تجزیه و تحلیل رگرسیون در مثال اکسل. روشهای ریاضی در روانشناسی
به دلیل مفید بودن در زمینه های مختلف فعالیت، از جمله رشته ای مانند اقتصاد سنجی، که در آن از این ابزار نرم افزاری در کار استفاده می شود، شناخته شده است. اصولاً تمام اعمال تمرینات عملی و آزمایشگاهی در اکسل انجام می شود که با ارائه توضیحات دقیق در مورد اقدامات خاص، کار را بسیار تسهیل می کند. بنابراین، یکی از ابزارهای تحلیل «رگرسیون» برای انتخاب یک نمودار برای مجموعهای از مشاهدات با استفاده از روش حداقل مربعات استفاده میشود. بیایید در نظر بگیریم که این ابزار برنامه چیست و چه فایده ای برای کاربران دارد. در زیر نیز یک دستورالعمل مختصر اما قابل درک برای ساخت یک مدل رگرسیون آمده است.
وظایف اصلی و انواع رگرسیون
رگرسیون رابطه ای بین متغیرهای داده شده است که با توجه به آن می توان پیش بینی رفتار آینده این متغیرها را تعیین کرد. متغیرها پدیده های دوره ای مختلف از جمله رفتار انسان هستند. این تجزیه و تحلیل اکسل برای تجزیه و تحلیل تأثیر مقادیر یک یا چند متغیر بر روی یک متغیر وابسته خاص استفاده می شود. به عنوان مثال، فروش در یک فروشگاه تحت تأثیر عوامل متعددی از جمله مجموعه، قیمت ها و مکان فروشگاه است. با استفاده از رگرسیون در اکسل، می توانید میزان تأثیر هر یک از این عوامل را بر اساس نتایج فروش موجود تعیین کنید و سپس داده های به دست آمده را برای پیش بینی فروش برای یک ماه دیگر یا برای فروشگاه دیگری که در نزدیکی آن قرار دارد، اعمال کنید.
به طور معمول، رگرسیون به عنوان یک معادله ساده ارائه می شود که وابستگی ها و قدرت ارتباط بین دو گروه از متغیرها را نشان می دهد، که در آن یک گروه وابسته یا درون زا و گروه دیگر مستقل یا برون زا است. در صورت وجود گروهی از شاخص های مرتبط با یکدیگر، متغیر وابسته Y بر اساس منطق استدلال تعیین می شود و بقیه به عنوان متغیر X مستقل عمل می کنند.
وظایف اصلی ساخت مدل رگرسیون به شرح زیر است:
- انتخاب متغیرهای مستقل مهم (Х1، Х2، ...، Xk).
- انتخاب نوع عملکرد
- ساخت تخمین برای ضرایب.
- ساخت فواصل اطمینان و توابع رگرسیون.
- بررسی اهمیت برآوردهای محاسبه شده و معادله رگرسیون ساخته شده.
انواع مختلفی از تحلیل رگرسیون وجود دارد:
- زوج (1 متغیر وابسته و 1 متغیر مستقل)؛
- چندگانه (چند متغیر مستقل).
دو نوع معادله رگرسیون وجود دارد:
- خطی، نشان دهنده یک رابطه خطی دقیق بین متغیرها است.
- غیر خطی - معادلاتی که می توانند شامل توان ها، کسرها و توابع مثلثاتی باشند.
دستورالعمل ساخت مدل
برای انجام یک ساختار داده شده در اکسل، باید دستورالعمل ها را دنبال کنید:

برای محاسبه بیشتر، باید از تابع "Linear()" استفاده شود که مقادیر Y، X مقادیر، Const و آمار را مشخص می کند. پس از آن، مجموعه نقاط روی خط رگرسیون را با استفاده از تابع "Trend" تعیین کنید - مقادیر Y، X-values، مقادیر جدید، Const. با استفاده از پارامترهای داده شده، مقدار مجهول ضرایب را بر اساس شرایط داده شده مسئله محاسبه کنید.
که در برتری داشتنراه سریعتر و راحتتری برای ترسیم رگرسیون خطی وجود دارد (و حتی انواع اصلی رگرسیونهای غیرخطی، در زیر ببینید). این را می توان به صورت زیر انجام داد:
1) ستون های دارای داده را انتخاب کنید ایکسو Y(آنها باید به این ترتیب باشند!)
2) تماس بگیرید جادوگر نمودارو در یک گروه انتخاب کنید تایپ کنید – خط چینو بلافاصله فشار دهید آماده;
3) بدون لغو انتخاب نمودار، آیتم منوی اصلی ظاهر شده را انتخاب کنید نمودار، که در آن باید مورد را انتخاب کنید خط روند را اضافه کنید;
4) در محاوره ای که ظاهر می شود خط روندبرگه تایپ کنیدانتخاب کنید خطی;
5) برگه گزینه هاسوئیچ را می توان فعال کرد معادله را روی نمودار نشان دهید، که به شما امکان می دهد معادله رگرسیون خطی (4.4) را مشاهده کنید که در آن ضرایب (4.5) محاسبه می شود.
6) در همان تب می توانید سوئیچ را فعال کنید مقدار اطمینان تقریبی را روی نمودار قرار دهید (R^2). این مقدار مجذور ضریب همبستگی (4.3) است و نشان می دهد که معادله محاسبه شده چقدر وابستگی تجربی را توصیف می کند. اگر آر 2 نزدیک به وحدت است، سپس معادله رگرسیون نظری وابستگی تجربی را به خوبی توصیف می کند (نظریه به خوبی با آزمایش موافق است) و اگر آر 2 نزدیک به صفر است، پس این معادله برای توصیف وابستگی تجربی مناسب نیست (نظریه با آزمایش موافق نیست).
در نتیجه انجام اقدامات توصیف شده، نموداری با نمودار رگرسیون و معادله آن دریافت خواهید کرد.
§4.3. انواع اصلی رگرسیون غیر خطی
رگرسیون سهموی و چند جمله ای
سهمویوابستگی به ارزش Yاز ارزش ایکسوابستگی بیان شده توسط یک تابع درجه دوم (پارابولای مرتبه دوم) نامیده می شود:
این معادله نامیده می شود رگرسیون سهموی Yبر ایکس. گزینه ها آ, ب, باتماس گرفت ضرایب رگرسیون سهموی. محاسبه ضرایب رگرسیون سهموی همیشه دست و پا گیر است، بنابراین توصیه می شود از رایانه برای محاسبات استفاده کنید.
معادله (4.8) رگرسیون سهموی یک مورد خاص از یک رگرسیون عمومی تر به نام چند جمله ای است. چند جمله ایوابستگی به ارزش Yاز ارزش ایکسوابستگی بیان شده توسط چند جمله ای نامیده می شود n- مرتبه:
اعداد کجا هستند یک من (من=0,1,…, n) نامیده می شوند ضرایب رگرسیون چند جمله ای.
رگرسیون قدرت.
قدرتوابستگی به ارزش Yاز ارزش ایکسوابستگی شکل نامیده می شود:
این معادله نامیده می شود معادله رگرسیون توان Yبر ایکس. گزینه ها آو بتماس گرفت ضرایب رگرسیون توان.
ln=ln آ+بلوگاریتم ایکس. (4.11)
این معادله یک خط مستقیم را در صفحه با محورهای مختصات لگاریتمی ln توصیف می کند. ایکسو ln. بنابراین، معیار کاربردی بودن رگرسیون توانی این شرط است که نقاط لگاریتم داده های تجربی ln x iو ln مننزدیکترین به خط مستقیم بودند (4.11).
رگرسیون نمایی
نمونه(یا نمایی) وابستگی به کمیت Yاز ارزش ایکسوابستگی شکل نامیده می شود:
(یا ). (4.12)
این معادله نامیده می شود معادله نمایی(یا نمایی) رگرسیون Yبر ایکس. گزینه ها آ(یا ک) و بتماس گرفت نمایی(یا نمایی) پسرفت.
اگر لگاریتم دو طرف معادله رگرسیون توان را بگیریم، معادله را بدست می آوریم.
ln = ایکسلوگاریتم آ+ln ب(یا ln = k x+ln ب). (4.13)
این معادله وابستگی خطی لگاریتم یک کمیت ln به کمیت دیگر را توصیف می کند. ایکس. بنابراین، ملاک کاربردی بودن رگرسیون توان این است که دادههای تجربی به اندازه یکسان باشند. x iو لگاریتمی با مقدار دیگری ln مننزدیکترین به خط مستقیم بودند (4.13).
رگرسیون لگاریتمی
لگاریتمیوابستگی به ارزش Yاز ارزش ایکسوابستگی شکل نامیده می شود:
=آ+بلوگاریتم ایکس. (4.14)
این معادله نامیده می شود رگرسیون لگاریتمی Yبر ایکس. گزینه ها آو بتماس گرفت ضرایب رگرسیون لگاریتمی.
رگرسیون هایپربولیک
هایپربولیکوابستگی به ارزش Yاز ارزش ایکسوابستگی شکل نامیده می شود:
این معادله نامیده می شود معادله رگرسیون هذلولی Yبر ایکس. گزینه ها آو بتماس گرفت ضرایب رگرسیون هایپربولیکو با روش حداقل مربعات تعیین می شوند. استفاده از این روش به فرمول های زیر منجر می شود:
در فرمول های (4.16-4.17)، جمع بر روی شاخص انجام می شود مناز یک به تعداد مشاهدات n.
متاسفانه در برتری داشتنهیچ تابعی وجود ندارد که ضرایب رگرسیون هذلولی را محاسبه کند. در مواردی که به طور قطع مشخص نیست که مقادیر اندازه گیری شده با نسبت معکوس مرتبط هستند، توصیه می شود به جای معادله رگرسیون هذلولی به دنبال معادله رگرسیون توان بگردید، بنابراین در برتری داشتنروشی برای یافتن آن وجود دارد. اگر یک وابستگی هذلولی بین مقادیر اندازه گیری شده در نظر گرفته شود، ضرایب رگرسیون آن باید با استفاده از جداول محاسبه کمکی و عملیات جمع با استفاده از فرمول های (4.16-4.17) محاسبه شود.
روش رگرسیون خطی به ما اجازه می دهد تا یک خط مستقیم را توصیف کنیم که به بهترین وجه با یک سری از جفت های مرتب شده (x، y) مطابقت دارد. معادله یک خط مستقیم که به معادله خطی معروف است در زیر آورده شده است:
ŷ مقدار مورد انتظار y برای مقدار معین x است،
x یک متغیر مستقل است،
a - بخش در محور y برای یک خط مستقیم،
b شیب خط مستقیم است.
در شکل زیر این مفهوم به صورت گرافیکی نشان داده شده است:
شکل بالا خطی را نشان می دهد که با معادله ŷ =2+0.5x توصیف شده است. پاره خط روی محور y نقطه ای است که خط با محور y قطع می کند. در مورد ما، a = 2. شیب خط، b، نسبت افزایش خط به طول خط، مقدار 0.5 دارد. شیب مثبت به این معنی است که خط از چپ به راست بالا می رود. اگر b = 0، خط افقی است، به این معنی که هیچ رابطه ای بین متغیرهای وابسته و مستقل وجود ندارد. به عبارت دیگر تغییر مقدار x تاثیری بر مقدار y ندارد.
ŷ و y اغلب اشتباه گرفته می شوند. نمودار مطابق معادله داده شده 6 جفت نقطه مرتب و یک خط را نشان می دهد

این شکل نقطه مربوط به جفت مرتب شده x = 2 و y = 4 را نشان می دهد. توجه داشته باشید که مقدار مورد انتظار y با توجه به خط در ایکس= 2 برابر ŷ است. ما می توانیم این را با معادله زیر تأیید کنیم:
ŷ = 2 + 0.5x = 2 + 0.5 (2) = 3.
مقدار y نقطه واقعی است و مقدار ŷ مقدار y مورد انتظار با استفاده از یک معادله خطی برای مقدار x معین است.
مرحله بعدی تعیین معادله خطی است که حداکثر با مجموعه جفت های مرتب شده مطابقت دارد، در مقاله قبلی در این مورد صحبت کردیم، جایی که شکل معادله را با .
استفاده از اکسل برای تعریف رگرسیون خطی
برای استفاده از ابزار تحلیل رگرسیون ساخته شده در اکسل، باید افزونه را فعال کنید بسته تحلیلی. با کلیک بر روی برگه می توانید آن را پیدا کنید فایل –> گزینه ها(2007+)، در گفتگوی ظاهر شده گزینه هابرتری داشتنبه برگه بروید افزونه هادر زمینه کنترلانتخاب کنید افزونه هابرتری داشتنو کلیک کنید برودر پنجره ای که ظاهر می شود، کادر کناری را علامت بزنید بسته تحلیلی،کلیک خوب.

در برگه داده هادر گروه تحلیل و بررسییک دکمه جدید ظاهر می شود تحلیل داده ها.

برای نشان دادن نحوه عملکرد این افزونه، از دادهها استفاده میکنیم، جایی که یک پسر و یک دختر در یک میز در حمام مشترک هستند. داده های مثال حمام ما را در ستون های A و B یک صفحه خالی وارد کنید.
به برگه بروید داده ها،در گروه تحلیل و بررسیکلیک تحلیل داده ها.در پنجره ای که ظاهر می شود تحلیل داده هاانتخاب کنید پسرفتهمانطور که در شکل نشان داده شده است و روی OK کلیک کنید.

پارامترهای رگرسیون مورد نیاز را در پنجره تنظیم کنید پسرفت، همانطور که در تصویر نشان داده شده است:

کلیک خوب.شکل زیر نتایج به دست آمده را نشان می دهد:
این نتایج با نتایج محاسبات مستقل در .
ساخت یک رگرسیون خطی، تخمین پارامترهای آن و اهمیت آنها در هنگام استفاده از بسته تحلیل اکسل (رگرسیون) بسیار سریعتر انجام می شود. اجازه دهید تفسیر نتایج به دست آمده را در حالت کلی در نظر بگیریم ( کمتغیرهای توضیحی) مطابق مثال 3.6.
جدول آمار رگرسیونمقادیر داده شده است:
چندگانه آر – ضریب همبستگی چندگانه؛
آر- مربع– ضریب تعیین آر 2 ;
عادی شده است آر - مربع- تنظیم شده آر 2 تنظیم شده برای تعداد درجات آزادی؛
خطای استانداردخطای استاندارد رگرسیون است اس;
مشاهدات -تعداد مشاهدات n.
جدول تحلیل واریانسداده شده:
1. ستون df - تعداد درجات آزادی برابر است
برای رشته پسرفت df = ک;
برای رشته باقی ماندهdf = n – ک – 1;
برای رشته جمعdf = n– 1.
2. ستون SS-مجموع مجذور انحرافات، برابر است
برای رشته پسرفت ;
برای رشته باقی مانده ;
برای رشته جمع .
3. ستون اماسواریانس های تعیین شده توسط فرمول اماس = اس اس/df:
برای رشته پسرفت- واریانس عاملی؛
برای رشته باقی ماندهواریانس باقیمانده است.
4. ستون اف - ارزش محاسبه شده اف- معیارهای محاسبه شده با فرمول
اف = اماس(پسرفت)/ اماس(باقی مانده).
5. ستون اهمیت اف مقدار سطح معنی داری مربوط به محاسبه شده است اف-آمار .
اهمیت اف= FRIST( F-آمار، df(پسرفت)، df(باقی مانده)).
اگر اهمیت دارد اف < стандартного уровня значимости, то آر 2 از نظر آماری معنی دار است.
| ضرایب | خطای استاندارد | آمار t | مقدار p | 95% پایین | 95% برتر | |
| Y | 65,92 | 11,74 | 5,61 | 0,00080 | 38,16 | 93,68 |
| ایکس | 0,107 | 0,014 | 7,32 | 0,00016 | 0,0728 | 0,142 |
این جدول نشان می دهد:
1. شانس- مقادیر ضرایب آ, ب.
2. خطای استانداردخطاهای استاندارد ضرایب رگرسیون هستند S a, Sb.
3. t-آمار- مقادیر محاسبه شده تی - معیارهای محاسبه شده با فرمول:
t-statistic = ضرایب / خطای استاندارد.
4.آر-ارزش (اهمیت تی) مقدار سطح معنی داری مربوط به محاسبه شده است t-آمار.
آر-value= استودراسپ(تی-آمار، df(باقی مانده)).
اگر آر-معنی< стандартного уровня значимости, то соответствующий коэффициент статистически значим.
5. 95% پایین و 95% بالامرزهای پایین و بالای فاصله اطمینان 95 درصد برای ضرایب معادله رگرسیون خطی نظری هستند.
| انصراف باقی مانده | ||
| مشاهده | y را پیش بینی کرد | باقی می ماند e |
| 72,70 | -29,70 | |
| 82,91 | -20,91 | |
| 94,53 | -4,53 | |
| 105,72 | 5,27 | |
| 117,56 | 12,44 | |
| 129,70 | 19,29 | |
| 144,22 | 20,77 | |
| 166,49 | 24,50 | |
| 268,13 | -27,13 |
جدول انصراف باقی ماندهنشان داد:
در یک ستون مشاهده- شماره مشاهده؛
در یک ستون پیش بینی کرد y مقادیر محاسبه شده متغیر وابسته هستند.
در یک ستون باقی ه تفاوت بین مقادیر مشاهده شده و محاسبه شده متغیر وابسته است.
مثال 3.6.داده های موجود (واحدهای عربی) در مورد هزینه های غذا yو درآمد سرانه ایکسبرای نه گروه از خانواده ها:
| ایکس | |||||||||
| y |
با استفاده از نتایج بسته تحلیل اکسل (رگرسیون)، وابستگی هزینه های مواد غذایی به ارزش درآمد سرانه را تجزیه و تحلیل می کنیم.
نتایج تحلیل رگرسیون معمولاً به صورت زیر نوشته می شود:
![]()
که در داخل پرانتز خطاهای استاندارد ضرایب رگرسیون وجود دارد.
ضرایب رگرسیون آ = 65,92 و ب= 0.107. جهت ارتباط بین yو ایکسعلامت ضریب رگرسیون را تعیین می کند ب= 0.107، یعنی رابطه مستقیم و مثبت است. ضریب ب 0.107 = نشان می دهد که با افزایش درآمد سرانه 1 ارب. واحدها هزینه های غذا 0.107 تبدیل افزایش می یابد. واحدها
اجازه دهید اهمیت ضرایب مدل به دست آمده را تخمین بزنیم. اهمیت ضرایب ( الف، ب) در مقابل بررسی می شود تی- تست:
مقدار p ( آ) = 0,00080 < 0,01 < 0,05
مقدار p ( ب) = 0,00016 < 0,01 < 0,05,
از این رو ضرایب ( الف، ب) در سطح 1% و حتی بیشتر از آن در سطح 5% معنی دار هستند. بنابراین، ضرایب رگرسیون معنی دار بوده و مدل برای داده های اصلی مناسب است.
نتایج تخمین رگرسیون نه تنها با مقادیر بدست آمده از ضرایب رگرسیون، بلکه با مقداری از مجموعه آنها (فاصله اطمینان) نیز سازگار است. با احتمال 95 درصد، فواصل اطمینان برای ضرایب (38.16 - 93.68) برای آو (0.0728 - 0.142) برای ب
کیفیت مدل با ضریب تعیین ارزیابی می شود آر 2 .
ارزش آر 2 = 0.884 به این معنی است که ضریب درآمد سرانه می تواند 88.4 درصد از تغییرات (پراکندگی) در مخارج مواد غذایی را توضیح دهد.
اهمیت آر 2 توسط F-آزمون: اهمیت اف = 0,00016 < 0,01 < 0,05, следовательно, آر 2 در سطح 1% و حتی بیشتر از آن در سطح 5% معنی دار است.
در مورد رگرسیون خطی زوجی، ضریب همبستگی را می توان به صورت تعریف کرد ![]() . مقدار به دست آمده از ضریب همبستگی نشان می دهد که رابطه بین هزینه های غذایی و درآمد سرانه بسیار نزدیک است.
. مقدار به دست آمده از ضریب همبستگی نشان می دهد که رابطه بین هزینه های غذایی و درآمد سرانه بسیار نزدیک است.
برای مناطق منطقه، داده ها برای 200X داده شده است.
| شماره منطقه | میانگین سرانه حداقل معیشت در روز برای یک فرد توانمند، روبل، x | میانگین حقوق روزانه، روبل، در |
|---|---|---|
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
ورزش:
1. یک میدان همبستگی بسازید و یک فرضیه در مورد شکل اتصال ایجاد کنید.
2. پارامترهای معادله رگرسیون خطی را محاسبه کنید
4. با استفاده از میانگین (عمومی) ضریب کشش، ارزیابی مقایسه ای از قدرت رابطه بین عامل و نتیجه ارائه دهید.
7. مقدار پیش بینی شده نتیجه را در صورتی محاسبه کنید که مقدار پیش بینی شده ضریب 10 درصد از سطح متوسط آن افزایش یابد. فاصله اطمینان پیش بینی را برای سطح معنی داری تعیین کنید.
راه حل:
بیایید این مشکل را با استفاده از اکسل حل کنیم.
1. با مقایسه داده های موجود x و y، به عنوان مثال، رتبه بندی آنها به ترتیب صعودی ضریب x، می توان رابطه مستقیمی را بین علائم مشاهده کرد که افزایش حداقل معیشت سرانه باعث افزایش متوسط دستمزد روزانه می شود. بر این اساس می توان فرض کرد که رابطه بین علائم مستقیم است و می توان آن را با معادله یک خط مستقیم توصیف کرد. همین نتیجه بر اساس تحلیل گرافیکی تایید شده است.
برای ایجاد یک فیلد همبستگی، می توانید از Excel PPP استفاده کنید. داده های اولیه را به ترتیب وارد کنید: ابتدا x و سپس y.
ناحیه سلول های حاوی داده را انتخاب کنید.
سپس انتخاب کنید: درج / پراکنده / پراکنده با نشانگرهمانطور که در شکل 1 نشان داده شده است.

شکل 1 ساخت میدان همبستگی
تجزیه و تحلیل میدان همبستگی وجود یک وابستگی نزدیک به یک خط مستقیم را نشان می دهد، زیرا نقاط تقریباً در یک خط مستقیم قرار دارند.
2. برای محاسبه پارامترهای معادله رگرسیون خطی
از تابع آماری داخلی استفاده کنید LINEST.
برای این:
1) یک فایل موجود حاوی داده های مورد تجزیه و تحلیل را باز کنید.
2) ناحیه ای از سلول های خالی 5×2 (5 ردیف، 2 ستون) را برای نمایش نتایج آمار رگرسیون انتخاب کنید.
3) فعال کنید Function Wizard: در منوی اصلی، را انتخاب کنید فرمول ها / درج تابع.
4) در پنجره دسته بندیشما در حال گرفتن هستید آماری، در پنجره تابع - LINEST. روی دکمه کلیک کنید خوبهمانطور که در شکل 2 نشان داده شده است؛

شکل 2 جعبه گفتگوی Function Wizard
5) آرگومان های تابع را پر کنید:
ارزش های شناخته شده
مقادیر x شناخته شده
ثابت- یک مقدار منطقی که وجود یا عدم وجود یک عبارت آزاد را در معادله نشان می دهد. اگر Constant = 1 باشد، ترم آزاد به روش معمول محاسبه می شود، اگر ثابت = 0، ترم آزاد 0 است.
آمار- یک مقدار بولی که نشان می دهد آیا اطلاعات اضافی در تجزیه و تحلیل رگرسیون نمایش داده می شود یا خیر. اگر Statistics = 1، اطلاعات اضافی نمایش داده می شود، اگر Statistics = 0، تنها تخمین پارامترهای معادله نمایش داده می شود.
روی دکمه کلیک کنید خوب;

شکل 3 جعبه گفتگوی LINEST Arguments
6) اولین عنصر جدول نهایی در سلول سمت چپ بالای ناحیه انتخاب شده ظاهر می شود. برای بزرگ کردن کل جدول، دکمه را فشار دهید
آمار رگرسیون اضافی به ترتیب نشان داده شده در طرح زیر خروجی خواهد شد:
| مقدار ضریب b | مقدار ضریب a |
| b خطای استاندارد | خطای استاندارد الف |
| خطای استاندارد y | |
| آمار F | |
| مجموع رگرسیون مربع ها
|

شکل 4 نتیجه محاسبه تابع LINEST
معادله رگرسیون را بدست آوردیم:
نتیجه می گیریم: با افزایش سرانه حداقل 1 روبل. متوسط دستمزد روزانه به طور متوسط 0.92 روبل افزایش می یابد.
این به این معنی است که 52 درصد از تغییرات دستمزد (y) با تغییر عامل x - میانگین حداقل معیشت سرانه و 48 درصد - با عملکرد سایر عواملی که در مدل گنجانده نشده است توضیح داده می شود.
با توجه به ضریب تعیین محاسبه شده، می توان ضریب همبستگی را محاسبه کرد: ![]() .
.
رابطه نزدیک رتبه بندی می شود.
4. با استفاده از میانگین (عمومی) ضریب کشش، قدرت تأثیر عامل بر نتیجه را تعیین می کنیم.
برای معادله خط مستقیم، ضریب کشش متوسط (عمومی) با فرمول تعیین می شود:

با انتخاب مساحت سلول های دارای مقادیر x، مقادیر متوسط را پیدا کرده و انتخاب می کنیم فرمول ها / جمع خودکار / میانگینو همین کار را با مقادیر y انجام دهید.

شکل 5 محاسبه مقادیر میانگین یک تابع و آرگومان
بنابراین، اگر میانگین سرانه حداقل معیشتی 1 درصد از مقدار متوسط خود تغییر کند، متوسط دستمزد روزانه به طور متوسط 0.51 درصد تغییر خواهد کرد.
استفاده از ابزار تجزیه و تحلیل داده ها پسرفتدر دسترس:
- نتایج آمار رگرسیون،
- نتایج تجزیه و تحلیل پراکندگی،
- نتایج فواصل اطمینان،
- نمودارهای برازش باقیمانده و خط رگرسیون،
- باقی مانده ها و احتمال عادی.
روند کار به صورت زیر است:
1) بررسی دسترسی به بسته تحلیلی. در منوی اصلی به ترتیب انتخاب کنید: فایل/تنظیمات/افزونه ها.
2) رها کردن کنترلمورد را انتخاب کنید افزونه های اکسلو دکمه را فشار دهید برو
3) در پنجره افزونه هاکادر را علامت بزنید بسته تحلیلیو سپس روی دکمه کلیک کنید خوب.
اگر بسته تحلیلیاز لیست فیلد موجود نیست افزونه های موجود، دکمه را فشار دهید مروربرای جستجو
اگر پیامی مبنی بر نصب نشدن بسته تحلیلی روی رایانه دریافت کردید، کلیک کنید آرهبرای نصب آن
4) در منوی اصلی، به ترتیب انتخاب کنید: داده ها / تجزیه و تحلیل داده ها / ابزارهای تجزیه و تحلیل / رگرسیونو سپس روی دکمه کلیک کنید خوب.
5) کادر محاوره ای گزینه های ورودی و خروجی داده را پر کنید:
فاصله ورودی Y- محدوده حاوی داده های ویژگی موثر؛
فاصله ورودی X- محدوده حاوی داده های ویژگی عامل؛
برچسب ها- پرچمی که نشان می دهد خط اول شامل نام ستون ها است یا خیر.
ثابت - صفر- پرچمی که وجود یا عدم وجود یک عبارت آزاد در معادله را نشان می دهد.
فاصله خروجی- کافی است سلول سمت چپ بالای محدوده آینده را نشان دهید.
6) کاربرگ جدید - می توانید یک نام دلخواه برای برگه جدید تعیین کنید.
سپس دکمه را فشار دهید خوب.

شکل 6 کادر محاوره ای برای وارد کردن پارامترهای ابزار Regression
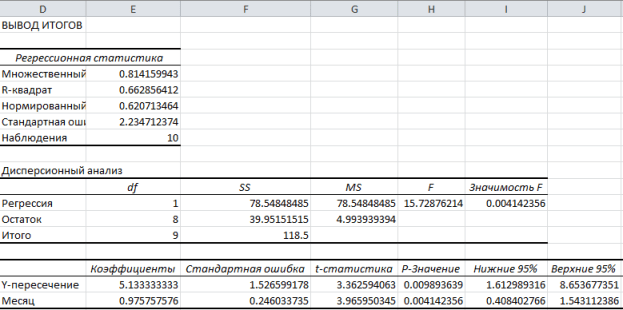
نتایج تحلیل رگرسیون برای داده های مسئله در شکل 7 نشان داده شده است.

شکل 7 نتیجه اعمال ابزار رگرسیون
5. اجازه دهید کیفیت معادلات را با استفاده از میانگین خطای تقریب تخمین بزنیم. بیایید از نتایج تحلیل رگرسیون ارائه شده در شکل 8 استفاده کنیم.

شکل 8 نتیجه به کارگیری ابزار رگرسیون "استنتاج باقیمانده"
بیایید یک جدول جدید مطابق شکل 9 جمع آوری کنیم. در ستون C، خطای تقریب نسبی را با استفاده از فرمول محاسبه می کنیم:
![]()

شکل 9 محاسبه میانگین خطای تقریب
میانگین خطای تقریب با فرمول محاسبه می شود:

کیفیت مدل ساخته شده خوب ارزیابی می شود، زیرا از 8 تا 10 درصد تجاوز نمی کند.
6. از جدول با آمار رگرسیون (شکل 4)، مقدار واقعی آزمون F فیشر را می نویسیم: ![]()
از آنجا که ![]() در سطح معنیداری 5 درصد، میتوان نتیجه گرفت که معادله رگرسیون معنادار است (رابطه ثابت شده است).
در سطح معنیداری 5 درصد، میتوان نتیجه گرفت که معادله رگرسیون معنادار است (رابطه ثابت شده است).
8. با استفاده از آماره t Student و با محاسبه فاصله اطمینان برای هر یک از شاخص ها، اهمیت آماری پارامترهای رگرسیون را ارزیابی خواهیم کرد.
ما فرضیه H 0 را در مورد تفاوت آماری ناچیز شاخص ها از صفر مطرح می کنیم:
![]() .
.
![]() برای تعداد درجات آزادی
برای تعداد درجات آزادی
شکل 7 مقادیر واقعی آماره t را نشان می دهد:
آزمون t برای ضریب همبستگی را می توان به دو روش محاسبه کرد:
من راه:
جایی که  - خطای تصادفی ضریب همبستگی.
- خطای تصادفی ضریب همبستگی.
داده ها را برای محاسبه از جدول شکل 7 می گیریم.

راه دوم:
مقادیر آماری t واقعی نسبت به مقادیر جدول برتری دارند:
بنابراین، فرضیه H 0 رد می شود، یعنی پارامترهای رگرسیون و ضریب همبستگی به طور تصادفی با صفر تفاوت ندارند، اما از نظر آماری معنادار هستند.
فاصله اطمینان برای پارامتر a به صورت تعریف شده است
![]()
برای پارامتر a، کران های 95%، همانطور که در شکل 7 نشان داده شده است، عبارت بودند از:
فاصله اطمینان برای ضریب رگرسیون به صورت تعریف شده است
![]()
برای ضریب رگرسیون b، کران های 95% همانطور که در شکل 7 نشان داده شده است:
![]()
تجزیه و تحلیل مرزهای بالا و پایین فواصل اطمینان به این نتیجه می رسد که با یک احتمال ![]() پارامترهای a و b که در محدوده های مشخص شده قرار دارند، مقادیر صفر را نمی گیرند، یعنی. از نظر آماری معنی دار نیستند و تفاوت معنی داری با صفر دارند.
پارامترهای a و b که در محدوده های مشخص شده قرار دارند، مقادیر صفر را نمی گیرند، یعنی. از نظر آماری معنی دار نیستند و تفاوت معنی داری با صفر دارند.
7. برآوردهای به دست آمده از معادله رگرسیون به ما امکان می دهد از آن برای پیش بینی استفاده کنیم. اگر مقدار پیشبینی حداقل معیشت:
سپس مقدار پیشبینیشده حداقل معیشت به صورت زیر خواهد بود:
خطای پیش بینی را با استفاده از فرمول محاسبه می کنیم:

جایی که ![]()
ما همچنین واریانس را با استفاده از Excel PPP محاسبه می کنیم. برای این:
1) فعال کنید Function Wizard: در منوی اصلی، را انتخاب کنید فرمول ها / درج تابع.
3) محدوده حاوی داده های عددی مشخصه عامل را پر کنید. کلیک خوب.

شکل 10 محاسبه واریانس
مقدار واریانس را دریافت کنید ![]()
برای محاسبه واریانس باقیمانده به ازای یک درجه آزادی، از نتایج تحلیل واریانس همانطور که در شکل 7 نشان داده شده است استفاده می کنیم.

فواصل اطمینان برای پیش بینی مقادیر فردی y در با احتمال 0.95 با عبارت:
![]()
این فاصله بسیار گسترده است، در درجه اول به دلیل حجم کم مشاهدات. به طور کلی، پیش بینی برآورده شده از میانگین حقوق ماهانه قابل اعتماد بود.
شرط مسئله از: Workshop on Econometrics: Proc. کمک هزینه / I.I. السیوا، اس.و. کوریشوا، ن.م. گوردینکو و دیگران؛ اد. I.I. السیوا - م.: امور مالی و آمار، 1382. - 192 ص: بیمار.