Excel'de çoklu regresyon denklemi. Excel'de Hızlı Doğrusal Regresyon: Eğilim Çizgisi
Eklenti kullanılarak istatistiksel veri işleme de gerçekleştirilebilir. ANALİZ PAKETİ(Şek. 62).
Önerilen öğelerden öğeyi seçin " GERİLEME” ve farenin sol tuşu ile üzerine tıklayın. Ardından, Tamam'ı tıklayın.
Şekil l'de gösterilen pencere 63.

Analiz Aracı « GERİLEME» en küçük kareler yöntemini kullanarak bir grafiği bir dizi gözleme sığdırmak için kullanılır. Regresyon, bir veya daha fazla bağımsız değişkenin değerlerinin tek bir bağımlı değişken üzerindeki etkisini analiz etmek için kullanılır. Örneğin, bir sporcunun atletik performansı yaş, boy ve kilo dahil olmak üzere çeşitli faktörlerden etkilenir. Bu üç faktörün her birinin bir sporcunun performansı üzerindeki etki derecesini hesaplamak ve daha sonra elde edilen verileri başka bir sporcunun performansını tahmin etmek için kullanmak mümkündür.
Regresyon aracı işlevi kullanır DOT.
REGRESS İletişim Kutusu
Etiketler Giriş aralığının ilk satırı veya ilk sütunu başlık içeriyorsa onay kutusunu seçin. Başlık yoksa bu onay kutusunu temizleyin. Bu durumda çıktı tablosu verileri için uygun başlıklar otomatik olarak oluşturulacaktır.
Güvenilirlik Düzeyi Çıktı toplamları tablosuna ek bir düzey eklemek için onay kutusunu seçin. Uygun alana, varsayılan %95 güven düzeyine ek olarak uygulamak istediğiniz güven düzeyini girin.
Sabit - sıfır Regresyon çizgisinin orijinden geçmesi için kutuyu işaretleyin.
Çıkış Aralığı Çıkış aralığının sol üst hücresine bir referans girin. Sonuçların çıktı tablosu için aşağıdakileri içerecek en az yedi sütun tahsis edin: varyans analizinin sonuçları, katsayılar, Y hesaplamasının standart hatası, standart sapmalar, gözlem sayısı, katsayılar için standart hatalar.
Yeni Çalışma Sayfası Çalışma kitabında yeni bir çalışma sayfası açmak ve analiz sonuçlarını A1 hücresinden başlayarak eklemek için bu kutuyu işaretleyin. Gerekirse, uygun radyo düğmesi konumunun karşısındaki alana yeni sayfa için bir ad girin.
Yeni Çalışma Kitabı Sonuçların yeni bir sayfaya ekleneceği yeni bir çalışma kitabı oluşturmak için bu kutuyu işaretleyin.
Artıklar Artıkları çıktı tablosuna dahil etmek için onay kutusunu seçin.
Standartlaştırılmış Artıklar Çıktı tablosuna standartlaştırılmış artıkları dahil etmek için onay kutusunu seçin.
Artık Grafik Her bir bağımsız değişken için artıkları çizmek için kutuyu işaretleyin.
Grafiği Sığdır Gözlenen değerlere karşı tahmin edilen değerleri çizmek için onay kutusunu seçin.
Normal Olasılık Grafiği Normal olasılığı çizmek için kutuyu işaretleyin.
İşlev DOT
Hesaplama yapmak için ortalama değeri göstermek istediğimiz hücreyi imleç ile seçin ve klavyeden = tuşuna basın. Ardından, Ad alanında istediğiniz işlevi belirtin, örneğin ORTALAMA(Şek. 22).
İşlev DOT mevcut verilere en iyi yaklaşan düz bir çizgiyi hesaplamak için en küçük kareler yöntemini kullanarak bir serinin istatistiklerini hesaplar ve ardından elde edilen düz çizgiyi açıklayan bir dizi döndürür. Ayrıca işlevi birleştirebilirsiniz DOT polinom, logaritmik, üstel ve kuvvet serileri dahil olmak üzere bilinmeyen parametrelerde (bilinmeyen parametreleri doğrusal olan) doğrusal olan diğer model türlerini hesaplamak için diğer işlevlerle birlikte. Bir dizi değer döndürüldüğünden, işlev bir dizi formülü olarak belirtilmelidir.
Düz bir çizginin denklemi:
y=m 1 x 1 +m 2 x 2 +…+b (birkaç x değeri aralığı olması durumunda),
burada bağımlı değer y bağımsız değer x'in bir fonksiyonudur, m değerleri her x bağımsız değişkenine karşılık gelen katsayılardır ve b bir sabittir. y, x ve m'nin vektör olabileceğine dikkat edin. İşlev DOT bir dizi döndürür(mn;mn-1;…;m 1 ;b). DOT ek regresyon istatistikleri de döndürebilir.
DOT(bilinen_y-değerleri; bilinen_x-değerleri; sabit; istatistikler)
Bilinen_y değerleri - y=mx+b ilişkisi için zaten bilinen y değerleri kümesi.
Bilinen_y dizisinin bir sütunu varsa, bilinen_x dizisinin her sütunu ayrı bir değişken olarak yorumlanır.
Bilinen_y dizisinin bir satırı varsa, bilinen_x dizisinin her satırı ayrı bir değişken olarak yorumlanır.
Bilinen_x değerleri - y=mx+b ilişkisi için zaten bilinen isteğe bağlı bir x değerleri kümesi.
Bilinen_x dizisi, bir veya daha fazla değişken kümesi içerebilir. Yalnızca bir değişken kullanılırsa, aynı boyuta sahip oldukları sürece diziler_bilinen_y_değerler ve bilinen_x_değerler herhangi bir şekilde olabilir. Birden fazla değişken kullanılıyorsa, bilinen_y'ler bir vektör olmalıdır (yani, bir satır yüksekliğinde veya bir sütun genişliğinde).
Dizi_bilinen_x atlanırsa, bu dizinin (1;2;3;...) dizi_bilinen_y ile aynı boyutta olduğu varsayılır.
Sabit, b sabitinin 0 olması gerekip gerekmediğini belirten bir boole değeridir.
"const" bağımsız değişkeni DOĞRU ise veya atlanmışsa, b sabiti normal olarak değerlendirilir.
"const" argümanı YANLIŞ ise, b'nin değerinin 0 olduğu varsayılır ve m'nin değerleri, y=mx ilişkisini sağlayacak şekilde seçilir.
İstatistikler, ek regresyon istatistiklerinin döndürülüp döndürülmeyeceğini gösteren bir Boolean değeridir.
İstatistikler DOĞRU ise DOT, ek regresyon istatistikleri döndürür. Dönen dizi şöyle görünecektir: (mn;mn-1;...;m1;b:sen;sen-1;...;se1;seb:r2;sey:F;df:ssreg;ssresid).
İstatistik YANLIŞ ise veya atlanmışsa, DOT yalnızca m katsayılarını ve b sabitini döndürür.
Ek regresyon istatistikleri (Tablo 17)
| Değer | Tanım |
| se1,se2,...,sen | m1,m2,...,mn katsayıları için standart hata değerleri. |
| seb | b sabiti için standart hata ('sabit' YANLIŞ ise seb = #YOK). |
| r2 | Belirleme faktörü. y'nin gerçek değerleri, düz çizgi denkleminden elde edilen değerlerle karşılaştırılır; karşılaştırma sonuçlarına göre, determinizm katsayısı hesaplanır, 0'dan 1'e normalleştirilir. 1'e eşitse, o zaman modelle tam bir korelasyon vardır, yani gerçek ve tahmin edilen değerler arasında fark yoktur y. Aksi takdirde, determinizm katsayısı 0 ise, y değerlerini tahmin etmek için regresyon denklemini kullanmanın bir anlamı yoktur. r2'nin nasıl hesaplanacağı hakkında daha fazla bilgi için, bu bölümün sonundaki "Açıklamalar" bölümüne bakın. |
| sey | y tahmini için standart hata. |
| F | F-istatistik veya F-gözlemlenen değer. F istatistiği, bağımlı ve bağımsız değişkenler arasında gözlenen bir ilişkinin rastgele olup olmadığını belirlemek için kullanılır. |
| df | Özgürlük derecesi. Serbestlik dereceleri, istatistiksel bir tabloda F-kritik değerleri bulmak için kullanışlıdır. Modelin güven düzeyini belirlemek için tablodaki değerleri LINEST tarafından döndürülen F istatistiği ile karşılaştırmalısınız. df'nin hesaplanması hakkında daha fazla bilgi için bu bölümün sonundaki "Açıklamalar" bölümüne bakın. Aşağıdaki Örnek 4, F ve df'nin kullanımını göstermektedir. |
| ssreg | Regresyon kareler toplamı. |
| ssresid | Artık kareler toplamı. ssreg ve ssresid'in hesaplanması hakkında daha fazla bilgi için bu bölümün sonundaki "Açıklamalar" bölümüne bakın. |
Aşağıdaki şekil, ek regresyon istatistiklerinin döndürülme sırasını göstermektedir (Şekil 64).

notlar:
Herhangi bir düz çizgi, eğimi ve y ekseni ile kesişimi ile tanımlanabilir:
Eğim (m): genellikle m ile gösterilen bir doğrunun eğimini belirlemek için, doğru üzerinde (x 1 ,y 1) ve (x 2 ,y 2) iki nokta almanız gerekir; eğim (y 2 -y 1) / (x 2 -x 1)'e eşit olacaktır.
Y kesişimi (b): Bir doğrunun y kesişimi, genellikle b ile gösterilir, doğrunun y eksenini kestiği noktanın y değeridir.
Düz çizgi denklemi y=mx+b biçimindedir. m ve b'nin değerleri biliniyorsa, doğru üzerindeki herhangi bir nokta, denklemde y veya x değerleri yerine yazılarak hesaplanabilir. TREND işlevini de kullanabilirsiniz.
Yalnızca bir bağımsız değişken x varsa, aşağıdaki formülleri kullanarak doğrudan eğimi ve y-kesişimini elde edebilirsiniz:
Eğim: DİZİN(DOT(bilinen_y'ler, bilinen_x'ler), 1)
Y-kesme noktası: DİZİN(DOT(bilinen_y'ler, bilinen_x'ler), 2)
DOT işlevi tarafından hesaplanan düz çizgi kullanılarak yapılan yaklaşımın doğruluğu, veri dağılımının derecesine bağlıdır. Veriler düz bir çizgiye ne kadar yakınsa, DOT tarafından kullanılan model o kadar doğru olur. DOT işlevi, verilere en uygun olanı belirlemek için en küçük kareler yöntemini kullanır. Yalnızca bir bağımsız değişken olduğunda x, m ve b aşağıdaki formüller kullanılarak hesaplanır:

burada x ve y örnek araçlardır, örneğin x = ORTALAMA(bilinen_x'ler) ve y = ORTALAMA(bilinen_y'ler).
DOT ve LGRFPRIBL sığdırma işlevleri, verilere en iyi uyan düz veya üstel bir eğri hesaplayabilir. Ancak sorunun çözümü için iki sonuçtan hangisinin daha uygun olduğu sorusuna cevap vermiyorlar. Düz bir çizgi için TREND(bilinen_y-değerleri; bilinen_x-değerleri) işlevini veya bir üstel eğri için BÜYÜME(bilinen_y-değerleri; bilinen_x-değerleri) işlevini de hesaplayabilirsiniz. Bu işlevler, new_x_values argümanından atlanırsa, düz bir çizgiye veya eğriye göre gerçek x değerleri için hesaplanan y değerleri dizisi döndürür. Daha sonra hesaplanan değerleri gerçek değerlerle karşılaştırabilirsiniz. Görsel karşılaştırma için grafikler de oluşturabilirsiniz.
Bir regresyon analizi gerçekleştirirken Microsoft Excel, her nokta için tahmin edilen y değeri ile gerçek y değeri arasındaki farkın karesini hesaplar. Bu kare farkların toplamına artık kareler toplamı (ssresid) denir. Microsoft Excel daha sonra toplam kareler toplamını (sstotal) hesaplar. const = DOĞRU ise veya bu argüman belirtilmemişse, toplam kareler toplamı, gerçek y değerleri ile ortalama y değerlerinin kareleri alınmış farklarının toplamına eşit olacaktır. sabit = YANLIŞ ise, kareler toplamı gerçek y değerlerinin karelerinin toplamına eşit olacaktır (ortalama y'yi y bölümünden çıkarmadan). Bundan sonra karelerin regresyon toplamı şu şekilde hesaplanabilir: ssreg = sstotal - ssresid. Artık kareler toplamı ne kadar küçükse, determinizm katsayısı r2'nin değeri o kadar büyük olur; bu, regresyon analizi kullanılarak elde edilen denklemin değişkenler arasındaki ilişkileri ne kadar iyi açıkladığını gösterir. r2 katsayısı ssreg/sstotal'a eşittir.
Bazı durumlarda, bir veya daha fazla X sütunu (Y ve X değerlerinin sütunlarda olduğu varsayılarak) diğer X sütunlarında ek bir öngörü değerine sahip değildir, başka bir deyişle, bir veya daha fazla X sütununun silinmesi, Y değerlerinin ortaya çıkmasına neden olabilir. aynı hassasiyetle hesaplanır. Bu durumda, gereksiz X sütunları regresyon modelinden çıkarılacaktır. Bu fenomene "eşdoğrusallık" denir, çünkü X'in gereksiz sütunları birkaç yedeksiz sütunun toplamı olarak temsil edilebilir. DOT, eşdoğrusallığı kontrol eder ve herhangi bir gereksiz X sütunu bulursa, regresyon modelinden kaldırır. Kaldırılan X sütunlar, DOT çıktısında 0 faktörü ve se değeri 0 ile tanımlanabilir. Bir veya daha fazla sütunun fazlalık olarak kaldırılması, df'nin değerini değiştirir çünkü bu, gerçekte tahmin amaçlı kullanılan X sütun sayısına bağlıdır. Df'nin hesaplanmasıyla ilgili daha fazla ayrıntı için aşağıdaki Örnek 4'e bakın.Gereksiz sütunların kaldırılması nedeniyle df değiştiğinde, sey ve F değerleri de değişir. Doğrusallığın kullanılması genellikle önerilmez. Ancak deney konusunun ayrı bir grupta olup olmadığının göstergesi olarak bazı X sütunlarında 0 veya 1 bulunuyorsa kullanılmalıdır. const = TRUE ise veya bu bağımsız değişken belirtilmemişse DOT, kesişme noktasını simüle etmek için ek bir X sütunu ekler. Erkekler için 1, kadınlar için 0 değerlerine sahip bir sütun varsa ve kadınlar için 1 ve erkekler için 0 değerlerine sahip bir sütun varsa, son sütun kaldırılır çünkü değerleri şu adresten alınabilir: "erkek göstergesi" sütunu.
Eşdoğrusallık nedeniyle X sütunun modelden çıkarılmadığı durumlar için df'nin hesaplanması şu şekildedir: k bilinen_x sütun varsa ve const = DOĞRU veya belirtilmemişse df = n - k - 1. const = YANLIŞ ise, o zaman df = n - k. Her iki durumda da, eşdoğrusallık nedeniyle X sütunlarının kaldırılması, df'nin değerini 1 artırır.
Dizi döndüren formüller, dizi formülleri olarak girilmelidir.
Örneğin, bir bilinen_x_değerler argümanı olarak bir sabit dizisi girerken, aynı satırdaki değerleri ayırmak için noktalı virgül, satırları ayırmak için iki nokta üst üste kullanın. Ayırıcı karakterler, kontrol panelindeki "Dil ve Standartlar" penceresindeki ayarlara bağlı olarak değişebilir.
Regresyon denkleminin öngördüğü y değerlerinin, denklemi tanımlamak için kullanılan y değerleri aralığının dışında olmaları durumunda doğru olmayabileceğini unutmayın.
Fonksiyonda kullanılan ana algoritma DOT, fonksiyonların ana algoritmasından farklıdır EĞİM Ve ÇİZGİ SEGMENTİ. Algoritmalar arasındaki farklılıklar, belirsiz ve eşdoğrusal veriler için farklı sonuçlara yol açabilir. Örneğin, bilinen_y bağımsız değişkeninin veri noktaları 0 ise ve bilinen_x bağımsız değişkeninin veri noktaları 1 ise, o zaman:
İşlev DOT 0'a eşit bir değer döndürür. İşlev algoritması DOT eşdoğrusal veriler için uygun değerleri döndürmek için kullanılır, bu durumda en az bir cevap bulunabilir.
EĞİM ve KESME İŞLEVLERİ #SAYI/0! hatası verir. SLOPE ve INTERCEPT fonksiyonlarının algoritması sadece bir cevap bulmak için kullanılır ve bu durumda birkaç cevap olabilir.
Diğer regresyon türleri için istatistiklerin hesaplanmasına ek olarak, DOT, x ve y değişkenlerinin fonksiyonlarını DOT için bir dizi x ve y değişkeni olarak girerek diğer regresyon türlerinin aralıklarını hesaplamak için kullanılabilir. Örneğin, aşağıdaki formül:
DOT(y-değerleri, x-değerleri^SÜTUN($A:$C))
aşağıdaki formun bir küp yaklaşımını (3. derece polinom) hesaplamak için bir Y değerleri sütunu ve bir X değerleri sütunu ile çalışır:
y=m 1 x+m 2 x 2 +m 3 x 3 +b
Formül, diğer regresyon türlerinin hesaplamaları için değiştirilebilir, ancak bazı durumlarda çıktı değerlerinde ve diğer istatistiklerde ayarlamalar yapılması gerekir.
Microsoft Excel'de Regresyon Analizi, iş zekasında regresyon analizi sorunlarını çözmek için MS Excel'i kullanmanın en kapsamlı kılavuzudur. Konrad Carlberg, bilgisi hem kendiniz regresyon analizi yaparken hem de başkaları tarafından yapılan analizlerin sonuçlarını değerlendirirken birçok hatadan kaçınmanıza yardımcı olacak teorik konuları net bir şekilde açıklıyor. Basit korelasyonlar ve t-testlerinden çoklu kovaryans analizine kadar tüm materyaller gerçek örneklere dayalıdır ve ilgili adım adım prosedürlerin ayrıntılı bir açıklamasıyla birlikte sunulur.
Bu kitap, Excel'in regresyon fonksiyonlarının tüm ayrıntılarını tartışıyor, seçeneklerin ve argümanların her birini kullanmanın sonuçlarını inceliyor ve regresyon tekniklerinin tıbbi araştırmadan finansal analize kadar uzanan alanlarda güvenilir bir şekilde nasıl uygulanacağını açıklıyor.
Konrad Carlberg. Microsoft Excel'de regresyon analizi. - M.: Diyalektik, 2017. - 400 s.
Notu veya formatında indirin, formatta örnekler
Bölüm 1. Veri değişkenliğini tahmin etme
İstatistikçilerin emrinde birçok varyasyon (değişkenlik) göstergesi vardır. Bunlardan biri, bireysel değerlerin ortalamadan kare sapmalarının toplamıdır. Excel bunun için SQUADROT() işlevini kullanır. Ancak daha sıklıkla dispersiyon kullanılır. Varyans, sapmaların karelerinin ortalamasıdır. Varyans, incelenen veri kümesindeki değer sayısına duyarsızdır (oysa karesi alınmış sapmaların toplamı, ölçüm sayısıyla artar).
Excel, varyans döndüren iki işlev sunar: VARP.D() ve VARP.V():
- İşlenecek değerler bir popülasyon oluşturuyorsa VAR.G() işlevini kullanın. Yani, aralıkta yer alan değerler, yalnızca ilgilendiğiniz değerlerdir.
- İşlenecek değerler daha büyük bir popülasyondan bir örnek oluşturuyorsa VAR.V() işlevini kullanın. Varyansını da tahmin edebileceğiniz ek değerler olduğunu varsayar.
Ortalama veya korelasyon katsayısı gibi bir değer, genel popülasyon bazında hesaplanırsa buna parametre denir. Bir örneklem temelinde hesaplanan benzer bir değere istatistik denir. Sapmaları saymak ortalamadan bu kümede, sapmaların karelerinin toplamını başka herhangi bir değerden saydığınızdan daha küçük bir miktarda elde edeceksiniz. Benzer bir ifade dağılım için de geçerlidir.
Örnek boyutu ne kadar büyük olursa, istatistiğin hesaplanan değeri o kadar doğru olur. Ancak, istatistiğin değerinin parametrenin değeriyle aynı olduğundan emin olabileceğiniz, popülasyonun boyutundan daha küçük bir örnek yoktur.
Diyelim ki, ortalamaları popülasyon ortalamasından farklı olan, fark ne kadar küçük olursa olsun, 100 boydan oluşan bir kümeniz var. Numune için varyansı hesapladığınızda, 4 gibi bir değer elde edersiniz. Bu değer, 100 büyüme değerinin her birinin numune ortalaması dışındaki herhangi bir değerden sapması hesaplanarak elde edilebilecek diğer tüm değerlerden daha azdır. , genel nüfus için gerçek ortalama dahil. Bu nedenle, hesaplanan varyans, örneklem ortalamasını değil de popülasyon parametresini bir şekilde bilip kullanmış olsaydınız elde edeceğiniz varyanstan daha az ölçüde farklı olacaktır.
Örnek için belirlenen ortalama kareler toplamı, popülasyon varyansının daha düşük bir tahminini sağlar. Bu şekilde hesaplanan varyansa denir. yerinden edilmiş değerlendirme. Önyargıyı ortadan kaldırmak ve yansız bir tahmin elde etmek için sapmaların karelerinin toplamını bölmenin yeterli olduğu ortaya çıktı. N, Nerede Nörneklem büyüklüğüdür ve n - 1.
Değer n - 1 serbestlik derecesi sayısı (sayı) olarak adlandırılır. Bu değeri hesaplamanın farklı yolları vardır, ancak bunların tümü ya örneklem büyüklüğünden bazı sayıların çıkarılmasını ya da gözlemlerin içine düştüğü kategorilerin sayısını saymayı içerir.
DISP.G() ve DISP.V() işlevleri arasındaki farkın özü şu şekildedir:
- VARI.G() işlevinde, kareler toplamı gözlem sayısına bölünür ve bu nedenle varyansın önyargılı tahminini, yani gerçek ortalamayı temsil eder.
- VAR.B() işlevinde, kareler toplamı gözlem sayısı eksi 1'e bölünür, yani örneğin alındığı popülasyonun varyansının daha doğru, yansız bir tahminini veren serbestlik derecesi sayısına göre.
standart sapma (İngilizce) standart sapma, SD) varyansın kareköküdür:
Sapmaların karesini almak, ölçüm ölçeğini orijinal ölçünün karesi olan başka bir metriğe çevirir: metre - metrekareye, dolar - dolar karesine vb. Standart sapma, varyansın kareköküdür ve bizi orijinal birimlere geri getirir. Hangisi daha uygun.
Veriler bir miktar manipülasyona tabi tutulduktan sonra genellikle standart sapmayı hesaplamak gerekir. Ve bu durumlarda sonuçlar şüphesiz standart sapmalar olsa da, genellikle standart hatalar. Standart ölçüm hatası, standart orantı hatası ve ortalamanın standart hatası dahil olmak üzere birkaç standart hata türü vardır.
Diyelim ki 50 eyaletin her birinden rastgele seçilmiş 25 yetişkin erkeğin boyu hakkında veri topluyorsunuz. Ardından, her eyaletteki yetişkin erkeklerin ortalama boyunu hesaplarsınız. Ortaya çıkan 50 ortalama değer, sırayla gözlem olarak kabul edilebilir. Bundan, standart sapmalarını hesaplayabilirsiniz, ki bu ortalamanın standart hatası. Pirinç. 1. 1250 orijinal bireysel değerin dağılımını (50 eyaletin her birinde 25 erkeğin boyuna ilişkin veriler) 50 eyaletin ortalama değerlerinin dağılımı ile karşılaştırmanıza olanak tanır. Ortalamanın standart hatasını tahmin etme formülü (yani, bireysel gözlemlerin değil, ortalamaların standart sapması):
![]()
ortalamanın standart hatası nerede; S orijinal gözlemlerin standart sapmasıdır; Nörneklemdeki gözlem sayısıdır.

Pirinç. 1. Eyaletten eyalete ortalama değerlerdeki değişiklik, bireysel gözlemlerin varyasyonundan çok daha azdır
İstatistikte, istatistiksel büyüklükleri belirtmek için Yunan ve Latin harflerinin kullanımına ilişkin bir gelenek vardır. Genel popülasyonun parametrelerini Yunan harfleriyle ve örnek istatistikleri Latin harfleriyle belirtmek gelenekseldir. Bu nedenle, popülasyonun standart sapmasından bahsediyorsak, bunu σ olarak yazarız; örneğin standart sapması dikkate alınırsa, s gösterimini kullanırız. Ortalamalar için sembollere gelince, birbirleriyle pek uyuşmuyorlar. Nüfus ortalaması, Yunanca μ harfi ile gösterilir. Bununla birlikte, X̅ sembolü geleneksel olarak örnek ortalamayı temsil etmek için kullanılır.
z puanı standart sapma birimleri cinsinden dağılımdaki gözlemin konumunu ifade eder. Örneğin, z = 1,5, gözlemin ortalamadan 1,5 standart sapma uzakta, daha yüksek değerlere doğru olduğu anlamına gelir. Terim z puanı bireysel değerlendirmeler için kullanılır, örn. örneğin bireysel öğelerine atfedilen ölçümler için. Bu tür istatistikler için (örneğin, durum ortalaması), terim kullanılır. z değeri:

burada X̅ örneğin ortalama değeridir, μ genel popülasyonun ortalama değeridir, örnek kümesinin araçlarının standart hatasıdır:
![]()
σ genel popülasyonun standart hatasıdır (bireysel ölçümler), Nörneklem büyüklüğüdür.
Diyelim ki bir golf eğitmenisiniz. Uzun süredir vuruş menzilini ölçebiliyorsunuz ve ortalamanın 205 yarda ve standart sapmanın 36 yarda olduğunu biliyorsunuz. Menzilinizi 10 yard artıracağını iddia ederek size yeni bir sopa teklif edildi. Sonraki 81 kulüp müdaviminin her birinden yeni bir kulüple denemelerini ve menzillerini kaydetmelerini istiyorsunuz. Yeni bir sopayla ortalama vuruş menzilinin 215 yarda olduğu ortaya çıktı. 10 yarda farkın (215 - 205) yalnızca örnekleme hatasından kaynaklanma olasılığı nedir? Veya başka bir deyişle, daha büyük bir testte, yeni bir sopanın mevcut uzun vadeli ortalama olan 205 yardaya kıyasla menzilde bir artış göstermeme olasılığı nedir?
Bunu bir z değeri üreterek test edebiliriz. Ortalamanın standart hatası:
![]()
O zaman z değeri:

Numune ortalamasının popülasyon ortalamasından 2,5σ uzakta olma olasılığını bulmamız gerekiyor. Olasılık küçükse, farklılıklar şansa değil, yeni kulübün kalitesine bağlıdır. Excel'de bir z puanının olasılığını belirlemek için hazır bir işlev yoktur. Ancak, =1-NORM.ST.DAĞ(z-değeri, DOĞRU) formülünü kullanabilirsiniz; burada NORM.ST.DAĞ(), z-değerinin solundaki normal eğrinin altındaki alanı döndürür (Şekil 2) .

Pirinç. 2. NORM.S.DIST() işlevi, z-değerinin solundaki eğri altındaki alanı döndürür; Bir görüntüyü büyütmek için üzerine sağ tıklayın ve seçin Resmi yeni sekmede aç
NORM.S.DAĞ() işlevinin ikinci bağımsız değişkeni iki değer alabilir: DOĞRU - işlev, birinci bağımsız değişken tarafından belirtilen noktanın solundaki eğri altındaki alanı döndürür; YANLIŞ - İşlev, ilk bağımsız değişken tarafından verilen noktada eğrinin yüksekliğini döndürür.
Popülasyonun ortalaması (μ) ve standart sapması (σ) bilinmiyorsa, t-değeri kullanılır (bakınız ). Z- ve t-skoru yapıları, t-değerini bulmak için popülasyon parametresi σ'nin bilinen değeri yerine numune sonuçlarından elde edilen standart sapma s kullanılması bakımından farklılık gösterir. Normal eğri tek bir şekle sahiptir ve t değerlerinin dağılımının şekli serbestlik derecesi sayısına bağlı olarak değişir df (İngilizlerden. özgürlük derecesi) temsil ettiği numunenin. Numunenin serbestlik derecesi sayısı n - 1, Nerede N- örneklem büyüklüğü (Şekil 3).

Pirinç. 3. σ parametresi bilinmediğinde ortaya çıkan t dağılımlarının şekli, normal dağılımın şeklinden farklıdır.
Excel'in t-dağılımı için Student t-dağılımı olarak da adlandırılan iki işlevi vardır: STUDENT.DIST(), verilen t-değerinin solundaki eğrinin altındaki alanı ve sağdaki STUDENT.DIST.RT()'yi döndürür.
Bölüm 2. Korelasyon
Korelasyon, bir dizi sıralı çiftin elemanları arasındaki bağımlılığın bir ölçüsüdür. Korelasyon karakterize edilir Pearson korelasyon katsayıları- R. Katsayı -1.0 ile +1.0 aralığında değerler alabilir.

Nerede S x Ve Sy değişkenlerin standart sapmalarıdır X Ve Y, Sxy– kovaryans:

Bu formülde kovaryans, değişkenlerin standart sapmalarına bölünür. X Ve Y, böylece kovaryanstan birim ile ilgili ölçekleme etkilerini ortadan kaldırır. Excel, CORREL() işlevini kullanır. Bu işlevin adı, STDEV(), VARV() veya COVARIANCE() gibi işlevlerin adlarında kullanılan G ve C niteleyici öğelerini içermez. Örnek korelasyon katsayısı taraflı bir tahmin sağlasa da, sapmanın nedeni varyans veya standart sapma durumundakinden farklıdır.
Genel korelasyon katsayısının büyüklüğüne bağlı olarak (genellikle Yunan harfi ile gösterilir) ρ ), korelasyon katsayısı R azalan örneklem büyüklüğü ile artan yanlılığın etkisi ile yanlı bir tahmin verir. Bununla birlikte, bu önyargıyı, örneğin standart sapmayı hesaplarken yaptığımız gibi, karşılık gelen formüle gözlem sayısını değil, serbestlik derecesi sayısını koyduğumuz gibi düzeltmeye çalışmıyoruz. Gerçekte, kovaryansı hesaplamak için kullanılan gözlem sayısının büyüklük üzerinde hiçbir etkisi yoktur.
Standart korelasyon katsayısı, doğrusal bir ilişki ile birbiriyle ilişkili değişkenlerle kullanılmak üzere tasarlanmıştır. Verilerde (aykırı değerler) doğrusal olmama ve / veya hataların varlığı, korelasyon katsayısının yanlış hesaplanmasına yol açar. Veri sorunlarını teşhis etmek için dağılım grafikleri önerilir. Bu, Excel'de hem yatay hem de dikey eksenleri değer eksenleri olarak ele alan tek grafik türüdür. Çizgi grafiği ise sütunlardan birini kategori ekseni olarak tanımlar ve bu da verilerin resmini bozar (Şekil 4).

Pirinç. 4. Regresyon doğruları aynı görünüyor, ancak denklemlerini birbirleriyle karşılaştırın
Çizgi grafiği oluşturmak için kullanılan gözlemler, yatay eksen boyunca eşit uzaklıktadır. Bu eksen boyunca bölme etiketleri yalnızca etiketlerdir, sayısal değerler değildir.
Korelasyon genellikle nedensel bir ilişki olduğu anlamına gelse de, bunun kanıtı olarak kullanılamaz. Bir teorinin doğru mu yanlış mı olduğunu göstermek için istatistik kullanılmaz. Gözlemlerin sonuçlarının birbiriyle çelişen açıklamalarını hariç tutmak için planlanmış deneyler. İstatistikler ayrıca, bu tür deneyler sırasında toplanan bilgileri özetlemek ve kanıtlar temelinde verilen kararın yanlış olma olasılığını ölçmek için de kullanılır.
Bölüm 3 Basit Regresyon
İki değişken ilişkiliyse, yani korelasyon katsayısının değeri örneğin 0,5'ten büyükse, o zaman bir değişkenin bilinmeyen değerini diğerinin bilinen değerinden (biraz doğrulukla) tahmin etmek mümkündür. Şekil l'de verilen verilere dayanarak fiyatın tahmin edilen değerlerini elde etmek için. 5, birkaç olası yoldan herhangi birini kullanabilirsiniz, ancak şekil 2'de gösterileni neredeyse kesinlikle kullanmayacaksınız. 5. Yine de okumalısınız, çünkü başka hiçbir yol korelasyon ve tahmin arasındaki ilişkiyi bu kadar açık bir şekilde gösteremez. Şek. 5, B2:C12 aralığında, on evden oluşan rastgele bir örnektir ve her evin alanı (fit kare olarak) ve satış fiyatı hakkında veri sağlar.

Pirinç. 5. Satış fiyatı tahminleri düz bir çizgi oluşturur
Ortalamayı, standart sapmaları ve korelasyon katsayısını bulun (A14:C18 aralığı). Alan z-skorlarını hesaplayın (E2:E12). Örneğin, E3 hücresi şu formülü içerir: =(B3-$B$14)/$B$15. Tahmini fiyat z puanlarını hesaplayın (F2:F12). Örneğin, F3 hücresi şu formülü içerir: =E3*$B$18. Z puanlarını dolar fiyatlarına dönüştürün (H2:H12). HZ hücresinde formül şöyledir: =F3*$C$15+$C$14.
Öngörülen değerin her zaman ortalamaya, yani 0'a doğru kayma eğiliminde olduğuna dikkat edin. Korelasyon katsayısı sıfıra ne kadar yakınsa, tahmin edilen z-puanı da sıfıra o kadar yakın olur. Örneğimizde, alan ile satış fiyatı arasındaki korelasyon katsayısı 0,67 ve tahmin fiyatı 1,0*0,67'dir, yani. 0.67. Bu, standart sapmanın üçte ikisine eşit, ortalama değerin üzerindeki değerin fazlasına karşılık gelir. Korelasyon katsayısı 0,5'e eşit olsaydı, o zaman tahmin fiyatı 1,0 * 0,5 olurdu, yani. 0,5. Bu, standart sapmanın sadece yarısına eşit, ortalama değerin üzerinde bir değer fazlalığına karşılık gelir. Korelasyon katsayısının değeri idealden farklı olduğunda, yani. -1.0'dan büyük ve 1.0'dan küçükse, yordayıcı değişkenin tahmini, yordayıcı (bağımsız) değişkenin tahmininden kendi ortalama değerine daha yakın olmalıdır. Bu fenomene ortalamaya gerileme veya basitçe gerileme denir.
Regresyon çizgisi denkleminin katsayılarını belirlemek için Excel'de çeşitli işlevler vardır (Excel'de buna eğilim çizgisi denir) y=kx + B. belirlemek için k işleve hizmet eder
=EĞİM(bilinen_y-değerleri; bilinen_x-değerleri)
Burada de tahmin edilen değişkendir ve X bağımsız bir değişkendir. Bu değişken sırasını kesinlikle takip etmelisiniz. Regresyon çizgisinin eğimi, korelasyon katsayısı, değişkenlerin standart sapmaları ve kovaryans yakından ilişkilidir (Şekil 6). INTERCEPT() işlevi, dikey eksende regresyon çizgisi tarafından kesilen değeri döndürür:
= KESME(bilinen_y-değerleri; bilinen_x-değerleri)

Pirinç. 6. Standart sapmalar arasındaki oran, kovaryansı bir korelasyon katsayısına ve regresyon çizgisinin eğimine dönüştürür.
SLOPE() ve INTERCEPT() işlevlerine argüman olarak sağlanan x ve y değerlerinin sayısının aynı olması gerektiğini unutmayın.
Regresyon analizinde başka bir önemli gösterge kullanılır - R 2 (R-kare) veya belirleme katsayısı. arasındaki ilişkinin genel veri değişkenliğine ne gibi bir katkı yaptığını belirler. X Ve de. Excel, CORREL() işleviyle tam olarak aynı bağımsız değişkenleri alan QVPIRSON() işlevine sahiptir.
Aralarında sıfır olmayan bir korelasyon katsayısı olan iki değişkenin varyansı açıkladığı veya varyansı açıkladığı söylenir. Tipik olarak, açıklanan varyans yüzde olarak ifade edilir. Bu yüzden R 2 = 0.81, iki değişkenin varyansının (dağılımının) %81'inin açıklandığı anlamına gelir. Kalan %19'luk kısım rastgele dalgalanmalardan kaynaklanmaktadır.
Excel, hesaplamaları basitleştiren bir TREND işlevine sahiptir. TREND() işlevi:
- verdiğiniz bilinen değerleri alır X ve bilinen değerler de;
- regresyon doğrusunun eğimini ve sabiti (bölüm) hesaplar;
- tahmini değerleri döndürür de regresyon denkleminin bilinen değerlere uygulanmasıyla belirlenir X(Şek. 7).
TREND() işlevi bir dizi işlevidir (bu tür işlevlerle daha önce karşılaşmadıysanız tavsiye ederim).

Pirinç. 7. TREND() işlevini kullanmak, bir çift SLOPE() ve INTERCEPT() işlevi kullanmaya kıyasla hesaplamaları hızlandırmanıza ve basitleştirmenize olanak tanır.
TREND() işlevini G3:G12 hücrelerinde dizi formülü olarak girmek için G3:G12 aralığını seçin, TREND formülünü (SZ:S12;VZ:B12) girin, tuşları basılı tutun
TREND() işlevinin iki bağımsız değişkeni daha vardır: yeni_değerler_x Ve sabit. İlki, gelecek için bir tahmin oluşturmanıza izin verir ve ikincisi, regresyon çizgisini orijinden geçmeye zorlayabilir (DOĞRU değer, Excel'e hesaplanan sabiti, YANLIŞ değer - sabit = 0) kullanmasını söyler. Excel, orijinden geçmesi için bir grafik üzerinde bir regresyon çizgisi çizmenize olanak tanır. Bir dağılım grafiği çizerek başlayın, ardından veri serisi işaretçilerinden birine sağ tıklayın. Açılan bağlam menüsünde öğeyi seçin. Trend çizgisi ekle; bir seçenek seçin Doğrusal; gerekirse paneli aşağı kaydırın, kutuyu işaretleyin Bir kavşak kurun; ilişkili metin kutusunun 0.0 olarak ayarlandığından emin olun.
Üç değişkeniniz varsa ve üçüncüsünün etkisini hariç tutarak ikisi arasındaki korelasyonu belirlemek istiyorsanız, kullanabilirsiniz. kısmi korelasyon. Üniversiteyi bitiren şehir sakinlerinin yüzdesi ile şehir kütüphanelerindeki kitapların sayısı arasındaki ilişkiyle ilgilendiğinizi varsayalım. 50 şehir için veri topladınız, ancak... Sorun şu ki, bu parametrelerin her ikisi de belirli bir şehrin sakinlerinin refahına bağlı olabilir. Tabii ki, sakinlerinin tam olarak aynı refah düzeyine sahip başka 50 şehir bulmak çok zor.
Refahın hem kütüphane desteği hem de üniversite eğitimi üzerindeki etkisini ortadan kaldırmak için istatistiksel yöntemler uygulayarak, ilgilendiğiniz değişkenler arasındaki ilişkiyi, yani kitap sayısı ve mezun sayısı arasındaki ilişkiyi daha iyi ölçebilirsiniz. Diğer değişkenlerin değerleri sabitken iki değişken arasındaki bu koşullu korelasyona kısmi korelasyon denir. Bunu hesaplamanın bir yolu, denklemi kullanmaktır:

Nerede RCB . W- Zenginlik (Zenginlik) değişkeninin hariç tutulan etkisi (sabit değer) ile Kolej (Kolej) ve Kitaplar (Kitaplar) değişkenleri arasındaki korelasyon katsayısı; RCB- Kolej ve Kitap değişkenleri arasındaki korelasyon katsayısı; RCW- Kolej ve Refah değişkenleri arasındaki korelasyon katsayısı; Rbw- Kitaplar ve Refah değişkenleri arasındaki korelasyon katsayısı.
Öte yandan, kısmi korelasyon artık analize dayalı olarak hesaplanabilir, yani tahmin edilen değerler ile bunlarla ilişkili gerçek gözlemler arasındaki farklar (her iki yöntem de Şekil 8'de gösterilmektedir).

Pirinç. 8. Kalan Korelasyon Olarak Kısmi Korelasyon
Korelasyon katsayıları matrisinin (B16: E19) hesaplanmasını basitleştirmek için Excel analiz paketini (menü) kullanın Veri –> Analiz –> Veri analizi). Varsayılan olarak, bu paket Excel'de etkin değildir. Yüklemek için menüden gidin Dosya –> Seçenekler –> eklentiler. Açılan pencerenin alt kısmında Seçeneklermükemmel alanı bul Kontrol, seçme eklentilermükemmel, tıklamak Gitmek. Eklentinin yanındaki kutuyu işaretleyin Analiz paketi. A'yı tıklayın veri analizi, bir seçenek seçin korelasyon. Giriş aralığı olarak $B$2:$D$13 belirtin, kutuyu işaretleyin İlk satırdaki etiketler, çıktı aralığı olarak $B$16:$E$19 belirtin.
Başka bir olasılık, yarı-kısmi bir korelasyon tanımlamaktır. Örneğin, boy ve yaşın kilo üzerindeki etkisini araştırıyorsunuz. Yani iki tahmin değişkeniniz var, boy ve yaş ve bir tahmin değişkeniniz, ağırlık. Bir yordayıcı değişkenin diğeri üzerindeki etkisini hariç tutmak istiyorsunuz, ancak yordayıcı değişken üzerinde değil:
![]()
burada H - Boy (Boy), W - Ağırlık (Kilo), A - Yaş (Yaş); Yarı-kısmi korelasyon katsayısı indeksi, hangi değişkenin hangi değişkenden elendiğini belirtmek için parantez kullanır. Bu durumda, W(H.A) gösterimi, Yaş değişkeninin etkisinin Boy değişkeninden kaldırıldığını ancak Ağırlık değişkeninden kaldırılmadığını gösterir.
Tartışılan konunun önemli olmadığı izlenimi edinilebilir. Sonuçta, en önemli şey genel regresyon denkleminin ne kadar doğru çalıştığıdır, bireysel değişkenlerin açıklanan toplam varyansa göreli katkıları sorunu ise ikincil görünmektedir. Ancak durum böyle değil. Çoklu regresyon denkleminde herhangi bir değişken kullanıp kullanmamayı düşünmeye başladığınız anda konu önem kazanır. Analiz için model seçiminin doğruluğunun değerlendirilmesini etkileyebilir.
Bölüm 4. LINEST() İşlevi
LINEST() işlevi, 10 regresyon analizi istatistiğini döndürür. LINEST() işlevi bir dizi işlevidir. Girmek için beş satır ve iki sütun içeren bir aralık seçin, formülü yazın ve tuşuna basın.
DOT(B2:B21,A2:A21,DOĞRU,DOĞRU)

Pirinç. 9. DOT() işlevi: a) D2:E6 aralığını seçin, b) formülü formül çubuğunda gösterildiği gibi girin, c) tıklayın
DOT() işlevi şunu döndürür:
- regresyon katsayısı (veya eğim, D2 hücresi);
- segment (veya sabit, hücre E3);
- regresyon katsayısı ve sabitlerin standart hataları (aralık D3:E3);
- regresyon için belirleme katsayısı R2 (hücre D4);
- standart tahmin hatası (E4 hücresi);
- Tam regresyon için F testi (D5 hücresi);
- artık kareler toplamı için serbestlik derecesi sayısı (E5 hücresi);
- regresyon kareler toplamı (D6 hücresi);
- artık kareler toplamı (E6 hücresi).
Bu istatistiklerin her birine ve etkileşimlerine bakalım.
standart hata bizim durumumuzda bu, örnekleme hataları için hesaplanan standart sapmadır. Yani bu, genel popülasyonun bir istatistiğe sahip olduğu ve örneklemin başka bir istatistiğe sahip olduğu bir durumdur. Regresyon katsayısını standart hataya bölmek size 2,092/0,818 = 2,559 değerini verir. Başka bir deyişle, 2.092'lik bir regresyon katsayısı, sıfırdan iki buçuk standart hata uzaktadır.
Regresyon katsayısı sıfır ise, tahmin edilen değişkenin en iyi tahmini ortalamasıdır. İki buçuk standart hata oldukça büyük bir sayıdır ve popülasyon için regresyon katsayısının sıfır olmayan bir değere sahip olduğunu güvenle varsayabilirsiniz.
Popülasyondaki gerçek değeri 0,0 ise, işlevi kullanarak 2,092'lik bir örnek regresyon katsayısı elde etme olasılığını belirleyebilirsiniz.
ÖĞRENCİ.DAĞ.PH (t-testi = 2.559; serbestlik derecesi sayısı = 18)
Genel olarak, serbestlik derecesi sayısı = n - k - 1, burada n, gözlem sayısıdır ve k, yordayıcı değişkenlerin sayısıdır.
Bu formül, 0,00987 veya %1'e yuvarlanmış bir değer döndürür. Bize şunu söylüyor: eğer popülasyon için regresyon katsayısı %0 ise, o zaman regresyon katsayısının hesaplanan değeri 2.092 olan 20 kişilik bir örneklem elde etme olasılığı mütevazi bir %1'dir.
F-testi (Şekil 9'daki D5 hücresi), basit ikili regresyon katsayısına ilişkin t-testi ile tam regresyona ilişkin olarak aynı işlevi yerine getirir. F-testi, regresyon için belirleme katsayısı R2'nin gerçekten de popülasyonda 0.0 değerine sahip olduğu hipotezini reddetmek için yeterince büyük olup olmadığını test etmek için kullanılır; bu, öngörücü ve yordayıcı değişken tarafından açıklanan varyansın olmadığını gösterir. . Yalnızca bir yordayıcı değişken olduğunda, F testi tam olarak t testinin karesine eşittir.
Şimdiye kadar aralık değişkenlerini ele aldık. Erkek ve Kadın veya Sürüngen, Amfibi ve Balık gibi basit isimler olan birden fazla değer alabilen değişkenleriniz varsa, bunları sayısal bir kod olarak gösterin. Bu tür değişkenlere nominal denir.
R2 istatistikleri açıklanan varyansın oranını ölçer.
Tahminin standart hatası.Şek. Tablo 4.9, Boy değişkeni ile ilişkisi temelinde elde edilen Ağırlık değişkeninin tahmin edilen değerlerini göstermektedir. E2:E21 aralığı, Ağırlık değişkeni için artıkların değerlerini içerir. Daha kesin olarak, bu artıklara hatalar denir - dolayısıyla tahminin standart hatası terimi takip eder.

Pirinç. 10. Hem R 2 hem de tahminin standart hatası, regresyon kullanılarak elde edilen tahminlerin doğruluğunu ifade eder.
Tahminin standart hatası ne kadar küçük olursa, regresyon denklemi o kadar doğru olur ve denklemdeki herhangi bir tahminin gerçek gözlemle eşleşmesini o kadar yakın beklersiniz. Tahminin standart hatası, bu beklentileri ölçmek için bir yol sağlar. Belirli bir yüksekliğe sahip kişilerin %95'inin ağırlığı şu aralıkta olacaktır:
(yükseklik * 2,092 - 3,591) ± 2,092 * 21,118
F-istatistiği gruplar arası varyansın grup içi varyansa oranıdır. Bu isim, 20. yüzyılın başında varyans analizini (ANOVA, Analysis of Variance) geliştiren Sir'in onuruna istatistikçi George Snedecor tarafından tanıtıldı.
Belirleme katsayısı R2, regresyonla ilişkili toplam kareler toplamının oranını ifade eder. Değer (1 - R 2), artıklarla ilişkili toplam kareler toplamının oranını ifade eder - tahmin hataları. F testi, DOT işlevi (Şekil 11'deki F5 hücresi), kareler toplamı (G10:J11 aralığı) ve varyans kesirleri (G14:J15 aralığı) kullanılarak elde edilebilir. Formüller ekteki Excel dosyasında incelenebilir.

Pirinç. 11. F-kriterinin hesaplanması
Nominal değişkenler kullanılırken yapay kodlama kullanılır (Şekil 12). Değerleri kodlamak için 0 ve 1 değerlerini kullanmak uygundur. F olasılığı, işlev kullanılarak hesaplanır:
F.DAĞ.PH(K2;I2;I3)
Burada, F.DIST.RT() işlevi, değeri I2 ve I3 hücrelerinde verilen serbestlik derecelerine sahip iki veri kümesi için merkezi F dağılımını (Şekil 13) takiben bir F testi elde etme olasılığını döndürür; K2 hücresinde verilen değer ile aynıdır.

Pirinç. 12. Kukla değişkenler kullanılarak yapılan regresyon analizi

Pirinç. 13. λ = 0 için merkezi F dağılımı
Bölüm 5 Çoklu Regresyon
Tek tahmin değişkenli basit ikili regresyondan çoklu regresyona geçtiğinizde, bir veya daha fazla tahmin değişkeni eklersiniz. Tahmin değişkeni değerlerini, iki tahmin edici için A ve B sütunları veya üç tahmin edici için A, B ve C gibi bitişik sütunlarda saklayın. LINEST() işlevini içeren bir formül girmeden önce, beş satır ve öngörücü değişken olduğu kadar çok sütun ve ayrıca sabit için bir tane daha seçin. İki yordayıcı değişkenli regresyon durumunda aşağıdaki yapı kullanılabilir:
DOT(A2: A41; B2: C41;; DOĞRU)
Benzer şekilde, üç değişken durumunda:
DOT(A2:A61;B2:D61;;DOĞRU)
Diyelim ki, aterotromboza neden olan aterosklerotik plakların oluşumundan sorumlu olduğu düşünülen düşük yoğunluklu lipoproteinler olan LDL seviyeleri üzerindeki yaş ve diyetin olası etkisini incelemek istiyorsunuz (Şekil 14).

Pirinç. 14. Çoklu Regresyon
Çoklu regresyonun (F13 hücresinde gösterilen) R2'si, herhangi bir basit regresyonun (E4, H4) R2'sinden büyüktür. Çoklu regresyon, aynı anda birden fazla öngörücü değişken kullanır. Bu durumda, R2 hemen hemen her zaman artar.
Bir tahmin değişkeni olan herhangi bir basit doğrusal regresyon denklemi için, tahmin edici değerler ile tahmin edici değişken değerleri arasında her zaman mükemmel bir korelasyon olacaktır, çünkü böyle bir denklemde tahmin değerleri bir sabitle çarpılır ve başka bir sabit eklenir. her ürüne Bu etki çoklu regresyonda korunmaz.
Çoklu regresyon için LINEST() tarafından döndürülen sonuçların görüntülenmesi (Şekil 15). Regresyon katsayıları, LINEST() tarafından döndürülen sonuçların bir parçası olarak görüntülenir. değişkenlerin ters sırasına göre(G–H–I, C–B–A'ya karşılık gelir).

Pirinç. 15. Çalışma yaprağında katsayılar ve standart hataları ters sırayla gösterilir.
Tek bir yordayıcı değişkenle yapılan regresyon analizinde kullanılan ilke ve prosedürler, çoklu yordayıcı değişkenleri hesaba katmak için kolayca uyarlanır. Görünüşe göre, bu uyarlamanın çoğu, yordayıcı değişkenlerin birbiri üzerindeki etkisinin ortadan kaldırılmasına bağlıdır. İkincisi, özel ve yarı özel korelasyonlarla ilişkilidir (Şekil 16).

Pirinç. 16. Çoklu regresyon artıkların ikili regresyonu ile ifade edilebilir (Excel dosyasındaki formüllere bakın)
Excel'de t ve F dağılımları hakkında bilgi sağlayan işlevler vardır. STUDENT.DAĞ() ve F.DAĞ() gibi adları bir DIST parçası içeren işlevler, bağımsız değişken olarak bir t- veya F-testi alır ve belirtilen değeri gözlemleme olasılığını döndürür. STUDENT.TERS() ve F.TERS() gibi adları bir OBR parçası içeren işlevler, bağımsız değişken olarak bir olasılık değeri alır ve belirtilen olasılığa karşılık gelen bir ölçüt değeri döndürür.
Kuyruk bölgelerinin kenarlarını kesen t dağılımının kritik değerlerini aradığımızdan, bu olasılığa karşılık gelen bir değer döndüren STUDENT.INV() işlevlerinden birine argüman olarak %5 geçiyoruz. (Şek. 17, 18).

Pirinç. 17. İki kuyruklu t-testi

Pirinç. 18. Tek kuyruklu t-testi
Tek kuyruklu bir alfa bölgesi durumunda bir karar kuralı oluşturarak, testin istatistiksel gücünü artırırsınız. Deneyinize başladığınızda, pozitif (veya negatif) bir regresyon katsayısı beklemek için her türlü nedeninizin olduğundan eminseniz, o zaman tek uçlu bir test yapmalısınız. Bu durumda, popülasyonda sıfır regresyon katsayısı hipotezini reddederek doğru kararı verme olasılığınız daha yüksek olacaktır.
İstatistikçiler terimi kullanmayı tercih ediyor yönlendirilmiş test terim yerine tek kuyruk testi ve terim yönlendirilmemiş test terim yerine iki kuyruklu test. Yönlü ve yönsüz terimleri dağılımın kuyruklarının doğasından ziyade hipotez tipini vurguladıkları için tercih edilir.
Modellerin karşılaştırılmasına dayalı olarak öngörücülerin etkisini değerlendirmeye yönelik bir yaklaşım.Şek. Şekil 19, Diet değişkeninin regresyon denklemine katkısını test eden bir regresyon analizinin sonuçlarını göstermektedir.

Pirinç. 19. Sonuçlarındaki farklılıkları kontrol ederek iki modeli karşılaştırma
LINEST() sonuçları (H2:K6 aralığı), Diyet, Yaş ve HDL'deki LDL değişkenini gerileyen tam model dediğim şeyle ilişkilidir. H9:J13 aralığında, tahmin değişkeni Diyet dikkate alınmadan hesaplamalar sunulur. Ben buna sınırlı model diyorum. Tam modelde, LDL bağımlı değişkenindeki varyansın %49,2'si yordayıcı değişkenler tarafından açıklanmaktadır. Sınırlı modelde, LDL'nin yalnızca %30,8'i Yaş ve HDL ile açıklanmaktadır. Diyet değişkeninin modelden çıkarılmasından kaynaklanan R 2 kaybı 0,183'tür. G15:L17 aralığında, Diyet değişkeninin etkisinin yalnızca 0,0288 olasılıkla rastgele olduğunu gösteren hesaplamalar yapılmıştır. Kalan %97,1'de Diyetin LDL üzerinde etkisi vardır.
Bölüm 6. Regresyon analizine ilişkin varsayımlar ve uyarılar
"Varsayım" terimi kesin olarak tanımlanmamıştır ve kullanım şekli, varsayım karşılanmazsa tüm analizin sonuçlarının en azından sorgulanabilir veya muhtemelen geçersiz olduğunu düşündürür. Aslında, varsayımın ihlalinin resmi temelden değiştirdiği durumlar olsa da, durum böyle değildir. Ana varsayımlar şunlardır: a) Y değişkeninin artıkları, regresyon çizgisi boyunca X'in herhangi bir noktasında normal olarak dağılır; b) Y değerleri, X değerlerine doğrusal olarak bağlıdır; c) kalıntıların varyansı her bir X noktasında yaklaşık olarak aynıdır; d) kalıntılar arasında ilişki yoktur.
Varsayımlar önemli bir rol oynamıyorsa, istatistikçiler varsayımın ihlaliyle ilgili olarak analizin sağlamlığından bahseder. Özellikle, grup ortalamaları arasındaki farkları test etmek için regresyon kullandığınızda, Y değerlerinin - ve dolayısıyla artıkların - normal olarak dağıldığı varsayımı önemli değildir: testler, normallik varsayımının ihlaline karşı dayanıklıdır. Grafikleri kullanarak verileri analiz etmek önemlidir. Örneğin, eklentiye dahil Veri analizi alet gerileme.
Veriler doğrusal regresyon varsayımlarına uymuyorsa, emrinizde başka doğrusal olmayan yaklaşımlar vardır. Bunlardan biri lojistik regresyondur (Şekil 20). Tahmin edici değişkenin üst ve alt sınırlarının yakınında, doğrusal regresyon gerçekçi olmayan tahminlerle sonuçlanır.

Pirinç. 20. Lojistik regresyon
Şek. Şekil 6.8, yıllık gelir ile bir ev satın alma olasılığı arasındaki ilişkiyi araştırmayı amaçlayan iki veri analizi yönteminin sonuçlarını göstermektedir. Açıkçası, artan gelirle birlikte satın alma olasılığı artacaktır. Grafikler, doğrusal regresyon kullanarak bir ev satın alma olasılığını tahmin eden sonuçlar ile farklı bir yaklaşım kullanarak elde edebileceğiniz sonuçlar arasındaki farkları tespit etmeyi kolaylaştırır.
İstatistiksel tabirle, gerçekte doğru olduğu halde boş hipotezin reddedilmesi Tip I hata olarak adlandırılır.
eklentide Veri analizi kullanıcının istenen dağılım şeklini (örneğin, Normal, Binom veya Poisson) ve ayrıca ortalama ve standart sapmayı belirlemesine izin veren, rastgele sayı üretimi için kullanışlı bir araç sunulur.
STUDENT.DIST() ailesinin işlevleri arasındaki farklar. Excel 2010'dan başlayarak, belirli bir t-testi değerinin soluna ve/veya sağına bir dağılımın kesirini döndüren üç farklı fonksiyon biçimi mevcuttur. STUDENT.DAĞ() işlevi, belirttiğiniz t-testi değerinin solundaki dağılım eğrisi altındaki alanın oranını döndürür. Diyelim ki 36 gözleminiz var, dolayısıyla analiz edilecek serbestlik derecesi sayısı 34 ve t-testi değeri 1,69. Bu durumda, formül
ÖĞRENCİ.DAĞ(+1,69;34;DOĞRU)
0,05 veya %5 değerini döndürür (Şekil 21). STUDENT.DAĞ() için üçüncü bağımsız değişken DOĞRU veya YANLIŞ olabilir. DOĞRU olarak ayarlanırsa işlev, verilen t-testinin solundaki eğrinin altındaki kümülatif alanı kesir olarak ifade ederek döndürür. YANLIŞ ise işlev, t-testine karşılık gelen noktada eğrinin göreli yüksekliğini döndürür. STUDENT.DAĞ() işlevinin diğer sürümleri - STUDENT.DIST.PX() ve STUDENT.DIST.2X() - bağımsız değişken olarak yalnızca t-testi değerini ve serbestlik derecesi sayısını alır ve üçüncü bir bağımsız değişken gerektirmez .

Pirinç. 21. Dağılımın sol kuyruğundaki daha koyu gölgeli alan, büyük pozitif t-testi değerinin solundaki eğri altındaki alanın oranına karşılık gelir.
t testinin sağındaki alanı belirlemek için aşağıdaki formüllerden birini kullanın:
1 - ÖĞRENCİ.DAĞ (1, 69; 34; DOĞRU)
ÖĞRENCİ.DAĞ.PH(1.69;34)
Eğrinin altındaki toplam alan %100 olmalıdır, bu nedenle fonksiyon tarafından döndürülen t-testi değerinin solundaki alan kesrinin 1'den çıkarılması, t-testi değerinin sağındaki alan kesrini verir. STUDENT.DIST.RH() işlevini kullanarak ilgilendiğiniz alan kesirini doğrudan elde etmeyi daha tercih edilebilir bulabilirsiniz; burada RH, dağılımın sağ kuyruğu anlamına gelir (Şekil 22).

Pirinç. 22. Yön testi için %5 alfa alanı
STUDENT.DIST() veya STUDENT.DIST.PH() işlevlerinin kullanılması, yönlendirilmiş bir çalışma hipotezi seçtiğiniz anlamına gelir. Yönlü çalışma hipotezi, alfa değerini %5'e ayarlamakla birleştiğinde, %5'in tamamını dağılımların sağ kuyruğuna koyduğunuz anlamına gelir. Sıfır hipotezini yalnızca t-testi değerinizin elde edilme olasılığı %5 veya daha azsa reddetmeniz gerekecektir. Yönlü hipotezler genellikle daha hassas istatistiksel testlerle sonuçlanır (bu daha yüksek hassasiyet aynı zamanda daha büyük istatistiksel güç olarak da adlandırılır).
Yönsüz bir test ile alfa değeri aynı %5 düzeyinde kalır, ancak dağılım farklı olacaktır. İki sonuca izin vermeniz gerektiğinden, yanlış pozitif olasılığı dağılımın iki kuyruğu arasında dağıtılmalıdır. Bu olasılığı eşit olarak dağıtmak genellikle kabul edilir (Şekil 23).

Önceki örnekte olduğu gibi elde edilen aynı t-testi değerini ve aynı sayıda serbestlik derecesini kullanarak, formülü kullanın
ÖĞRENCİ MESAFESİ 2X(1.69;34)
Belirli bir neden olmaksızın, STUDENT.DIST.2X() işlevi, ilk bağımsız değişkeni olarak negatif bir t-testi değeri verilirse #SAYI!
Örnekler farklı sayıda veri içeriyorsa, pakette yer alan farklı varyanslarla iki örnekli t-testini kullanın Veri analizi.
Bölüm 7 Grup Ortalamaları Arasındaki Farkları Test Etmek İçin Regresyonu Kullanma
Önceden yordayıcı değişkenler olarak adlandırılan değişkenler, bu bölümde sonuç değişkenleri olarak anılacak ve yordayıcı değişkenler yerine faktör değişkenleri terimi kullanılacaktır.
Nominal bir değişkeni kodlamanın en basit yaklaşımı şudur: sahte kodlama(Şek. 24).

Pirinç. 24. Kukla kodlamaya dayalı regresyon analizi
Herhangi bir tür sahte kodlama kullanırken, aşağıdaki kurallara uyulmalıdır:
- Yeni veriler için ayrılan sütun sayısı, eksi faktör düzeyleri sayısına eşit olmalıdır
- Her vektör bir faktör seviyesini temsil eder.
- Genellikle kontrol grubu olan bir seviyedeki denekler, tüm vektörlerde 0 kodunu alırlar.
F2:H6 =DOT(A2:A22;C2:D22;;DOĞRU) hücrelerindeki formül, regresyon istatistiklerini döndürür. Karşılaştırma için, Şek. Şekil 24, araç tarafından döndürülen geleneksel varyans analizinin sonuçlarını gösterir. Tek yönlü varyans analiziüst yapılar Veri analizi.
Efekt kodlaması. Adı verilen başka bir kodlama türünde efekt kodlama, her grubun ortalaması, grup ortalamalarının ortalaması ile karşılaştırılır. Etki kodlamasının bu yönü, tüm kod vektörlerinde aynı kodu alan bir grup için kod olarak 0 yerine -1 kullanılmasından kaynaklanmaktadır (Şekil 25).

Pirinç. 25. Efekt Kodlama
Kukla kodlama kullanıldığında, LINEST() tarafından döndürülen sabitin değeri, tüm vektörlerde (genellikle kontrol grubu) sıfır kod atanan grubun ortalamasıdır. Efekt kodlaması durumunda, sabit genel ortalamaya eşittir (J2 hücresi).
Genel doğrusal model, ortaya çıkan değişkenin değer bileşenlerini kavramsallaştırmanın kullanışlı bir yoludur:
Y ij = μ + α j + ε ij
Bu formülde Latin harfleri yerine Yunan harflerinin kullanılması, örneklerin alındığı popülasyona atıfta bulunduğunu vurgulamaktadır, ancak yayınlanan popülasyondan alınan örneklere atıfta bulunduğunu belirtmek için yeniden yazılabilir:
Y ij = Y̅ + a j + e ij
Buradaki fikir, her Y ij gözleminin aşağıdaki üç bileşenin toplamı olarak görülebileceğidir: genel ortalama, μ; işleme etkisi j ve j ; bireysel nicel gösterge Yij'nin genel ortalamanın birleşik değerinden ve j'inci tedavinin etkisinden sapmasını temsil eden eij değeri (Şekil 26). Regresyon denkleminin amacı, artıkların karelerinin toplamını en aza indirmektir.

Pirinç. 26. Genel Doğrusal Modelin Bileşenlerine Ayrıştırılmış Gözlemler
Faktor analizi. Ortaya çıkan değişken ile aynı anda iki veya daha fazla faktör arasındaki ilişki araştırılıyorsa, bu durumda faktör analizinin kullanılmasından söz edilir. Tek yönlü varyans analizine bir veya daha fazla faktör eklemek, istatistiksel gücü artırabilir. Tek yönlü ANOVA'da, sonuç değişkenindeki bir faktöre atfedilemeyen varyasyon, artık ortalama kareye dahil edilir. Ancak bu varyasyonun başka bir faktörle ilgili olması da pekala mümkündür. Daha sonra bu varyasyon, azalması F testinin değerlerinde bir artışa ve dolayısıyla testin istatistiksel gücünde bir artışa yol açan ortalama karesel hatadan çıkarılabilir. üst yapı Veri analizi iki faktörün aynı anda işlenmesini sağlayan bir araç içerir (Şekil 27).

Pirinç. 27. Tekrarlar Analiz Paketi ile Araç İki Yönlü Varyans Analizi
Bu şekilde kullanılan varyans analizi aracı, sonuçta ortaya çıkan değişkenin ortalamasını ve varyansını ve ayrıca tasarıma dahil edilen her grup için sayaç değerini döndürmesi açısından yararlıdır. Masa varyans analizi ANOVA aracının tek yönlü sürümünün çıktısında olmayan iki parametreyi görüntüler. Varyasyon Kaynaklarına Dikkat Edin Örnek Ve sütunlar 27 ve 28. satırlarda. Değişkenlik kaynağı sütunlar cinsiyete atıfta bulunur. Varyasyon Kaynağı Örnek değerleri farklı satırları kaplayan herhangi bir değişkeni ifade eder. Şek. 27, CourseLech1 grubu için değerler 2-6 satırlarında, CourseLech2 grubu 7-11 satırlarında ve CourseLech3 grubu 12-16 satırlarındadır.
Ana nokta, hem Cinsiyet (E28 hücresinde Sütunlar olarak etiketlenmiştir) hem de Tedavinin (E27 hücresinde Örnek olarak etiketlenmiştir) ANOVA tablosuna varyasyon kaynakları olarak dahil edilmesidir. Erkeklerin ortalamaları kadınların ortalamalarından farklıdır ve bu bir varyasyon kaynağı oluşturur. Üç tedavinin ortalamaları da farklıdır - işte başka bir varyasyon kaynağı. Cinsiyet ve Muamele değişkenlerinin birleşik etkisine atıfta bulunan Etkileşim adlı üçüncü bir kaynak da vardır.
Bölüm 8
Kovaryans Analizi veya ANCOVA (Analiz of Covariation), yanlılığı azaltır ve istatistiksel gücü artırır. Size regresyon denkleminin güvenilirliğini değerlendirmenin yollarından birinin F testleri olduğunu hatırlatmama izin verin:
F = MS Regresyon/MS Kalıntı
burada MS (Ortalama Kare) ortalama karedir ve Regresyon ve Artık endeksleri sırasıyla regresyon ve artık bileşenleri gösterir. MS Kalıntı, aşağıdaki formül kullanılarak hesaplanır:
MS Artık = SS Artık / df Artık
burada SS (Kareler Toplamı) karelerin toplamıdır ve df serbestlik derecesi sayısıdır. Bir regresyon denklemine kovaryans eklediğinizde, toplam kareler toplamının bir kısmı SS ResiduaI'e değil, SS Regression'a dahil edilir. Bu, SS Kalıntı l'de ve dolayısıyla MS Kalıntısında bir azalmaya yol açar. MS Kalıntısı ne kadar küçük olursa, F-testi o kadar büyük olur ve ortalamalar arasında hiçbir fark olmadığına dair sıfır hipotezini reddetme olasılığınız o kadar artar. Sonuç olarak, ortaya çıkan değişkenin oynaklığını yeniden dağıtırsınız. ANOVA'da kovaryans dikkate alınmadığında değişkenlik hataya girer. Ancak ANCOVA'da, değişkenliğin daha önce hataya atfedilen kısmı ortak değişkene atanır ve SS Regresyonunun bir parçası olur.
Aynı veri setinin önce ANOVA ve ardından ANCOVA ile analiz edildiği bir örnek düşünün (Şekil 28).

Pirinç. 28. ANOVA analizi, regresyon denklemi kullanılarak elde edilen sonuçların güvenilir olmadığını gösteriyor
Çalışma, kas gücünü geliştiren fiziksel egzersiz ile beyin aktivitesini harekete geçiren bilişsel egzersizin (bulmaca bulmacaları) göreceli etkilerini karşılaştırıyor. Denekler, deneyin başında her iki grubun da aynı koşullarda olması için rastgele iki gruba ayrıldı. Üç ay sonra deneklerin bilişsel özellikleri ölçüldü. Bu ölçümlerin sonuçları sütun B'de gösterilmektedir.
A2:C21 aralığı, efekt kodlamasını kullanarak analiz gerçekleştirmek için LINEST() işlevine iletilen ilk verileri içerir. LINEST() işlevinin sonuçları, E2:F6 aralığında gösterilir; burada E2 hücresi, etki vektörüyle ilişkili regresyon katsayısını gösterir. E8 hücresi t-testi = 0,93 içerir ve E9 hücresi bu t-testinin güvenilirliğini test eder. E9 hücresindeki değer, popülasyonda grup ortalamaları eşitse, bu deneyde gözlemlenen grup ortalamaları arasındaki farkla karşılaşma olasılığının %36 olduğunu gösterir. Sadece birkaçı bu sonucun istatistiksel olarak anlamlı olduğunu düşünüyor.
Şek. Şekil 29, analize bir ortak değişken eklendiğinde ne olduğunu göstermektedir. Bu durumda, veri kümesine her deneğin yaşını ekledim. Ortak değişkeni kullanan regresyon denklemi için belirleme katsayısı R2 0,80'dir (F4 hücresi). Ortak değişkeni kullanmadan elde ettiğim ANOVA sonuçlarını yeniden ürettiğim F15:G19 aralığındaki R2 değeri yalnızca 0,05'tir (F17 hücresi). Bu nedenle, bir ortak değişken içeren bir regresyon denklemi, Bilişsel Puan değişkeninin değerlerini tek başına Etki vektörünü kullanmaktan çok daha doğru bir şekilde tahmin eder. ANCOVA için, F5 hücresinde görüntülenen F testi değerini rastgele elde etme olasılığı %0,01'den azdır.

Pirinç. 29. ANCOVA tamamen farklı bir resim getiriyor
Regresyon analizi, istatistiksel araştırmaların en popüler yöntemlerinden biridir. Bağımsız değişkenlerin bağımlı değişken üzerindeki etki derecesini belirlemek için kullanılabilir. Microsoft Excel'in işlevselliği, bu tür analizleri gerçekleştirmek için tasarlanmış araçlara sahiptir. Ne olduklarına ve nasıl kullanılacağına bir göz atalım.
Analiz paketini bağlama
Ancak regresyon analizi yapmanızı sağlayan fonksiyonu kullanabilmeniz için öncelikle Analiz Paketini aktif hale getirmeniz gerekmektedir. Ancak o zaman bu prosedür için gerekli araçlar Excel şeridinde görünecektir.
- "Dosya" sekmesine gidin.
- "Ayarlar" bölümüne gidin.
- Excel Seçenekleri penceresi açılır. "Eklentiler" alt bölümüne gidin.
- Açılan pencerenin en alt kısmında "Yönetim" bloğundaki anahtarı farklı bir konumdaysa "Excel Eklentileri" konumuna yeniden düzenliyoruz. "Git" düğmesine tıklayın.
- Excel eklentileri penceresi açılır. "Analiz Paketi"nin yanındaki kutuyu işaretleyin. "Tamam" düğmesine tıklayın.

Şimdi, "Analiz" araç bloğundaki şeritte "Veri" sekmesine gittiğimizde, yeni bir düğme göreceğiz - "Veri Analizi".

Regresyon analizi türleri
Birkaç tür regresyon vardır:
- parabolik;
- güç;
- logaritmik;
- üstel;
- gösteri;
- hiperbolik;
- doğrusal regresyon.
Son tür regresyon analizinin Excel'de uygulanması hakkında daha sonra daha ayrıntılı olarak konuşacağız.
Excel'de Doğrusal Regresyon
Aşağıda, örnek olarak, sokaktaki ortalama günlük hava sıcaklığını ve ilgili iş günü için mağaza müşteri sayısını gösteren bir tablo bulunmaktadır. Hava sıcaklığı şeklindeki hava koşullarının bir perakende kuruluşunun katılımını tam olarak nasıl etkileyebileceğini regresyon analizi yardımıyla öğrenelim.
Genel lineer regresyon denklemi şuna benzer: Y = a0 + a1x1 + ... + axk. Bu formülde Y, faktörlerin etkisini incelemeye çalıştığımız değişken anlamına gelir. Bizim durumumuzda bu, alıcıların sayısıdır. X'in değeri, değişkeni etkileyen çeşitli faktörlerdir. a parametreleri regresyon katsayılarıdır. Yani, belirli bir faktörün önemini belirlerler. İndeks k, aynı faktörlerin toplam sayısını belirtir.


Analiz sonuçları analizi
Regresyon analizinin sonuçları, ayarlarda belirtilen yerde tablo şeklinde görüntülenir.

Ana göstergelerden biri R-karesidir. Modelin kalitesini gösterir. Bizim durumumuzda bu katsayı 0,705 veya yaklaşık %70,5'tir. Bu kabul edilebilir bir kalite seviyesidir. 0,5'ten küçük bir ilişki kötüdür.
Bir diğer önemli gösterge, "Y-kesişimi" çizgisi ile "Katsayılar" sütununun kesiştiği hücrede bulunur. Burada Y'nin hangi değere sahip olacağı belirtilir ve bizim durumumuzda bu, diğer tüm faktörler sıfıra eşit olan alıcı sayısıdır. Bu tabloda bu değer 58.04'tür.
"Değişken X1" ve "Katsayılar" sütununun kesiştiği noktadaki değer, Y'nin X'e bağımlılık düzeyini gösterir. Bizim durumumuzda bu, mağaza müşterisi sayısının sıcaklığa bağımlılık düzeyidir. 1.31 katsayısı oldukça yüksek bir etki göstergesi olarak kabul edilir.
Gördüğünüz gibi, Microsoft Excel kullanarak bir regresyon analizi tablosu oluşturmak oldukça kolaydır. Ancak çıktıda elde edilen verilerle yalnızca eğitimli bir kişi çalışabilir ve bunların özünü anlayabilir.
Sorunu çözmenize yardımcı olabildiğimize sevindik.
Sorunun özünü ayrıntılı olarak açıklayarak yorumlarda sorunuzu sorun. Uzmanlarımız mümkün olan en kısa sürede yanıt vermeye çalışacaktır.
Bu makale size yardımcı oldu mu?
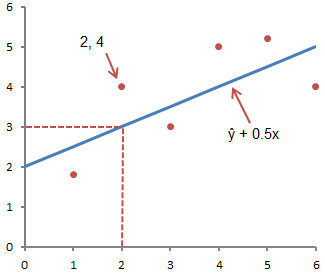
Doğrusal regresyon yöntemi, bir dizi sıralı çifte (x, y) en iyi uyan düz bir çizgiyi tanımlamamızı sağlar. Doğrusal denklem olarak bilinen düz bir çizginin denklemi aşağıda verilmiştir:
ŷ, belirli bir x değeri için y'nin beklenen değeridir,
x - bağımsız değişken,
a - düz bir çizgi için y eksenindeki segment,
b düz çizginin eğimidir.
Aşağıdaki şekilde, bu kavram grafiksel olarak temsil edilmektedir:
Yukarıdaki şekil, ŷ =2+0,5x denklemiyle açıklanan bir çizgiyi göstermektedir. Y ekseni üzerindeki segment, çizginin y ekseni ile kesişme noktasıdır; bizim durumumuzda, a = 2. Doğrunun eğimi, b, çizgi yükselişinin çizgi uzunluğuna oranı, 0,5 değerine sahiptir. Pozitif bir eğim, çizginin soldan sağa doğru yükseldiği anlamına gelir. b = 0 ise çizgi yataydır, yani bağımlı ve bağımsız değişkenler arasında ilişki yoktur. Başka bir deyişle, x'in değerini değiştirmek y'nin değerini etkilemez.
ŷ ve y genellikle karıştırılır. Grafik, verilen denkleme göre 6 sıralı nokta çiftini ve bir çizgiyi göstermektedir.
Bu şekil x = 2 ve y = 4 sıralı çiftine karşılık gelen noktayı göstermektedir. X= 2 ŷ'dir. Bunu aşağıdaki denklemle doğrulayabiliriz:
ŷ = 2 + 0,5х =2 +0,5(2) =3.
y değeri gerçek noktadır ve ŷ değeri, belirli bir x değeri için doğrusal bir denklem kullanılarak beklenen y değeridir.
Bir sonraki adım, sıralı çiftler kümesiyle en iyi eşleşen doğrusal denklemi belirlemektir, bundan önceki makalede en küçük kareler yöntemini kullanarak denklemin şeklini belirlediğimizde bahsetmiştik.
Doğrusal Regresyonu Tanımlamak için Excel'i Kullanma
Excel'de yerleşik olan regresyon analizi aracını kullanmak için eklentiyi etkinleştirmeniz gerekir. Analiz paketi. Sekmesine tıklayarak bulabilirsiniz Dosya -> Seçenekler(2007+), görüntülenen iletişim kutusunda Seçeneklermükemmel sekmeye git eklentiler sahada Kontrol seçmek eklentilermükemmel ve tıklayın Gitmek. Görünen pencerede, yanındaki kutuyu işaretleyin. analiz paketi, tıklamak TAMAM.
sekmesinde Veri grup içinde Analiz yeni bir düğme görünecek Veri analizi.
Eklentinin nasıl çalıştığını göstermek için, bir erkek ve bir kızın banyoda aynı masayı paylaştığı önceki makaledeki verileri kullanalım. Banyo örneğimizin verilerini boş bir sayfanın A ve B sütunlarına girin.
sekmeye git Veri, grup içinde Analiz tıklamak Veri analizi. Görünen pencerede Veri analizi seçme gerilemeşekilde gösterildiği gibi ve Tamam'a tıklayın.
Pencerede gerekli regresyon parametrelerini ayarlayın gerileme, resimde gösterildiği gibi:
Tıklamak TAMAM. Aşağıdaki şekil elde edilen sonuçları göstermektedir:
Bu sonuçlar, önceki makaledeki bağımsız hesaplamalarla elde ettiğimiz sonuçlarla tutarlıdır.
Regresyon analizi, bir parametrenin bir veya daha fazla bağımsız değişkene bağımlılığını göstermenizi sağlayan istatistiksel bir araştırma yöntemidir. Bilgisayar öncesi çağda, özellikle büyük miktarda veri söz konusu olduğunda kullanımı oldukça zordu. Bugün, Excel'de bir regresyon oluşturmayı öğrendikten sonra, karmaşık istatistiksel sorunları birkaç dakika içinde çözebilirsiniz. Aşağıda ekonomi alanından belirli örnekler verilmiştir.
regresyon türleri
Kavramın kendisi, 1886'da Francis Galton tarafından matematiğe tanıtıldı. Gerileme olur:
- doğrusal;
- parabolik;
- güç;
- üstel;
- hiperbolik;
- gösterici;
- logaritmik.
örnek 1
6 sanayi işletmesinde emekli ekip üyelerinin sayısının ortalama maaşa bağımlılığını belirleme problemini ele alalım.
Görev. Altı işletmede ortalama aylık maaşı ve kendi isteğiyle işten ayrılan çalışan sayısını inceledik. Tablo biçiminde elimizde:
6 işletmede işten çıkarılan işçi sayısının ortalama maaşa bağımlılığını belirleme sorunu için, regresyon modeli Y = a0 + a1 × 1 + ... + akxk denklemi biçimindedir, burada хi, etkileyen değişkenler, ai regresyon katsayılarıdır ve k faktör sayısıdır.
Bu görev için Y, ayrılan çalışanların göstergesidir ve etkileyen faktör, X ile gösterdiğimiz maaştır.
"Excel" elektronik tablosunun yeteneklerini kullanma
Excel'deki regresyon analizinden önce, mevcut tablo verilerine yerleşik işlevlerin uygulanması gerekir. Ancak, bu amaçlar için, çok kullanışlı bir eklenti olan "Analysis Toolkit" kullanmak daha iyidir. Etkinleştirmek için ihtiyacınız olan:
- "Dosya" sekmesinden "Seçenekler" bölümüne gidin;
- açılan pencerede "Eklentiler" satırını seçin;
- "Yönetim" satırının sağında, altta bulunan "Git" düğmesine tıklayın;
- "Analiz Paketi" adının yanındaki kutuyu işaretleyin ve "Tamam"a tıklayarak işlemlerinizi onaylayın.
Her şey doğru yapılırsa, Excel çalışma sayfasının üzerinde bulunan Veri sekmesinin sağ tarafında istenen düğme görünecektir.
Excel'de Doğrusal Regresyon
Artık ekonometrik hesaplamalar yapmak için gerekli tüm sanal araçlara sahip olduğumuza göre, problemimizi çözmeye başlayabiliriz. Bunun için:
- "Veri Analizi" düğmesine tıklayın;
- açılan pencerede "Gerileme" düğmesine tıklayın;
- görünen sekmede Y (işten ayrılan çalışan sayısı) ve X (maaşları) için değer aralığını girin;
- İşlemlerimizi "Tamam" butonuna basarak onaylıyoruz.
Sonuç olarak, program elektronik tablonun yeni bir sayfasını regresyon analizi verileriyle otomatik olarak dolduracaktır. Not! Excel, bu amaçla tercih ettiğiniz konumu manuel olarak ayarlama yeteneğine sahiptir. Örneğin, Y ve X değerlerinin olduğu aynı sayfa veya hatta bu tür verileri depolamak için özel olarak tasarlanmış yeni bir çalışma kitabı olabilir.
R-kare için regresyon sonuçlarının analizi
Excel'de, ele alınan örneğin verilerinin işlenmesi sırasında elde edilen veriler şöyle görünür:
Öncelikle R-kare değerine dikkat etmelisiniz. Belirleme katsayısıdır. Bu örnekte, R-kare = 0,755 (%75,5), yani modelin hesaplanan parametreleri, ele alınan parametreler arasındaki ilişkiyi %75,5 oranında açıklamaktadır. Belirleme katsayısının değeri ne kadar yüksek olursa, seçilen model belirli bir görev için o kadar uygulanabilir olur. 0.8'in üzerinde bir R-kare değeri ile gerçek durumu doğru bir şekilde tanımladığına inanılmaktadır. R-kare tcr ise, lineer denklemin serbest teriminin önemsizliği hipotezi reddedilir.
Serbest üye için incelenmekte olan problemde, Excel araçları kullanılarak, t = 169.20903 ve p = 2.89E-12 olduğu elde edildi, yani serbest üyenin önemsizliği hakkında doğru hipotezin doğru olacağına dair sıfır olasılığımız var. Reddedilmiş. Bilinmeyen katsayı için t=5,79405 ve p=0,001158. Başka bir deyişle, bilinmeyen için katsayının anlamsızlığına ilişkin doğru hipotezin reddedilme olasılığı %0,12'dir.
Böylece ortaya çıkan lineer regresyon denkleminin yeterli olduğu söylenebilir.
Bir hisse bloğu satın almanın uygunluğu sorunu
Excel'de çoklu regresyon, aynı Veri Analizi aracı kullanılarak gerçekleştirilir. Belirli bir uygulamalı problem düşünün.
NNN yönetimi, MMM SA'nın %20 hissesinin satın alınmasının tavsiye edilebilirliği konusunda bir karar vermelidir. Paketin (JV) maliyeti 70 milyon ABD dolarıdır. NNN uzmanları benzer işlemler hakkında veri topladı. Hisse bloğunun değerinin milyonlarca ABD doları cinsinden ifade edilen bu tür parametrelere göre aşağıdaki gibi değerlendirilmesine karar verildi:
- ödenecek hesaplar (VK);
- yıllık ciro (VO);
- alacak hesapları (VD);
- sabit varlıkların maliyeti (SOF).
Ek olarak, binlerce ABD doları cinsinden işletmenin bordro borçları (V3 P) parametresi kullanılır.
Excel elektronik tablosunu kullanarak çözüm
Her şeyden önce, bir başlangıç verileri tablosu oluşturmanız gerekir. Şuna benziyor:
- "Veri Analizi" penceresini arayın;
- "Gerileme" bölümünü seçin;
- "Giriş aralığı Y" kutusuna, G sütunundan bağımlı değişkenlerin değer aralığını girin;
- "Giriş aralığı X" penceresinin sağındaki kırmızı oklu simgeye tıklayın ve sayfadaki B, C, D, F sütunlarından tüm değerlerin aralığını seçin.
"Yeni Çalışma Sayfası"nı seçin ve "Tamam"a tıklayın.
Verilen problem için regresyon analizini alın.
Sonuçların ve sonuçların incelenmesi
Yukarıda Excel elektronik tablo sayfasında sunulan yuvarlatılmış verilerden, regresyon denklemini "toplarız":
SP \u003d 0,103 * SOF + 0,541 * VO - 0,031 * VK + 0,405 * VD + 0,691 * VZP - 265,844.
Daha tanıdık bir matematiksel formda, şu şekilde yazılabilir:
y = 0,103*x1 + 0,541*x2 - 0,031*x3 +0,405*x4 +0,691*x5 - 265,844
JSC "MMM" için veriler tabloda sunulmaktadır:
Bunları regresyon denkleminde yerine koyarsak, 64.72 milyon ABD doları elde ederler. Bu, JSC MMM'nin hisselerinin satın alınmaması gerektiği anlamına gelir, çünkü 70 milyon ABD doları değerindeki değerleri oldukça fazladır.
Gördüğünüz gibi, Excel elektronik tablosunun ve regresyon denkleminin kullanılması, çok özel bir işlemin fizibilitesine ilişkin bilinçli bir karar vermeyi mümkün kıldı.
Artık gerilemenin ne olduğunu biliyorsunuz. Yukarıda tartışılan Excel'deki örnekler, ekonometri alanındaki pratik sorunları çözmenize yardımcı olacaktır.
Doğrusal regresyon yöntemi, bir dizi sıralı çifte (x, y) en iyi uyan düz bir çizgiyi tanımlamamızı sağlar. Doğrusal denklem olarak bilinen düz bir çizginin denklemi aşağıda verilmiştir:
ŷ, belirli bir x değeri için y'nin beklenen değeridir,
x bağımsız bir değişkendir,
a - düz bir çizgi için y eksenindeki segment,
b düz çizginin eğimidir.
Aşağıdaki şekilde, bu kavram grafiksel olarak temsil edilmektedir:
Yukarıdaki şekil, ŷ =2+0,5x denklemiyle açıklanan bir çizgiyi göstermektedir. y eksenindeki doğru parçası, doğrunun y eksenini kestiği noktadır; bizim durumumuzda, a = 2. Doğrunun eğimi, b, çizgi yükselişinin çizgi uzunluğuna oranı, 0,5 değerine sahiptir. Pozitif bir eğim, çizginin soldan sağa doğru yükseldiği anlamına gelir. b = 0 ise çizgi yataydır, yani bağımlı ve bağımsız değişkenler arasında ilişki yoktur. Başka bir deyişle, x'in değerini değiştirmek y'nin değerini etkilemez.
ŷ ve y genellikle karıştırılır. Grafik, verilen denkleme göre 6 sıralı nokta çiftini ve bir çizgiyi göstermektedir.
Bu şekil x = 2 ve y = 4 sıralı çiftine karşılık gelen noktayı göstermektedir. X= 2 ŷ'dir. Bunu aşağıdaki denklemle doğrulayabiliriz:
ŷ = 2 + 0,5х =2 +0,5(2) =3.
y değeri gerçek noktadır ve ŷ değeri, belirli bir x değeri için doğrusal bir denklem kullanılarak beklenen y değeridir.
Bir sonraki adım, sıralı çiftler kümesine maksimum olarak karşılık gelen doğrusal denklemi belirlemektir, denklemin biçimini ile belirlediğimiz önceki makalede bundan bahsetmiştik.
Doğrusal Regresyonu Tanımlamak için Excel'i Kullanma
Excel'de yerleşik olan regresyon analizi aracını kullanmak için eklentiyi etkinleştirmeniz gerekir. Analiz paketi. Sekmesine tıklayarak bulabilirsiniz Dosya -> Seçenekler(2007+), görüntülenen iletişim kutusunda Seçeneklermükemmel sekmeye git eklentiler sahada Kontrol seçmek eklentilermükemmel ve tıklayın Gitmek. Görünen pencerede, yanındaki kutuyu işaretleyin. analiz paketi, tıklamak TAMAM.

sekmesinde Veri grup içinde Analiz yeni bir düğme görünecek Veri analizi.

Eklentinin nasıl çalıştığını göstermek için, bir erkek ve bir kızın banyoda aynı masayı paylaştığı verileri kullanalım. Banyo örneğimizin verilerini boş bir sayfanın A ve B sütunlarına girin.
sekmeye git Veri, grup içinde Analiz tıklamak Veri analizi. Görünen pencerede Veri analizi seçme gerilemeşekilde gösterildiği gibi ve Tamam'a tıklayın.

Pencerede gerekli regresyon parametrelerini ayarlayın gerileme, resimde gösterildiği gibi:

Tıklamak TAMAM. Aşağıdaki şekil elde edilen sonuçları göstermektedir:

Bu sonuçlar, içinde bağımsız hesaplamalarla elde ettiğimiz sonuçlarla tutarlıdır.
İLİŞKİ-REGRESYON ANALİZİHANIM EXCEL
1. MS Excel'de bir kaynak veri dosyası oluşturun (örneğin, tablo 2)
2. Korelasyon alanının oluşturulması
Komut satırında bir korelasyon alanı oluşturmak için menüyü seçin Ekle / Diyagram. Görüntülenen iletişim kutusunda grafik türünü seçin: noktalı; görüş: dağılım grafiği, değer çiftlerini karşılaştırmanıza izin verir (Şek. 22).
Şekil 22 - Grafik türünün seçilmesi
Şekil 23 - Bir aralık ve seri seçerken pencerenin görünümü
Şekil 25 - Pencerenin görünümü, 4. adım
2. Bağlam menüsünde komutu seçin Trend çizgisi ekleyin.
3. Görünen iletişim kutusunda, Şekil 26'da gösterildiği gibi grafik tipini (bizim örneğimizde doğrusal) ve denklem parametrelerini seçin.
Tamam'a basıyoruz. Sonuç, Şekil 27'de gösterilmektedir.
Şekil 27 - Emek verimliliğinin sermaye-emek oranına bağımlılığının korelasyon alanı
Benzer şekilde, işgücü verimliliğinin ekipman kaydırma oranına bağımlılığı için bir korelasyon alanı oluşturuyoruz. (Şekil 28).
 |
Şekil 28 - İşgücü verimliliğine bağımlılık korelasyon alanı
ekipman kaydırma faktöründen
3. Korelasyon matrisinin oluşturulması.
Menüde bir korelasyon matrisi oluşturmak için Hizmet seçmek Veri analizi.
Bir veri analiz aracı kullanma gerileme, regresyon istatistikleri, varyans analizi ve güven aralıklarının sonuçlarına ek olarak, regresyon çizgisinin artıklarını ve uydurma grafiklerini, artıkları ve normal olasılığı elde edebilirsiniz. Bunu yapmak için analiz paketine erişimi kontrol etmeniz gerekir. Ana menüden seçin Hizmet / Eklentiler. onay kutusu Analiz paketi(Şekil 29)
Şekil 30 - İletişim kutusu Veri analizi
Tamam'ı tıklattıktan sonra, beliren iletişim kutusunda Şekil 31'de gösterildiği gibi giriş aralığını (bizim örneğimizde A2: D26), gruplandırmayı (bizim durumumuzda sütunlara göre) ve çıkış parametrelerini belirtin.
 |
Şekil 31 - İletişim kutusu korelasyon
Hesaplama sonucu Tablo 4'te sunulmuştur.
Tablo 4 - Korelasyon matrisi
Sütun 1 | Sütun 2 | Sütun 3 |
|
Sütun 1 | |||
Sütun 2 | |||
Sütun 3 |
TEK DEĞİŞKENLİ REGRESYON ANALİZİ
REGRESYON ARACI KULLANIMI
Menüde emek verimliliğinin sermaye-emek oranına bağımlılığının regresyon analizini yapmak Hizmet seçmek Veri analizi ve analiz aracını belirtin gerileme(Şekil 32).
Şekil 33 - İletişim kutusu gerileme