildiği gibi.

Şekil 1 Korelasyon alanı yapısı
Korelasyon alanının analizi, noktalar neredeyse düz bir çizgide yer aldığından, düz bir çizgiye yakın bir bağımlılığın varlığını gösterir.
2. Doğrusal regresyon denkleminin parametrelerini hesaplamak
yerleşik istatistiksel işlevi kullanın DOT.
Bunun için:
1) Analiz edilecek verileri içeren mevcut bir dosyayı açın;
2) Regresyon istatistiklerinin sonuçlarını görüntülemek için 5×2 (5 satır, 2 sütun) boş hücrelerden oluşan bir alan seçin.
3) Etkinleştir İşlev Sihirbazı: ana menüde seçin Formüller / Ekleme İşlevi.
4) Pencerede Kategori alıyorsun istatistiksel, işlev penceresinde - DOT. butona tıklayın TAMAMŞekil 2'de gösterildiği gibi;

Şekil 2 İşlev Sihirbazı İletişim Kutusu
5) İşlev bağımsız değişkenlerini doldurun:
Bilinen değerler
Bilinen x değerleri
Devamlı- denklemde bir serbest terimin varlığını veya yokluğunu gösteren mantıksal bir değer; Sabit = 1 ise serbest terim olağan şekilde hesaplanır, eğer Sabit = 0 ise serbest terim 0'dır;
İstatistik- regresyon analizinde ek bilgilerin görüntülenip görüntülenmeyeceğini gösteren bir boole değeri. İstatistik = 1 ise ek bilgiler görüntülenir, İstatistik = 0 ise sadece denklem parametrelerinin tahminleri görüntülenir.
butona tıklayın TAMAM;

Şekil 3 DOT Bağımsız Değişkenler İletişim Kutusu
6) Final tablosunun ilk elemanı, seçilen alanın sol üst hücresinde görünecektir. Tüm tabloyu genişletmek için düğmesine basın
Ek regresyon istatistikleri, aşağıdaki şemada gösterilen sırayla çıkarılacaktır:
| b katsayısının değeri | a katsayısının değeri |
| b standart hatası | standart hata bir |
| standart hata | |
| F-istatistiği | |
| regresyon kareler toplamı
|

Şekil 4 DOT işlevini hesaplamanın sonucu
Regresyon denklemini elde ettik:
Şu sonuca varıyoruz: Kişi başına asgari 1 rublelik bir artışla. ortalama günlük ücret ortalama 0,92 ruble artıyor.
Bu, ücretlerdeki değişimin (y) %52'sinin x faktörünün değişimiyle - kişi başına düşen ortalama geçim minimumu ve %48'inin - modele dahil olmayan diğer faktörlerin etkisiyle açıklandığı anlamına gelir.
Hesaplanan belirleme katsayısına göre, korelasyon katsayısını hesaplamak mümkündür: ![]() .
.
İlişki yakın olarak derecelendirilir.
4. Ortalama (genel) esneklik katsayısını kullanarak, faktörün sonuç üzerindeki etkisinin gücünü belirleriz.
Düz çizgi denklemi için ortalama (genel) esneklik katsayısı aşağıdaki formülle belirlenir:

x değeri olan hücrelerin alanını seçerek ortalama değerleri buluyoruz ve Formüller / Otomatik Toplam / Ortalama ve aynısını y değerleri ile yapın.

Şekil 5 Bir fonksiyon ve bağımsız değişkenin ortalama değerlerinin hesaplanması
Böylece, kişi başına düşen ortalama geçim asgari değeri, ortalama değerinden %1 değişirse, ortalama günlük ücret ortalama %0,51 oranında değişecektir.
Bir veri analiz aracı kullanma gerileme mevcut:
- regresyon istatistiklerinin sonuçları,
- dağılım analizinin sonuçları,
- güven aralıklarının sonuçları,
- artıklar ve regresyon çizgisi uyum çizelgeleri,
- artıklar ve normal olasılık.
Prosedür aşağıdaki gibidir:
1) erişimi kontrol edin Analiz paketi. Ana menüde sırayla seçin: Dosya/Ayarlar/Eklentiler.
2) Bırak KontrolÖğeyi seçin Excel eklentileri ve düğmeye basın Gitmek.
3) Pencerede eklentiler kutuyu kontrol et Analiz paketi ve ardından düğmesine tıklayın TAMAM.
Eğer Analiz paketi alan listesinde eksik Kullanılabilir eklentiler, düğmesine basın Gözden geçirmek aramak.
Analiz paketinin bilgisayarınızda yüklü olmadığını belirten bir mesaj alırsanız, tıklayın. Evet yüklemek için.
4) Ana menüde sırasıyla seçin: Veri / Veri Analizi / Analiz Araçları / Regresyon ve ardından düğmesine tıklayın TAMAM.
5) Veri girişi ve çıktı seçenekleri iletişim kutusunu doldurun:
Giriş aralığı Y- etkili özelliğin verilerini içeren aralık;
Giriş aralığı X- faktör özelliğinin verilerini içeren aralık;
Etiketler- ilk satırın sütun adlarını içerip içermediğini gösteren bir bayrak;
Sabit - sıfır- denklemde serbest terimin varlığını veya yokluğunu gösteren bir bayrak;
çıkış aralığı- gelecek aralığın sol üst hücresini belirtmek yeterlidir;
6) Yeni çalışma sayfası - yeni sayfa için isteğe bağlı bir ad belirleyebilirsiniz.
Ardından düğmeye basın TAMAM.

Şekil 6 Regresyon aracının parametrelerini girmek için iletişim kutusu
Problem verileri için regresyon analizinin sonuçları Şekil 7'de gösterilmektedir.

Şekil 7 Regresyon aracını uygulamanın sonucu
5. Ortalama yaklaşım hatasını kullanarak denklemlerin kalitesini tahmin edelim. Şekil 8'de sunulan regresyon analizinin sonuçlarını kullanalım.

Şekil 8 "Artık Çıkarım" regresyon aracının uygulanmasının sonucu
Şekil 9'da gösterildiği gibi yeni bir tablo derleyelim. C sütununda, aşağıdaki formülü kullanarak göreli yaklaşım hatasını hesaplıyoruz:
![]()

Şekil 9 Ortalama yaklaşım hatasının hesaplanması
Ortalama yaklaşım hatası aşağıdaki formülle hesaplanır:

Oluşturulan modelin kalitesi %8 - 10'u geçmediği için iyi olarak değerlendirilir.
6. Regresyon istatistiklerini içeren tablodan (Şekil 4), Fisher'in F-testinin gerçek değerini yazıyoruz: ![]()
Çünkü ![]() %5 anlamlılık düzeyinde, regresyon denkleminin anlamlı olduğu sonucuna varabiliriz (ilişki kanıtlanmıştır).
%5 anlamlılık düzeyinde, regresyon denkleminin anlamlı olduğu sonucuna varabiliriz (ilişki kanıtlanmıştır).
8. Regresyon parametrelerinin istatistiksel önemini Student t-istatistiklerini kullanarak ve göstergelerin her biri için güven aralığını hesaplayarak değerlendireceğiz.
Göstergelerin sıfırdan istatistiksel olarak önemsiz bir farkı hakkında H 0 hipotezini öne sürdük:
![]() .
.
![]() serbestlik derecesi sayısı için
serbestlik derecesi sayısı için
Şekil 7, t istatistiğinin gerçek değerlerine sahiptir:
Korelasyon katsayısı için t-testi iki şekilde hesaplanabilir:
yol:
Nerede  - korelasyon katsayısının rastgele hatası.
- korelasyon katsayısının rastgele hatası.
Hesaplama için verileri Şekil 7'deki tablodan alıyoruz.

2. yol:
Gerçek t-istatistik değerleri tablo değerlerinden üstündür:
Bu nedenle, H 0 hipotezi reddedilir, yani regresyon parametreleri ve korelasyon katsayısı rastgele sıfırdan farklı değildir, ancak istatistiksel olarak anlamlıdır.
a parametresi için güven aralığı şu şekilde tanımlanır:
![]()
a parametresi için, Şekil 7'de gösterildiği gibi %95 sınırları şunlardı:
Regresyon katsayısı için güven aralığı şu şekilde tanımlanır:
![]()
Regresyon katsayısı b için, Şekil 7'de gösterilen %95 sınırları şunlardı:
![]()
Güven aralıklarının üst ve alt sınırlarının analizi, muhtemelen şu sonuca götürür: ![]() belirtilen sınırlar içinde olan a ve b parametreleri sıfır değerleri almaz, yani. istatistiksel olarak anlamlı değildir ve sıfırdan önemli ölçüde farklıdır.
belirtilen sınırlar içinde olan a ve b parametreleri sıfır değerleri almaz, yani. istatistiksel olarak anlamlı değildir ve sıfırdan önemli ölçüde farklıdır.
7. Regresyon denkleminin elde edilen tahminleri, onu tahmin için kullanmamıza izin verir. Geçim minimumunun tahmin değeri:
O zaman geçim minimumunun tahmin edilen değeri şöyle olacaktır:
Tahmin hatasını aşağıdaki formülü kullanarak hesaplıyoruz:

Nerede ![]()
Excel PPP'yi kullanarak varyansı da hesaplıyoruz. Bunun için:
1) Etkinleştir İşlev Sihirbazı: ana menüde seçin Formüller / Ekleme İşlevi.
3) Faktör karakteristiğinin sayısal verilerini içeren aralığı doldurun. Tıklamak TAMAM.

Şekil 10 Varyans hesaplaması
Varyans değerini al ![]()
Bir serbestlik derecesi başına artık varyansı hesaplamak için, Şekil 7'de gösterildiği gibi varyans analizinin sonuçlarını kullanırız.

y'nin bireysel değerlerini 0,95 olasılıkla tahmin etmek için güven aralıkları şu ifadeyle belirlenir:
![]()
Aralık, öncelikle küçük gözlem hacmi nedeniyle oldukça geniştir. Genel olarak, ortalama aylık maaşın yerine getirilen tahmininin güvenilir olduğu ortaya çıktı.
Problemin durumu şu kaynaktan alınmıştır: Ekonometri Çalıştayı: Proc. ödenek / I.I. Eliseeva, S.V. Kurysheva, N.M. Gordeenko ve diğerleri; Ed. ben Eliseeva. - M.: Finans ve istatistik, 2003. - 192 s.: hasta.