STATISTICA'da standart regresyon analizi. Regresyon istatistikleri
Öyle varsayılıyor - bağımsız değişkenler (yordayıcılar, açıklayıcı değişkenler) bağımlı değişkenlerin (yanıtlar, açıklayıcı değişkenler) değerlerini etkiler. Mevcut ampirik verilere göre, değişim sırasındaki değişimi yaklaşık olarak tanımlayacak bir fonksiyonun oluşturulması gerekmektedir:
.
Aralarından seçilen kabul edilebilir işlevler kümesinin parametrik olduğu varsayılmaktadır:
 ,
,
bilinmeyen bir parametre nerede (genel olarak konuşursak, çok boyutlu). İnşa ederken şunu varsayacağız:
 , (1)
, (1)
birinci terimin düzenli bir değişim olduğu ve ikincisinin sıfır ortalamalı rastgele bir bileşen olduğu; bilinen koşul altında koşullu bir beklentidir ve regresyon olarak adlandırılır.
İzin vermek N faktörlerin değerlerinin ve değişkenin karşılık gelen değerlerinin çarpımı ölçülür sen; öyle varsayılıyor
(2)
(ikinci indeks X faktör numarasını, ilki ise gözlem sayısını ifade eder); aynı zamanda varsayılmaktadır
 (3)
(3)
onlar. ilişkisiz rastgele değişkenlerdir. İlişkiler (2) uygun şekilde matris formunda yazılır:
, (4)
Nerede  - bağımlı değişken değerlerinin sütun vektörü, T- aktarma sembolü,
- bağımlı değişken değerlerinin sütun vektörü, T- aktarma sembolü,  - sütun vektörü (boyutlar k) bilinmeyen regresyon katsayıları, - rastgele sapmaların vektörü,
- sütun vektörü (boyutlar k) bilinmeyen regresyon katsayıları, - rastgele sapmaların vektörü,

-matris ; V Ben-th satırı bağımsız değişkenlerin değerlerini içerir Ben Gözleme göre, ilk değişken 1'e eşit bir sabittir.
başlangıca
Regresyon katsayılarının tahmini
Bağımlı değişkenin tahmin vektörü, verilen değerlerin vektöründen minimum düzeyde farklı olacak şekilde (farkın kare normu anlamında) vektör için bir tahmin oluşturalım:
.
Çözüm (matrisin rütbesi ise k+1) seviye
 (5)
(5)
Tarafsız olup olmadığını kontrol etmek kolaydır.
başlangıca
Oluşturulan regresyon modelinin yeterliliğinin kontrol edilmesi
Değeri, regresyon modelinden elde edilen değer ve örnek ortalamanın önemsiz tahmininin değeri arasında aşağıdaki ilişki vardır:
 ,
,
Nerede .
Temel olarak sol taraftaki terim ortalamaya ilişkin toplam hatayı tanımlar. Sağ taraftaki ilk terim () regresyon modeliyle ilişkili hatayı, ikinci terim () ise rastgele sapmalar ve açıklanamayan yerleşik modelle ilişkili hatayı tanımlar.
Her iki parçayı da tam bir oyuncu çeşitliliğine bölerek  , belirleme katsayısını elde ederiz:
, belirleme katsayısını elde ederiz:
 (6)
(6)
Katsayı, regresyon modelinin gözlenen değerlere uyum kalitesini gösterir. Eğer öyleyse, o zaman regresyon, önemsiz tahminle karşılaştırıldığında tahminin kalitesini artırmaz.
Diğer uç durum ise tam uyum anlamına gelir: all , yani. tüm gözlem noktaları regresyon düzleminde yer alır.
Ancak regresyondaki değişken (regresör) sayısı arttıkça değer artar, bu da tahminin kalitesinde bir iyileşme anlamına gelmez ve bu nedenle düzeltilmiş bir belirleme katsayısı devreye girer.
 (7)
(7)
Değişken sayısı (regresör) değiştiğinde regresyonları karşılaştırmak için kullanımı daha doğrudur.
Regresyon katsayıları için güven aralıkları. Tahminin standart hatası, tahminin geçerli olduğu değerdir.
 (8)
(8)
matrisin köşegen elemanı nerede Z. Hatalar normal olarak dağılıyorsa, yukarıdaki 1) ve 2) özelliklerinden dolayı istatistikler
 (9)
(9)
Öğrenci yasasına göre serbestlik dereceleriyle dağıtılır ve dolayısıyla eşitsizlik
, (10)
bu dağılımın düzey kantili nerede, güven düzeyi ile güven aralığını belirtir.
Regresyon katsayılarının sıfır değerlerine ilişkin hipotezin test edilmesi. Bir dizi faktör arasında herhangi bir doğrusal ilişkinin bulunmadığına ilişkin hipotezi test etmek; katsayılar hariç tüm katsayıların sıfıra eşzamanlı eşitliği hakkında sabit istatistikler kullanılır
 , (11)
, (11)
eğer doğruysa Fisher kanununa göre dağıtılır. k ve serbestlik dereceleri. eğer reddedilirse
 (12)
(12)
seviye kantili nerede.
başlangıca
Veri Açıklaması ve Sorun Bildirimi
Kaynak veri dosyası tube_dataset.sta 10 değişken ve 33 gözlem içermektedir. Bkz. 1.

Pirinç. 1. tube_dataset.sta dosyasındaki ilk veri tablosu
Gözlemlerin adı zaman aralığını gösterir: çeyrek ve yıl (sırasıyla noktadan önce ve sonra). Her gözlem karşılık gelen zaman aralığına ait verileri içerir. Şekil 10'da "Çeyrek" değişkeni gözlem adındaki çeyrek sayısını çoğaltır. Değişkenlerin listesi aşağıda verilmiştir.

Hedef: 9 numaralı "Boru tüketimi" değişkeni için bir regresyon modeli oluşturun.
Çözüm adımları:
1) İlk olarak, aykırı değerler ve anlamlı olmayan veriler (bina çizgi grafikleri ve dağılım grafikleri) için mevcut verilerin keşifsel bir analizini gerçekleştireceğiz.
2) Gözlemler ve değişkenler arasındaki olası bağımlılıkların varlığını kontrol edelim (korelasyon matrislerinin oluşturulması).
3) Gözlemler gruplar oluşturacaksa, her grup için "Boru tüketimi" değişkeni için bir regresyon modeli oluşturacağız (çoklu regresyon).
Tablodaki değişkenleri sırasıyla yeniden numaralandıralım. Bağımlı değişken (yanıt) "Boru tüketimi" değişkeni olarak adlandırılacaktır. Diğer tüm değişkenlere bağımsız (tahmin edici) diyoruz.
başlangıca
Sorunu adım adım çözme
Aşama 1. Dağılım diyagramları (bkz. Şekil 2.) herhangi bir belirgin aykırı değer ortaya çıkarmadı. Aynı zamanda birçok grafikte doğrusal bir ilişki açıkça görülmektedir. 2000 yılının 4 çeyreğine ait "Boru Tüketimi" verileri de eksik.

Pirinç. 2. Bağımlı değişken (#9) ve kuyucuk sayısının (#8) dağılım grafiği
X ekseni boyunca işaretlerde E sembolünden sonraki sayı, 8 numaralı değişkenin (İşletme kuyusu sayısı) değerlerinin sırasını belirleyen 10 sayısının gücünü gösterir. Bu durumda yaklaşık 100.000 kuyu (10'un 5'inci kuvveti) değerinden bahsediyoruz.
Şekil 2'deki dağılım diyagramında. Şekil 3 (aşağıya bakınız) açıkça 2 nokta bulutunu göstermektedir ve her birinin net bir doğrusal ilişkisi vardır.
1 numaralı değişkenin regresyon modeline dahil edilmesinin muhtemel olduğu açıktır, çünkü Bizim görevimiz, öngörücüler ile yanıt arasındaki doğrusal ilişkiyi tam olarak belirlemektir.

Pirinç. 3. Bağımlı değişkenin (#9) ve Petrol endüstrisine yatırımın (#1) dağılım grafiği
Adım 2 Zamana bağlı olarak tüm değişkenlerin çizgi grafiklerini oluşturalım. Grafiklerden pek çok değişkene ilişkin verilerin çeyrek sayısına bağlı olarak büyük ölçüde değiştiği ancak yıldan yıla büyümenin devam ettiği görülüyor.
Elde edilen sonuç, Şekil 1'e dayanarak elde edilen varsayımları doğrulamaktadır. 3.

Pirinç. 4. 1. değişkenin zamana karşı çizgi grafiği
Özellikle, şek. Şekil 4, birinci değişken için bir çizgi grafiğidir.
Aşama 3Şekil sonuçlarına göre. 3 ve Şek. Şekil 4'te gözlemleri 10 numaralı "Çeyrek" değişkenine göre 2 gruba ayırıyoruz. İlk grup 1. ve 4. çeyreğe ait verileri, ikinci grup ise 2. ve 3. çeyreğe ait verileri içerecektir.
Gözlemleri çeyreklere göre 2 tabloya bölmek için öğeyi kullanacağız Veri/Altküme/Rastgele. Burada gözlem olarak QUARTER değişkeninin değerlerine ilişkin koşulları belirtmemiz gerekiyor. Görmek pirinç. 5.
Belirtilen koşullara göre gözlemler yeni bir tabloya kopyalanacaktır. Aşağıdaki satırda belirli gözlem sayılarını belirtebilirsiniz ancak bizim durumumuzda bu uzun zaman alacaktır.

Pirinç. 5. Tablodan bir gözlem alt kümesinin seçilmesi
Belirli bir koşul olarak şunları belirledik:
V10 = 1 VEYA V10 = 4
V10 tablodaki 10. değişkendir (V0 gözlem sütunudur). Aslında tablodaki her gözlemin 1. çeyreğe mi yoksa 4. çeyreğe mi ait olduğunu kontrol ediyoruz. Farklı bir gözlem alt kümesi seçmek istersek koşulu şu şekilde değiştirebiliriz:
V10=2 VEYA V10=3
veya ilk koşulu kuralları hariç tutmaya taşıyın.
Tıklama TAMAM, önce yalnızca 1. ve 4. çeyreğe ait verileri içeren bir tablo, ardından 2. ve 3. çeyreğe ait verileri içeren bir tablo elde edeceğiz. Bunları isimler altında saklayalım 1_4.sta Ve 2_3.sta sekme aracılığıyla Dosya/Farklı Kaydet.
Daha sonra iki tabloyla çalışacağız ve her iki tablonun regresyon analizi sonuçları karşılaştırılabilir.
4. Adım Doğrusal bir ilişki varsayımını test etmek ve bir regresyon modeli oluştururken değişkenler arasındaki olası güçlü korelasyonları hesaba katmak amacıyla her bir grup için bir korelasyon matrisi oluşturacağız. Eksik veriler olduğundan, eksik verilerin ikili olarak çıkarılması seçeneği ile korelasyon matrisi oluşturulmuştur. Bkz. 6.

Pirinç. 6. 1. ve 4. çeyrek verilerine göre ilk 9 değişkene ilişkin korelasyon matrisi
Özellikle korelasyon matrisinden bazı değişkenlerin birbirleriyle çok güçlü korelasyona sahip olduğu açıkça görülmektedir.
Büyük korelasyon değerlerinin güvenilirliğinin ancak orijinal tabloda aykırı değerlerin olmaması durumunda mümkün olduğu unutulmamalıdır. Bu nedenle korelasyon analizinde bağımlı değişkene ve diğer tüm değişkenlere ait dağılım grafikleri dikkate alınmalıdır.
Örneğin, değişken #1 ve #2 (Sırasıyla petrol ve gaz endüstrisindeki yatırımlar). Bkz. şekil 7 (veya örneğin şekil 8).

Pirinç. 7. Değişken #1 ve #2 için dağılım grafiği

Pirinç. 8. Değişken #1 ve #7 için dağılım grafiği
Bu bağımlılık kolayca açıklanabilir. Petrol ve gaz üretim hacimleri arasındaki yüksek korelasyon katsayısı da açıktır.
Bir regresyon modeli oluştururken değişkenler arasındaki yüksek korelasyon katsayısı (çoklu doğrusallık) dikkate alınmalıdır. Burada, regresyon katsayıları hesaplanırken büyük hatalar meydana gelebilir (en küçük kareler üzerinden tahmin hesaplanırken kötü koşullandırılmış matris).
İşte düzeltmenin en yaygın yolları çoklu bağlantı:
1) Ridge regresyonu.
Bu seçenek çoklu regresyon oluşturulurken ayarlanır. Sayı küçük bir pozitif sayıdır. Bu durumda en küçük karelerin tahmini şuna eşittir:
 ,
,
Nerede e bağımlı değişkenin değerlerine sahip bir vektördür, X sütunlardaki tahmin değerlerini içeren bir matristir ve n + 1 mertebesinde bir kimlik matrisidir. (n, modeldeki öngörücülerin sayısıdır).
Sırt regresyonunda matris kötü koşullanması önemli ölçüde azalır.
2) Açıklayıcı değişkenlerden birinin hariç tutulması.
Bu durumda, başka bir yordayıcıyla ikili korelasyon katsayısı yüksek (r>0,8) olan bir açıklayıcı değişken analizin dışında bırakılır.
3) Tahminci dahil etme/hariç tutma ile adım adım prosedürleri kullanma.
Genellikle bu gibi durumlarda ya sırt regresyonu kullanılır (çoklu oluştururken bir seçenek olarak ayarlanır), ya da korelasyon değerlerine dayanarak yüksek ikili korelasyon katsayısına (r > 0,8) sahip açıklayıcı değişkenler hariç tutulur ya da adım adım regresyon kullanılır. dahil etme / hariç tutma değişkenleri ile.
Adım 5Şimdi açılır menü sekmesini kullanarak bir regresyon modeli oluşturalım ( Analiz/Çoklu Regresyon). Bağımlı değişken olarak “Boru tüketimini” bağımsız değişken olarak belirtiyoruz - geri kalan her şeyi. Bkz. 9.

Pirinç. 9. Tablo 1_4.sta için çoklu regresyon oluşturmak
Çoklu regresyon adım adım yapılabilir. Bu durumda model, bu adımda regresyona en büyük (en az) katkıyı sağlayan değişkenleri adım adım dahil edecek (veya hariç tutacaktır).
Ayrıca bu seçenek, belirleme katsayısının henüz en büyük olmadığı ancak modelin tüm değişkenlerinin zaten önemli olduğu bir adımda durmanıza olanak tanır. Bkz. 10.

Pirinç. 10. Tablo 1_4.sta için çoklu regresyon oluşturmak
Değişken sayısının gözlem sayısından fazla olması durumunda, dahil etme ile adım adım regresyonun bir regresyon modeli oluşturmanın tek yolu olduğunu özellikle belirtmek gerekir.
Regresyon modelinin serbest terimini sıfıra ayarlamak, tüm tahmin edicilerin 0'a eşit olduğu ortaya çıktığında modelin fikrinin sıfır yanıt değerini ima etmesi durumunda kullanılır. Çoğu zaman, bu tür durumlar ekonomik problemlerde ortaya çıkar.
Bizim durumumuzda serbest terimi modele dahil edeceğiz.

Pirinç. 11. Tablo 1_4.sta için çoklu regresyon oluşturmak
Modelin parametreleri olarak seçiyoruz İstisnalarla adım adım(Fon = 11, Foff = 10), sırt regresyonuyla (lambda = 0,1). Ve her grup için bir regresyon modeli oluşturacağız. Bkz. şekil.11.
Formdaki sonuçlar Nihai regresyon tablosu(ayrıca bkz. şekil 14) şekil 12 ve şekil 13'te gösterilmektedir. Regresyonun son adımında elde edilirler.
Adım 6Modelin yeterliliğinin kontrol edilmesi
Regresyon modelindeki tüm değişkenlerin önemine rağmen (p düzeyi< 0.05 – подсвечены красным цветом), коэффициент детерминации R2 существенно меньше у первой группы наблюдений.
Belirleme katsayısı aslında oluşturulan modeldeki yordayıcıların etkisiyle yanıt varyansının ne kadarının açıklandığını gösterir. R2 1'e ne kadar yakınsa model o kadar iyidir.
Fisher'in F istatistiği, regresyon katsayılarının sıfır değerleri hakkındaki hipotezi test etmek için kullanılır (yani, katsayı dışında faktörler kümesi ile arasında herhangi bir doğrusal ilişkinin bulunmaması). Hipotez düşük anlamlılık düzeyinde reddedilir.
Bizim durumumuzda (bkz. Şekil 12), p anlamlılık düzeyinde F istatistiğinin değeri = 13.249< 0,00092, т.е. гипотеза об отсутствии линейной связи отклоняется.

Pirinç. 12. 1. ve 4. çeyrek verilerinin regresyon analizi sonuçları

Pirinç. 13. 2. ve 3. çeyreğe ait verilerin regresyon analizi sonuçları
Adım 7Şimdi ortaya çıkan modelin artıklarını analiz edelim. Artıkların analizinden elde edilen sonuçlar, oluşturulan modelin yeterliliği kontrol edilirken belirleme katsayısının değerine önemli bir katkı sağlar.
Basitlik açısından, yalnızca 2 ve 3 numaralı çeyreklere bölünmüş grubu ele alacağız, çünkü ikinci grup da benzer şekilde incelenir.
Şekil 2'de gösterilen pencerede. 14, sekme Artıklar/tahmin edilen/gözlenen değerler düğmesine basın Kalıntı analizi ve ardından düğmeye tıklayın Kalan ve tahmin edilen. (Bkz. şekil 15)
Düğme Kalıntı analizi yalnızca son adımda regresyon elde edilirse aktif olacaktır. Çoğu zaman, tüm yordayıcıların anlamlı olduğu bir regresyon modeli elde etmek, modeli oluşturmaya devam etmekten (belirleme katsayısını artırarak) ve önemsiz yordayıcılar elde etmekten daha önemlidir.
Bu durumda regresyon son adımda durmadığında regresyondaki adım sayısını yapay olarak ayarlayabilirsiniz.

Pirinç. 14. 2. ve 3. çeyreğe ait veriler için çoklu regresyon sonuçlarını gösteren pencere

Pirinç. 15. 2. ve 3. çeyrek verilerine göre regresyon modelinin artıkları ve tahmin edilen değerleri
Şekil 2'de sunulan sonuçlar hakkında yorum yapalım. 15. Önemli olan sütun kalanlar(ilk 2 sütunun farkı). Birçok gözlemde büyük artıklar ve küçük bir artık içeren bir gözlemin varlığı, ikincisinin aykırı değer olduğunu gösterebilir.
Başka bir deyişle, analiz sonuçlarının geçerliliğini tehdit eden varsayımlardan sapmaların kolaylıkla tespit edilebilmesi için artık analizine ihtiyaç duyulmaktadır.

Pirinç. 16. 2 ve 3 çeyrek + 0,95 güven aralığının 2 limiti verilerine göre regresyon modelinin artıkları ve tahmin edilen değerleri
Sonunda, Şekil 1'deki tablodan elde edilen verileri gösteren bir grafik sunuyoruz. 16. Buraya 2 değişken eklendi: UCB ve LCB - 0,95 üst. ve daha aşağıda Dov. aralık.
UBC=V2+1,96*V6
LBC=V2-1,96*V6
Ve son dört gözlemi kaldırdık.
Değişkenlerle bir çizgi grafiği oluşturalım ( Değişkenler için Grafikler/2M Grafikler/Çizgi Grafikleri)
1) Gözlemlenen değer (V1)
2) Tahmin edilen değer (V2)
3) UCB (V9)
4) LCB (V10)
Sonuç Şekil 2'de gösterilmektedir. 17. Artık, oluşturulan regresyon modelinin, özellikle yakın geçmişteki sonuçlara bakıldığında, gerçek boru tüketimini oldukça iyi yansıttığı açıktır.
Bu, yakın gelecekte gerçek değerlerin model değerlere yakın olabileceği anlamına gelir.
Önemli bir noktaya dikkat edelim. Regresyon modelleri ile tahminde temel zaman aralığı her zaman önemlidir. Ele alınan problemde çeyrekler seçildi.
Buna göre tahmin oluştururken tahmin edilen değerler de çeyreklere göre elde edilecektir. Bir yıl için tahmin almanız gerekiyorsa, 4 çeyrek için tahmin yapmanız gerekecek ve sonunda büyük bir hata birikecektir.
Benzer bir sorun, başlangıçta yalnızca üç aylık dönemden yıllara kadar verilerin toplanmasıyla (örneğin ortalama alınarak) benzer şekilde çözülebilir. Bu problem için yaklaşım pek doğru değildir, çünkü regresyon modelini oluşturmak için kullanılacak yalnızca 8 gözlem kalacaktır. Bkz. şekil 18.

Pirinç. 17. Gözlemlenen ve tahmin edilen değerler 0,95 üst ile birlikte. ve daha aşağıda güven aralıklar (2 ve 3 çeyreklik veriler)

Pirinç. 18. Gözlemlenen ve tahmin edilen değerler 0,95 üst ile birlikte. ve daha aşağıda güven aralıklar (yıllara göre veriler)
Çoğu zaman bu yaklaşım, verileri aylara göre toplarken, ilk veriler günlere göre toplanırken kullanılır.
Tüm regresyon analizi yöntemlerinin yalnızca sayısal ilişkileri tespit edebildiği ve altta yatan nedensel ilişkileri tespit edemediği unutulmamalıdır. Bu nedenle, ortaya çıkan modelde değişkenlerin önemi hakkındaki sorunun cevabı, özellikle bu tabloda yer almayan faktörlerin etkisini hesaba katabilen bu alanda uzman bir kişiye kalmıştır.
1908 yılına dayanan eserlerinde. Bunu, emlak satan bir acentenin işi örneğini kullanarak anlattı. Ev satış uzmanı, notlarında her bir bina için geniş bir yelpazedeki girdi verilerinin kaydını tuttu. Açık artırma sonuçlarına göre hangi faktörün işlem fiyatı üzerinde en büyük etkiye sahip olduğu belirlendi.
Analiz Büyük bir sayı verilen fırsatlar ilginç sonuçlar. Pek çok faktör nihai fiyatı etkiledi; bazen paradoksal sonuçlara ve hatta yüksek başlangıç potansiyeline sahip bir ev daha düşük bir fiyat göstergesiyle satıldığında açıkça "aykırı değerlere" yol açtı.
Böyle bir analizin uygulanmasının ikinci örneği, çalışanların ücretlerinin belirlenmesiyle görevlendirilen iştir. Görevin karmaşıklığı, sabit bir miktarın herkese dağıtılmasının gerekmemesi, bunun yerine değerinin gerçekleştirilen spesifik işle tam olarak eşleştirilmesinin gerekli olmasıydı. Pratik olarak benzer çözümlere sahip birçok problemin ortaya çıkması, bunların matematiksel düzeyde daha ayrıntılı bir şekilde incelenmesini gerektirdi.
"Regresyon analizi" bölümüne önemli bir yer verildi, pratik yöntemler Regresyon kavramı kapsamına giren bağımlılıkları incelemek için kullanılır. Bu ilişkiler istatistiksel çalışmalar sırasında elde edilen veriler arasında gözlenmektedir.
Çözülmesi gereken birçok görev arasında kendisine üç ana hedef belirledi: regresyon denkleminin tanımı Genel görünüm; regresyon denkleminin parçası olan bilinmeyen parametrelerin tahminlerinin oluşturulması; İstatistiksel regresyon hipotezlerinin test edilmesi. Deneysel gözlemler sonucunda elde edilen ve (x1, y1), ..., (xn, yn) türünde bir dizi (küme) oluşturan bir çift miktar arasında ortaya çıkan ilişkiyi incelerken, şunlara güvenirler: regresyon teorisinin hükümlerine göre hareket eder ve bir Y miktarı için belirli bir olasılık dağılımının gözlemlendiğini, diğer X'in ise sabit kaldığını varsayar.
Y sonucu, X değişkeninin değerine bağlıdır, bu bağımlılık çeşitli kalıplarla belirlenebilirken, elde edilen sonuçların doğruluğu gözlemlerin doğasından ve analizin amacından etkilenir. Deneysel model basit fakat makul olan belirli varsayımlara dayanmaktadır. Ana koşul, X parametresinin kontrollü bir değer olmasıdır. Değerleri deneyin başlamasından önce ayarlanır.
Deney sırasında bir çift kontrolsüz XY değişkeni kullanılırsa, regresyon analizi aynı şekilde gerçekleştirilir, ancak incelenen rastgele değişkenlerin ilişkisinin incelendiği sonuçları yorumlamak için yöntemler kullanılır. matematiksel istatistik soyut bir konu değildir. Hayattaki uygulamalarını insan faaliyetinin çeşitli alanlarında bulurlar.
Bilimsel literatürde doğrusal regresyon analizi terimi yukarıdaki yöntemi tanımlamak için geniş kullanım alanı bulmuştur. X değişkeni için regresör veya yordayıcı terimi kullanılır ve bağımlı Y değişkenleri aynı zamanda kriter değişkenleri olarak da adlandırılır. Bu terminoloji değişkenlerin yalnızca matematiksel bağımlılığını yansıtır, nedensel-nedensel ilişkileri yansıtmaz.
Regresyon analizi, çok çeşitli gözlemlerin sonuçlarının işlenmesinde kullanılan en yaygın yöntemdir. Fiziksel ve biyolojik bağımlılıklar araştırılıyor Bu method Hem ekonomide hem de teknolojide uygulanmaktadır. Pek çok başka alanda modeller kullanılıyor regresyon analizi. dağılım analizi, istatistiksel analizçok boyutlu çalışma bu çalışma şekliyle yakından ilişkilidir.
sen=F(X), bağımsız değişkenin her değeri X miktarın belirli bir değerine karşılık gelir sen, aynı değere regresyon ilişkisi ile X duruma bağlı olarak miktarın farklı değerlerine karşılık gelebilir sen. Her değerde varsa n ben (\displaystyle n_(i)) değerler sen Ben 1 …sen içinde 1 büyüklük sen, o zaman aritmetik ortalamanın bağımlılığı y ¯ ben = (y ben 1 + . . . + y ben n 1) / n ben (\displaystyle (\bar (y))_(i)=(y_(i1)+...+y_(in_(1))) /n_(i)) itibaren x = x ben (\displaystyle x=x_(i)) ve terimin istatistiksel anlamında bir gerilemedir.Ansiklopedik YouTube
-
1 / 5
Bu terim istatistiklerde ilk kez Francis Galton (1886) tarafından insanın fiziksel özelliklerinin kalıtımı üzerine yapılan çalışmalarla bağlantılı olarak kullanılmıştır. Özelliklerden biri olarak insan boyu alındı; genel olarak uzun babaların oğullarının, şaşırtıcı olmayan bir şekilde, kısa boylu babaların oğullarından daha uzun olduğu tespit edildi. Daha da ilginci, oğulların boylarındaki değişimin babaların boylarındaki değişimden daha küçük olmasıydı. Dolayısıyla erkek çocukların büyümesinin ortalamaya dönme eğilimi vardı ( sıradanlığa gerileme), yani "gerileme". Bu gerçek, 56 inç boyundaki babaların oğullarının ortalama boylarının hesaplanmasıyla, 58 inç boyundaki baba oğullarının ortalama boylarının hesaplanmasıyla vb. ve apsis boyunca - değerlerle gösterilmiştir. babaların ortalama boy uzunluğu. Noktalar (yaklaşık olarak) pozitif eğimi 45°'den az olan düz bir çizgi üzerinde uzanır; regresyonun doğrusal olması önemlidir.
Tanım
Bir çift rastgele değişkenin iki boyutlu dağılımından bir örnek olduğunu varsayalım ( X, Y). Düzlemdeki düz çizgi ( x, y) fonksiyonun seçici bir analoguydu
g (x) = E (Y ∣ X = x) . (\displaystyle g(x)=E(Y\mid X=x).) E (Y ∣ X = x) = μ 2 + ϱ σ 2 σ 1 (x − μ 1) , (\displaystyle E(Y\mid X=x)=\mu _(2)+\varrho (\frac ( \sigma _(2))(\sigma _(1)))(x-\mu _(1))),) v a r (Y ∣ X = x) = σ 2 2 (1 - ϱ 2) . (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2))).)Bu örnekte regresyon e Açık X'nin doğrusal bir fonksiyonudur. Regresyon ise e Açık X doğrusaldan farklıysa, verilen denklemler gerçek regresyon denkleminin doğrusal bir yaklaşımıdır.
Genel olarak bir rastgele değişkenin diğerine regresyonu mutlaka doğrusal olmayacaktır. Kendinizi birkaç rastgele değişkenle sınırlamanıza da gerek yok. Regresyonun istatistiksel problemleri, regresyon denkleminin genel formunun belirlenmesi, regresyon denkleminde yer alan bilinmeyen parametrelerin tahminlerinin oluşturulması ve regresyonla ilgili istatistiksel hipotezlerin test edilmesiyle ilgilidir. Bu problemler regresyon analizi çerçevesinde ele alınmaktadır.
Basit bir örnek gerileme eİle X arasındaki ilişki e Ve X oran ile ifade edilir: e=sen(X)+ε, burada sen(X)=e(e | X=X), A rastgele değişkenler X ve ε bağımsızdır. Bu gösterim, fonksiyonel bağlantıyı incelemek için bir deney planlandığında faydalıdır. sen=sen(X) rastgele olmayan değişkenler arasında sen Ve X. Uygulamada genellikle denklemdeki regresyon katsayıları sen=sen(X) bilinmemektedir ve deneysel verilerden tahmin edilmektedir.
Doğrusal Regresyon
Bir bağımlılık hayal edin sen itibaren X birinci dereceden doğrusal bir model biçiminde:
y = β 0 + β 1 x + ε . (\displaystyle y=\beta _(0)+\beta _(1)x+\varepsilon .)Değerlerin olduğunu varsayacağız X hatasız olarak belirlenir, β 0 ve β 1 model parametreleridir ve ε, dağılımı sıfır ortalama ve sabit sapma σ 2 ile normal yasaya uyan bir hatadır. β parametrelerinin değerleri önceden bilinmemektedir ve bir dizi deneysel değerden belirlenmelidir ( x ben y ben), Ben=1, …, N. Böylece şunu yazabiliriz:
y ben ^ = b 0 + b 1 x ben , i = 1 , … , n (\displaystyle (\widehat (y_(i)))=b_(0)+b_(1)x_(i),i=1,\ noktalar, n)burada model tarafından tahmin edilen değer anlamına gelir sen verildi X, B 0 ve B 1 - model parametrelerinin örnek tahminleri. Biz de tanımlıyoruz e ben = y ben - y ben ^ (\displaystyle e_(i)=y_(i)-(\widehat (y_(i))))- yaklaşıklık hatasının değeri ben (\displaystyle i) gözlem.
En küçük kareler yöntemi, bu modelin parametrelerini ve sapmalarını hesaplamak için aşağıdaki formülleri verir:
b 1 = ∑ ben = 1 n (x ben − x ¯) (y ben − y ¯) ∑ ben = 1 n (x ben − x ¯) 2 = c Ö v (x , y) σ x 2 ; (\displaystyle b_(1)=(\frac (\toplam _(i=1)^(n)(x_(i)-(\bar (x)))(y_(i)-(\bar (y) ))))(\toplam _(i=1)^(n)(x_(i)-(\bar (x)))^(2))))=(\frac (\mathrm (cov) (x,y) ))(\sigma _(x)^(2)));) b 0 = y ¯ − b 1 x ¯ ; (\displaystyle b_(0)=(\bar (y))-b_(1)(\bar (x));) s e 2 = ∑ ben = 1 n (y ben - y ^) 2 n - 2 ; (\displaystyle s_(e)^(2)=(\frac (\sum _(i=1)^(n)(y_(i)-(\widehat (y)))^(2))(n- 2));) s b 0 = s e 1 n + x ¯ 2 ∑ ben = 1 n (x ben − x ¯) 2 ; (\displaystyle s_(b_(0))=s_(e)(\sqrt ((\frac (1)(n))+(\frac ((\bar (x))^(2))(\sum _ (i=1)^(n)(x_(i)-(\bar (x))))^(2)))));) s b 1 = s e 1 ∑ ben = 1 n (x ben − x ¯) 2 , (\displaystyle s_(b_(1))=s_(e)(\sqrt (\frac (1)(\sum _(i=1) )^(n)(x_(i)-(\bar (x)))^(2))))),)burada ortalamalar her zamanki gibi tanımlanır: x ¯ = ∑ ben = 1 n x ben n (\displaystyle (\bar (x))=(\frac (\sum _(i=1)^(n)x_(i))(n))), y ¯ = ∑ ben = 1 n y ben n (\displaystyle (\bar (y))=(\frac (\sum _(i=1)^(n)y_(i))(n))) Ve e 2, model doğruysa σ 2 varyansının tahmini olan regresyon kalıntısını belirtir.
Regresyon katsayılarının standart hataları benzer şekilde kullanılır standart hata ortalama - güven aralıklarını bulmak ve hipotezleri test etmek için. Örneğin, regresyon katsayısının sıfıra eşit olduğu, yani model için önemsiz olduğu hipotezini test etmek için Öğrenci kriterini kullanırız. Öğrenci istatistikleri: t = b / s b (\displaystyle t=b/s_(b)). Elde edilen değerin olasılığı ve N−2 serbestlik derecesi yeterince küçüktür, örneğin,<0,05 - гипотеза отвергается. Напротив, если нет оснований отвергнуть гипотезу о равенстве нулю, скажем, b 1 (\displaystyle b_(1))- İstenilen regresyonun en azından bu biçimde varlığını düşünmek veya ek gözlemler toplamak için bir neden var. Serbest terim sıfıra eşitse b 0 (\displaystyle b_(0)), daha sonra çizgi orijinden geçer ve eğimin tahmini
b = ∑ ben = 1 n x ben y ben ∑ ben = 1 n x ben 2 (\displaystyle b=(\frac (\sum _(i=1)^(n)x_(i)y_(i))(\sum _(i= 1)^(n)x_(i)^(2)))),ve standart hatası
s b = s e 1 ∑ ben = 1 n x ben 2 . (\displaystyle s_(b)=s_(e)(\sqrt (\frac (1)(\sum _(i=1)^(n)x_(i)^(2))))).)Genellikle regresyon katsayıları β 0 ve β 1'in gerçek değerleri bilinmemektedir. Sadece tahminleri biliniyor B 0 ve B 1. Başka bir deyişle, regresyonun gerçek düz çizgisi, örnek veriler üzerine oluşturulandan farklı şekilde ilerleyebilir. Regresyon çizgisinin güven bölgesini hesaplayabilirsiniz. Herhangi bir değer için X karşılık gelen değerler sen normal olarak dağıtılır. Ortalama, regresyon denkleminin değeridir y ^ (\ displaystyle (\ geniş hat (y))). Tahmininin belirsizliği standart regresyon hatasıyla karakterize edilir:
s y ^ = s e 1 n + (x - x ¯) 2 ∑ ben = 1 n (x ben - x ¯) 2 ; (\displaystyle s_(\widehat (y))=s_(e)(\sqrt ((\frac (1)(n))+(\frac ((x-(\bar (x)))^(2) )(\toplam _(i=1)^(n)(x_(i)-(\bar (x)))^(2)))))));)Artık regresyon denkleminin o noktadaki değeri için -yüzdelik güven aralığını hesaplayabilirsiniz. X:
y ^ − t (1 − α / 2 , n − 2) s y ^< y < y ^ + t (1 − α / 2 , n − 2) s y ^ {\displaystyle {\widehat {y}}-t_{(1-\alpha /2,n-2)}s_{\widehat {y}}Nerede T(1−α/2, N−2) - T-Öğrenci dağılım değeri. Şekilde 10 noktalı bir regresyon çizgisi (düz noktalar) ve regresyon çizgisinin noktalı çizgilerle sınırlanan %95 güven bölgesi gösterilmektedir. % 95 olasılıkla gerçek çizginin bu alanın içinde bir yerde olduğu iddia edilebilir. Veya aksi takdirde, benzer veri kümelerini toplarsak (dairelerle gösterilir) ve bunların üzerine regresyon çizgileri (maviyle gösterilir) oluşturursak, o zaman 100 vakadan 95'inde bu çizgiler güven bölgesini terk etmeyecektir. (Görselleştirmek için resme tıklayın) Bazı noktaların güven bölgesinin dışında olduğuna dikkat edin. Değerlerin kendisinden değil, regresyon çizgisinin güven bölgesinden bahsettiğimiz için bu tamamen doğaldır. Değerlerin dağılımı, değerlerin regresyon çizgisi etrafındaki dağılımının ve bu çizginin kendisinin konumunun belirsizliğinin toplamıdır:
s Y = s e 1 m + 1 n + (x − x ¯) 2 ∑ ben = 1 n (x ben − x ¯) 2 ; (\displaystyle s_(Y)=s_(e)(\sqrt ((\frac (1)(m))+(\frac (1)(n))+(\frac ((x-(\bar (x) ))))^(2))(\toplam _(i=1)^(n)(x_(i)-(\bar (x)))^(2)))))));)Burada M- ölçüm çokluğu sen verildi X. VE 100 ⋅ (1 − α 2) (\displaystyle 100\cdot \left(1-(\frac (\alpha )(2))\right))-ortalama için yüzde güven aralığı (tahmin aralığı) M değerler sen irade:
y ^ − t (1 − α / 2 , n − 2) s Y< y < y ^ + t (1 − α / 2 , n − 2) s Y {\displaystyle {\widehat {y}}-t_{(1-\alpha /2,n-2)}s_{Y}Şekilde bu %95 güven bölgesi M=1 düz çizgilerle sınırlanmıştır. Bu alan miktarın olası tüm değerlerinin %95'ini içerir sen incelenen değer aralığında X.
Biraz daha istatistik
Koşullu beklentinin geçerli olduğu kesin olarak kanıtlanabilir. E (Y ∣ X = x) (\displaystyle E(Y\mid X=x)) bazı iki boyutlu rastgele değişken ( X, Y) doğrusal bir fonksiyonudur x (\displaystyle x), o zaman bu koşullu beklenti şu şekilde temsil edilmelidir: E (Y ∣ X = x) = μ 2 + ϱ σ 2 σ 1 (x − μ 1) (\displaystyle E(Y\mid X=x)=\mu _(2)+\varrho (\frac (\ sigma _(2))(\sigma _(1)))(x-\mu _(1))), Nerede e(X)=μ 1 , e(e)=μ 2 , var( X)=σ 1 2 , var( e)=σ 2 2 , cor( X, Y)=ρ.
Ayrıca daha önce bahsedilen doğrusal model için Y = β 0 + β 1 X + ε (\displaystyle Y=\beta _(0)+\beta _(1)X+\varepsilon ), Nerede X (\displaystyle X) ve bağımsız rastgele değişkenlerdir ve ε (\displaystyle \varepsilon) sıfır beklentiye (ve keyfi bir dağılıma) sahipse, şunu kanıtlayabiliriz: E (Y ∣ X = x) = β 0 + β 1 x (\displaystyle E(Y\mid X=x)=\beta _(0)+\beta _(1)x). Daha sonra yukarıdaki eşitliği kullanarak ve için formüller elde edebiliriz: β 1 = ϱ σ 2 σ 1 (\displaystyle \beta _(1)=\varrho (\frac (\sigma _(2))(\sigma _(1)))),
β 0 = μ 2 − β 1 μ 1 (\displaystyle \beta _(0)=\mu _(2)-\beta _(1)\mu _(1))
Düzlemdeki rastgele noktalar kümesinin doğrusal bir model tarafından oluşturulduğu, ancak katsayıları bilinmeyen bir yerden biliniyorsa β 0 (\displaystyle \beta _(0)) Ve β 1 (\displaystyle \beta _(1)) belirtilen formülleri kullanarak bu katsayıların nokta tahminlerini elde edebiliriz. Bunun için bu formüllerde matematiksel beklentiler yerine rastgele değişkenlerin varyansları ve korelasyonları X Ve e onların tarafsız tahminlerini değiştirmeniz gerekir. Elde edilen tahmin formülleri en küçük kareler yöntemine göre elde edilen formüllerle birebir örtüşmektedir.
Regresyon analizinin temel özelliği, incelenen değişkenler arasındaki ilişkinin şekli ve doğası hakkında spesifik bilgi elde etmek için kullanılabilmesidir.
Regresyon analizi aşamalarının sırası
Regresyon analizinin aşamalarını kısaca ele alalım.
Görev formülasyonu. Bu aşamada çalışılan olayın bağımlılığına ilişkin ön hipotezler oluşturulur.
Bağımlı ve bağımsız (açıklayıcı) değişkenlerin tanımı.
İstatistiksel verilerin toplanması. Regresyon modelinde yer alan değişkenlerin her biri için veri toplanmalıdır.
Bağlantı biçimine ilişkin bir hipotezin formüle edilmesi (basit veya çoklu, doğrusal veya doğrusal olmayan).
Tanım regresyon fonksiyonları (regresyon denkleminin parametrelerinin sayısal değerlerinin hesaplanmasından oluşur)
Regresyon analizinin doğruluğunun değerlendirilmesi.
Elde edilen sonuçların yorumlanması. Regresyon analizi sonuçları ön hipotezlerle karşılaştırılır. Elde edilen sonuçların doğruluğu ve inandırıcılığı değerlendirilir.
Bağımlı değişkenin bilinmeyen değerlerinin tahmini.
Regresyon analizi yardımıyla tahmin ve sınıflandırma sorununu çözmek mümkündür. Tahmin değerleri, açıklayıcı değişkenlerin değerlerinin regresyon denkleminde değiştirilmesiyle hesaplanır. Sınıflandırma sorunu şu şekilde çözülür: regresyon çizgisi tüm nesne kümesini iki sınıfa ayırır ve kümenin fonksiyonun değerinin sıfırdan büyük olduğu kısmı bir sınıfa, daha az olduğu kısmı ise bir sınıfa aittir. sıfırdan fazlası başka bir sınıfa aittir.
Regresyon analizinin görevleri
Regresyon analizinin ana görevlerini göz önünde bulundurun: bağımlılık biçimini oluşturmak, belirlemek regresyon fonksiyonları bağımlı değişkenin bilinmeyen değerlerinin bir tahmini.
Bağımlılık formunun oluşturulması.
Değişkenler arasındaki ilişkinin doğası ve şekli aşağıdaki regresyon türlerini oluşturabilir:
pozitif doğrusal regresyon (fonksiyonun düzgün büyümesi olarak ifade edilir);
pozitif düzgün hızlanan regresyon;
pozitif düzgün artan regresyon;
negatif doğrusal regresyon (fonksiyonda tekdüze bir düşüş olarak ifade edilir);
negatif eşit şekilde hızlandırılmış azalan regresyon;
negatif düzgün azalan regresyon.
Ancak açıklanan çeşitler genellikle saf halde değil, birbirleriyle kombinasyon halinde bulunur. Bu durumda, birleşik regresyon biçimlerinden söz edilir.
Regresyon fonksiyonunun tanımı.
İkinci görev, diğer her şey eşit olmak üzere ve rastgele unsurların bağımlı değişken üzerindeki etkisi hariç tutularak, ana faktörlerin veya nedenlerin bağımlı değişken üzerindeki etkisini bulmaktır. regresyon fonksiyonuşu veya bu türden matematiksel bir denklem olarak tanımlanır.
Bağımlı değişkenin bilinmeyen değerlerinin tahmini.
Bu sorunun çözümü, aşağıdaki türlerden birinin sorununu çözmeye indirgenmiştir:
Bağımlı değişkenin değerlerinin, ilk verilerin dikkate alınan aralığı dahilinde tahmini, yani. kayıp değerler; bu enterpolasyon sorununu çözer.
Bağımlı değişkenin gelecekteki değerlerinin tahmin edilmesi, yani. başlangıç verilerinin verilen aralığının dışındaki değerleri bulmak; bu ekstrapolasyon sorununu çözer.
Her iki problem de, bağımsız değişkenlerin değerlerinin parametrelerinin bulunan tahminlerinin regresyon denkleminde değiştirilmesiyle çözülür. Denklemin çözülmesinin sonucu, hedef (bağımlı) değişkenin değerinin bir tahminidir.
Regresyon analizinin dayandığı bazı varsayımlara bakalım.
Doğrusallık varsayımı, yani. ele alınan değişkenler arasındaki ilişkinin doğrusal olduğu varsayılmaktadır. Bu örnekte bir dağılım grafiği oluşturduk ve net bir doğrusal ilişki görebildik. Değişkenlerin dağılım grafiğinde açık bir yokluk görürsek doğrusal bağlantı yani Doğrusal olmayan bir ilişki varsa doğrusal olmayan analiz yöntemleri kullanılmalıdır.
Normallik Varsayımı kalanlar. Tahmin edilen ve gözlemlenen değerler arasındaki farkın dağılımının normal olduğunu varsayar. Dağıtımın doğasını görsel olarak belirlemek için histogramları kullanabilirsiniz. kalanlar.
Regresyon analizini kullanırken, ana sınırlaması dikkate alınmalıdır. Regresyon analizinin, bu bağımlılıkların altında yatan ilişkileri değil, yalnızca bağımlılıkları tespit etmenize izin vermesi gerçeğinden oluşur.
Regresyon analizi, bir değişkenin beklenen değerini bilinen birkaç değere dayanarak hesaplayarak değişkenler arasındaki ilişkinin derecesini değerlendirmeyi mümkün kılar.
Regresyon denklemi.
Regresyon denklemi şuna benzer: Y=a+b*X
Bu denklem kullanılarak Y değişkeni, a sabiti ve çizginin (veya eğimin) b eğiminin X değişkeninin değeriyle çarpılmasıyla ifade edilir. a sabitine aynı zamanda kesişme noktası da denir ve eğim regresyondur. katsayısı veya B faktörü.
Çoğu durumda (her zaman olmasa da) regresyon çizgisine ilişkin gözlemlerin belirli bir dağılımı vardır.
Kalan bireysel bir noktanın (gözlem) regresyon çizgisinden (tahmin edilen değer) sapmasıdır.
MS Excel'de regresyon analizi problemini çözmek için menüden seçim yapın Hizmet"Analiz Paketi" ve Regresyon analiz aracı. X ve Y giriş aralıklarını belirtin. Y giriş aralığı, analiz edilen bağımlı verilerin aralığıdır ve bir sütun içermelidir. Giriş aralığı X, analiz edilecek bağımsız verilerin aralığıdır. Giriş aralıklarının sayısı 16'yı geçmemelidir.
Çıkış aralığındaki prosedürün çıktısında aşağıdaki şekilde verilen raporu alıyoruz. tablo 8.3a-8.3v.
SONUÇLAR
Tablo 8.3a. Regresyon istatistikleri
Regresyon istatistikleri
Çoklu R
R Meydanı
Normalleştirilmiş R-kare
standart hata
Gözlemler
İlk olarak, burada sunulan hesaplamaların üst kısmını düşünün. tablo 8.3a, - regresyon istatistikleri.
Değer R Meydanı Kesinlik ölçüsü olarak da adlandırılan , ortaya çıkan regresyon çizgisinin kalitesini karakterize eder. Bu kalite, orijinal veriler ile regresyon modeli (hesaplanan veriler) arasındaki uyum derecesi ile ifade edilir. Kesinliğin ölçüsü her zaman aralığın içindedir.
Çoğu durumda değer R Meydanı aşırı denilen bu değerler arasındadır, yani. sıfır ile bir arasında.
Eğer değer R Meydanı birliğe yakın olması, oluşturulan modelin karşılık gelen değişkenlerin neredeyse tüm değişkenliğini açıkladığı anlamına gelir. Tam tersine, değer R Meydanı Sıfıra yakın olması, oluşturulan modelin kalitesiz olduğu anlamına gelir.
Örneğimizde kesinlik ölçüsü 0,99673'tür, bu da regresyon çizgisinin orijinal verilere çok iyi uyduğunu gösterir.
çoğul R - çoklu korelasyon katsayısı R - bağımsız değişkenlerin (X) ve bağımlı değişkenin (Y) bağımlılık derecesini ifade eder.
Çoklu R Belirleme katsayısının kareköküne eşit olan bu değer sıfır ile bir aralığında değerler alır.
Basit doğrusal regresyon analizinde çoğul R Pearson korelasyon katsayısına eşittir. Gerçekten mi, çoğul R bizim durumumuzda önceki örnekteki Pearson korelasyon katsayısına (0,998364) eşittir.
Tablo 8.3b. Regresyon katsayıları
Oranlar
standart hata
t-istatistiği
Y-kavşağı
Değişken X 1
* Hesaplamaların kısaltılmış bir versiyonu verilmiştir
Şimdi burada sunulan hesaplamaların orta kısmını düşünün. tablo 8.3b. Burada regresyon katsayısı b (2,305454545) ve y ekseni boyunca sapma verilmiştir; sabit a (2,694545455).
Hesaplamalara dayanarak regresyon denklemini aşağıdaki gibi yazabiliriz:
Y= x*2,305454545+2,694545455
Değişkenler arasındaki ilişkinin yönü, regresyon katsayılarının (b katsayısı) işaretlerine (negatif veya pozitif) göre belirlenir.
Regresyon katsayısının işareti pozitif ise bağımlı değişken ile bağımsız değişken arasındaki ilişki pozitif olacaktır. Bizim durumumuzda regresyon katsayısının işareti pozitif olduğundan ilişki de pozitiftir.
Regresyon katsayısının işareti negatif ise bağımlı değişken ile bağımsız değişken arasındaki ilişki negatiftir (ters).
İÇİNDE tablo 8.3c. çıktı sonuçları sunuldu kalanlar. Bu sonuçların raporda görünmesi için "Regresyon" aracını başlatırken "Artıklar" onay kutusunun etkinleştirilmesi gerekir.
KALAN ÇEKİLME
Tablo 8.3c. Kalıntılar
Gözlem
Tahmin edilen Y
Kalıntılar
Standart bakiyeler
Raporun bu bölümünü kullanarak her noktanın oluşturulan regresyon çizgisinden sapmalarını görebiliriz. En büyük mutlak değer kalan bizim durumumuzda - 0,778, en küçüğü - 0,043. Bu verilerin daha iyi yorumlanması için, orijinal verilerin grafiğini ve Şekil 1'de sunulan oluşturulmuş regresyon çizgisini kullanacağız. pirinç. 8.3. Gördüğünüz gibi regresyon çizgisi, orijinal verilerin değerlerine oldukça doğru bir şekilde "uyduruldu".
Söz konusu örneğin oldukça basit olduğu ve niteliksel olarak doğrusal bir regresyon çizgisi oluşturmanın her zaman mümkün olmadığı dikkate alınmalıdır.
Pirinç. 8.3.İlk veriler ve regresyon çizgisi
Bağımsız değişkenin bilinen değerlerine dayanarak bağımlı değişkenin gelecekteki bilinmeyen değerlerinin tahmin edilmesi sorunu dikkate alınmadı, yani. tahmin görevi.
Bir regresyon denklemine sahip olan tahmin problemi, Y= x*2.305454545+2.694545455 denkleminin bilinen x değerleriyle çözümüne indirgenir. Bağımlı değişken Y'nin altı adım ilerisini tahmin etmenin sonuçları sunulmaktadır tablo 8.4'te.
Tablo 8.4. Y değişkeni tahmin sonuçları
Y(tahmin)
Böylece, Microsoft Excel paketinde regresyon analizinin kullanılması sonucunda:
bir regresyon denklemi oluşturdu;
bağımlılık biçimini ve değişkenler arasındaki ilişkinin yönünü belirledi - fonksiyonun düzgün bir büyümesinde ifade edilen pozitif bir doğrusal regresyon;
değişkenler arasındaki ilişkinin yönünü kurmuş;
ortaya çıkan regresyon çizgisinin kalitesini değerlendirdi;
hesaplanan verilerin orijinal setin verilerinden sapmalarını görebildik;
bağımlı değişkenin gelecekteki değerlerini tahmin etti.
Eğer regresyon fonksiyonu tanımlanmış, yorumlanmış ve gerekçelendirilmişse ve regresyon analizinin doğruluğunun değerlendirilmesi gereksinimleri karşılıyorsa, oluşturulan modelin ve tahmin değerlerinin yeterince güvenilir olduğunu varsayabiliriz.
Bu şekilde elde edilen tahmin edilen değerler beklenebilecek ortalama değerlerdir.
Bu yazıda temel özellikleri inceledik. tanımlayıcı istatistikler ve bunların arasında şu gibi kavramlar var: ortalama değer,medyan,maksimum,minimum ve veri varyasyonunun diğer özellikleri.
Konsept hakkında da kısa bir tartışma yapıldı. emisyonlar. Dikkate alınan özellikler, keşifsel veri analizi olarak adlandırılan veri analizine atıfta bulunur; sonuçları genel nüfus için geçerli olmayabilir, yalnızca bir veri örneği için geçerli olabilir. Keşif amaçlı veri analizi, temel sonuçlara varmak ve popülasyon hakkında hipotezler oluşturmak için kullanılır.
Korelasyon ve regresyon analizinin temelleri, görevleri ve pratik kullanım olanakları da dikkate alındı.
Regresyon analizinin temel amacı Sonuçta ortaya çıkan nitelikteki değişikliğin bir veya daha fazla faktör işaretinin etkisinden kaynaklandığı ve sonuç niteliğini de etkileyen diğer tüm faktörler kümesinin sabit ve ortalama değerler olarak alındığı ilişkinin analitik formunun belirlenmesinden oluşur. .
Regresyon analizinin görevleri:
a) Bağımlılık biçiminin oluşturulması. Olgular arasındaki ilişkinin doğası ve biçimine ilişkin olarak, pozitif doğrusal ve doğrusal olmayan ve negatif doğrusal ve doğrusal olmayan regresyon vardır.
b) Regresyon fonksiyonunun şu veya bu türden bir matematiksel denklem biçiminde tanımlanması ve açıklayıcı değişkenlerin bağımlı değişken üzerindeki etkisinin belirlenmesi.
c) Bağımlı değişkenin bilinmeyen değerlerinin tahmini. Regresyon fonksiyonunu kullanarak, açıklayıcı değişkenlerin verilen değerleri aralığında bağımlı değişkenin değerlerini yeniden üretebilir (yani enterpolasyon problemini çözebilir) veya sürecin gidişatını belirtilen aralığın dışında değerlendirebilirsiniz (yani, ekstrapolasyon problemini çözün). Sonuç, bağımlı değişkenin değerinin bir tahminidir.Çift regresyon - iki değişken y ve x arasındaki ilişkinin denklemi: , burada y bağımlı değişkendir (etkili işaret); x - bağımsız, açıklayıcı değişken (özellik faktörü).
Doğrusal ve doğrusal olmayan regresyonlar vardır.
Tahmin edilen parametreler açısından doğrusal olmayan regresyonlar: Bir regresyon denklemi oluşturmak, parametrelerinin tahmin edilmesine indirgenir. Parametrelerde doğrusal olan regresyon parametrelerini tahmin etmek için en küçük kareler yöntemi (LSM) kullanılır. LSM, elde edilen özelliğin gerçek değerlerinin kare sapmalarının toplamının teorik olanlardan minimum olduğu parametre tahminlerinin elde edilmesini mümkün kılar;
Doğrusal regresyon: y = a + bx + ε
Doğrusal olmayan regresyonlar iki sınıfa ayrılır: analize dahil edilen açıklayıcı değişkenlere göre doğrusal olmayan, ancak tahmin edilen parametrelere göre doğrusal olan regresyonlar ve tahmin edilen parametrelere göre doğrusal olmayan regresyonlar.
Açıklayıcı değişkenlerde doğrusal olmayan regresyonlar: .
.
Doğrusala indirgenebilen doğrusal ve doğrusal olmayan denklemler için a ve b için aşağıdaki sistem çözülür:
Bu sistemden takip edilen hazır formülleri kullanabilirsiniz:
İncelenen olaylar arasındaki bağlantının yakınlığı, doğrusal regresyon için çift korelasyonun doğrusal katsayısı ile tahmin edilir:
ve korelasyon indeksi - doğrusal olmayan regresyon için:
Oluşturulan modelin kalitesinin bir değerlendirmesi, ortalama yaklaşım hatasının yanı sıra belirleme katsayısı (endeksi) ile verilecektir.
Ortalama yaklaşım hatası, hesaplanan değerlerin gerçek değerlerden ortalama sapmasıdır: .
.
İzin verilen değer sınırı -% 8-10'dan fazla değil.
Ortalama esneklik katsayısı, x faktörünün ortalama değerinden %1 oranında değiştiğinde y sonucunun ortalama değerinden ortalama yüzde kaç değişeceğini gösterir:
.Varyans analizinin görevi bağımlı değişkenin varyansını analiz etmektir:
,
sapmaların karelerinin toplamı nerede;
- regresyondan kaynaklanan sapmaların karelerinin toplamı (“açıklanan” veya “faktöriyel”);
- sapmaların karelerinin kalan toplamı.
Etkin özellik y'nin toplam varyansında regresyonla açıklanan varyansın payı, R2 belirleme katsayısı (indeksi) ile karakterize edilir:
Belirleme katsayısı, katsayı veya korelasyon indeksinin karesidir.F testi - regresyon denkleminin kalitesinin değerlendirilmesi - hipotezin test edilmesinden oluşur. Ancak regresyon denkleminin istatistiksel önemsizliği ve bağlantının yakınlığının göstergesi hakkında. Bunun için gerçek F gerçeği ile Fisher F kriterinin değerlerinin kritik (tablo) F tablosunun karşılaştırması yapılır. F gerçeği, bir serbestlik derecesi için hesaplanan faktöriyel ve artık varyansların değerlerinin oranından belirlenir:
 ,
,
burada n, nüfus birimlerinin sayısıdır; m, x değişkenleri için parametre sayısıdır.
F tablosu, belirli bir serbestlik derecesi ve anlamlılık düzeyi a için, rastgele faktörlerin etkisi altında kriterin mümkün olan maksimum değeridir. Önem düzeyi a - doğru olması koşuluyla doğru hipotezi reddetme olasılığı. Genellikle a, 0,05 veya 0,01'e eşit olarak alınır.
Eğer F tablosu< F факт, то Н о - гипотеза о случайной природе оцениваемых характеристик отклоняется и признается их статистическая значимость и надежность. Если F табл >F bir gerçekse, H ile ilgili hipotez reddedilmez ve regresyon denkleminin istatistiksel anlamsızlığı, güvenilmezliği kabul edilir.
Regresyon ve korelasyon katsayılarının istatistiksel anlamlılığını değerlendirmek için her bir gösterge için Öğrenci t testi ve güven aralıkları hesaplanır. Göstergelerin rastgele doğası hakkında bir H hipotezi ileri sürülmektedir; sıfırdan önemsiz farkları hakkında. Regresyon ve korelasyon katsayılarının öneminin Öğrenci t-testi kullanılarak değerlendirilmesi, değerlerinin rastgele hatanın büyüklüğü ile karşılaştırılmasıyla gerçekleştirilir:
; ; .
Doğrusal regresyon parametrelerinin ve korelasyon katsayısının rastgele hataları aşağıdaki formüllerle belirlenir:
T-istatistiklerinin gerçek ve kritik (tablo) değerlerini - t tablo ve t olgusunu - karşılaştırarak H o hipotezini kabul ediyoruz veya reddediyoruz.
Fisher'in F testi ile Öğrenci t-istatistikleri arasındaki ilişki eşitlikle ifade edilir
Eğer t tablosu< t факт то H o отклоняется, т.е. a, b и не случайно отличаются от нуля и сформировались под влиянием систематически действующего фактора х. Если t табл >H hakkındaki hipotezin reddedilmemesi ve a, b veya oluşumunun rastgele doğasının tanınması.
Güven aralığını hesaplamak amacıyla her gösterge için marjinal hata D'yi belirleriz:
, .
Güven aralıklarının hesaplanmasına ilişkin formüller aşağıdaki gibidir:
; ;
; ;
Sıfır güven aralığının sınırları dahilindeyse; Alt limit negatif, üst limit pozitif ise tahmin edilen parametrenin sıfır olduğu varsayılır çünkü aynı anda hem pozitif hem de negatif değerler alamaz.
Tahmin değeri, karşılık gelen (tahmin) değerin regresyon denkleminde değiştirilmesiyle belirlenir. Tahminin ortalama standart hatası hesaplanır: ,
,
Nerede
ve tahminin güven aralığı oluşturulur: ;
;  ;
; 
Nerede .
.Çözüm Örneği
Görev numarası 1. Ural bölgesinin yedi bölgesi için 199X için iki işaretin değeri bilinmektedir.
Tablo 1.
Gerekli: 1. Y'nin x'e bağımlılığını karakterize etmek için aşağıdaki fonksiyonların parametrelerini hesaplayın:
a) doğrusal;
b) kuvvet yasası (önceden değişkenlerin doğrusallaştırılması prosedürünü her iki parçanın logaritmasını alarak gerçekleştirmek gerekiyordu);
c) gösterici;
d) eşkenar hiperbol (bu modelin önceden nasıl doğrusallaştırılacağını da bulmanız gerekir).
2. Ortalama yaklaşım hatasını ve Fisher'in F-testini kullanarak her modeli değerlendirin.Çözüm (Seçenek #1)
Doğrusal regresyonun a ve b parametrelerini hesaplamak için (hesaplama bir hesap makinesi kullanılarak yapılabilir).
Normal denklem sistemini aşağıdakilere göre çöz: A Ve B:
İlk verilere dayanarak hesaplıyoruz :
:
sen X yx x2 y2 Ai ben 68,8 45,1 3102,88 2034,01 4733,44 61,3 7,5 10,9 2 61,2 59,0 3610,80 3481,00 3745,44 56,5 4,7 7,7 3 59,9 57,2 3426,28 3271,84 3588,01 57,1 2,8 4,7 4 56,7 61,8 3504,06 3819,24 3214,89 55,5 1,2 2,1 5 55,0 58,8 3234,00 3457,44 3025,00 56,5 -1,5 2,7 6 54,3 47,2 2562,96 2227,84 2948,49 60,5 -6,2 11,4 7 49,3 55,2 2721,36 3047,04 2430,49 57,8 -8,5 17,2 Toplam 405,2 384,3 22162,34 21338,41 23685,76 405,2 0,0 56,7 evlenmek değer (Toplam/n) 57,89 54,90 3166,05 3048,34 3383,68 X X 8,1 S 5,74 5,86 X X X X X X s2 32,92 34,34 X X X X X X 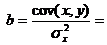

Regresyon denklemi: y= 76,88 - 0,35X. Ortalama günlük ücrette 1 ruble artışla. gıda ürünleri satın alma harcamalarının payı ortalama %0,35 puan azaldı.
Çift korelasyonunun doğrusal katsayısını hesaplayın:
İletişim ılımlı, ters.
Belirleme katsayısını tanımlayalım:
Sonuçtaki %12,7'lik değişiklik x faktöründeki değişiklikle açıklanmaktadır. Gerçek değerleri regresyon denkleminde değiştirmek X, teorik (hesaplanan) değerleri belirlemek . Ortalama yaklaşım hatasının değerini bulun:
Hesaplanan değerler ortalama olarak gerçek değerlerden %8,1 oranında sapmaktadır.
F kriterini hesaplayalım:
çünkü 1< F < ¥ , değerlendirilebilir F -1 .
Ortaya çıkan değer hipotezin kabul edilmesi gerektiğini gösterir Ama ah ortaya çıkan bağımlılığın rastgele doğası ve denklem parametrelerinin istatistiksel anlamsızlığı ve bağlantının sıkılığının göstergesi.
1b. Bir güç modelinin oluşturulmasından önce değişkenlerin doğrusallaştırılması prosedürü gelir. Örnekte doğrusallaştırma, denklemin her iki tarafının logaritması alınarak yapılır:
NeredeY=lg(y), X=lg(x), C=lg(a).Hesaplamalar için Tablodaki verileri kullanıyoruz. 1.3.
Tablo 1.3
e X YX Y2 x2 Ai 1 1,8376 1,6542 3,0398 3,3768 2,7364 61,0 7,8 60,8 11,3 2 1,7868 1,7709 3,1642 3,1927 3,1361 56,3 4,9 24,0 8,0 3 1,7774 1,7574 3,1236 3,1592 3,0885 56,8 3,1 9,6 5,2 4 1,7536 1,7910 3,1407 3,0751 3,2077 55,5 1,2 1,4 2,1 5 1,7404 1,7694 3,0795 3,0290 3,1308 56,3 -1,3 1,7 2,4 6 1,7348 1,6739 2,9039 3,0095 2,8019 60,2 -5,9 34,8 10,9 7 1,6928 1,7419 2,9487 2,8656 3,0342 57,4 -8,1 65,6 16,4 Toplam 12,3234 12,1587 21,4003 21,7078 21,1355 403,5 1,7 197,9 56,3 Ortalama değer 1,7605 1,7370 3,0572 3,1011 3,0194 X X 28,27 8,0 σ 0,0425 0,0484 X X X X X X X σ2 0,0018 0,0023 X X X X X X X C ve b'yi hesaplayın:
Doğrusal bir denklem elde ederiz: .
.
Bunu güçlendirerek şunu elde ederiz:
Bu denklemde gerçek değerleri değiştirerek X, sonucun teorik değerlerini alıyoruz. Bunlara dayanarak göstergeleri hesaplıyoruz: bağlantının sıkılığı - korelasyon endeksi ve ortalama yaklaşım hatası
Güç modelinin özellikleri, ilişkiyi doğrusal fonksiyondan biraz daha iyi tanımladığını göstermektedir.1v. Üstel bir eğri denkleminin oluşturulması
Denklemin her iki kısmının logaritması alınırken değişkenlerin doğrusallaştırılmasına yönelik bir prosedür uygulanır:

Hesaplamalar için tablo verilerini kullanırız.e X Yx Y2 x2 Ai 1 1,8376 45,1 82,8758 3,3768 2034,01 60,7 8,1 65,61 11,8 2 1,7868 59,0 105,4212 3,1927 3481,00 56,4 4,8 23,04 7,8 3 1,7774 57,2 101,6673 3,1592 3271,84 56,9 3,0 9,00 5,0 4 1,7536 61,8 108,3725 3,0751 3819,24 55,5 1,2 1,44 2,1 5 1,7404 58,8 102,3355 3,0290 3457,44 56,4 -1,4 1,96 2,5 6 1,7348 47,2 81,8826 3,0095 2227,84 60,0 -5,7 32,49 10,5 7 1,6928 55,2 93,4426 2,8656 3047,04 57,5 -8,2 67,24 16,6 Toplam 12,3234 384,3 675,9974 21,7078 21338,41 403,4 -1,8 200,78 56,3 evlenmek zn. 1,7605 54,9 96,5711 3,1011 3048,34 X X 28,68 8,0 σ 0,0425 5,86 X X X X X X X σ2 0,0018 34,339 X X X X X X X Regresyon parametreleri A'nın değerleri ve İÇİNDE tutarında:
Doğrusal bir denklem elde edilir: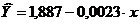 .
Ortaya çıkan denklemi güçlendiriyoruz ve normal biçimde yazıyoruz:
.
Ortaya çıkan denklemi güçlendiriyoruz ve normal biçimde yazıyoruz:
Bağlantının yakınlığını korelasyon endeksi aracılığıyla tahmin ediyoruz: