SQL dili. Veritabanına sorguların oluşturulması. SQL toplama işlevleri. SQL sorgulama dili
Ders, AS hizmet sözcüğünü kullanarak bir sütunu (alanları) yeniden adlandırma sql konusunu kapsayacaktır; sql'deki toplama fonksiyonları konusu da ele alınmaktadır. Spesifik talep örnekleri analiz edilecektir.
Sorgulardaki sütun adları yeniden adlandırılabilir. Bu, sonuçları daha okunaklı hale getirir.
SQL'de, alanların yeniden adlandırılması, AS anahtar kelimesi sonuç kümelerindeki alan adlarını yeniden adlandırmak için kullanılır
Sözdizimi:
SEÇME<имя поля>GİBİ<псевдоним>İTİBAREN …
SQL'de yeniden adlandırmanın bir örneğini ele alalım:
"Enstitü" veritabanına bir örnek:Öğretmenlerin adlarını ve maaşlarını görüntüleyin, maaşı 15000'in altında olan öğretmenler için zarplata alanını olarak yeniden adlandırın. "Düşük ücret"
✍ Çözüm:
SQL'de sütunları yeniden adlandırmak genellikle gereklidir birden çok alanla ilişkili değerleri hesaplarken tablolar. Bir örnek düşünün:
"Enstitü" veritabanına bir örnek:Öğretmenler tablosundan ad alanını görüntüleyin ve alana ad vererek maaş ve ikramiye toplamını hesaplayın "maaş_ikramiyesi"
✍ Çözüm:
| 1 2 | Öğretmenlerden zarplata_premia OLARAK adı, (zarplata+ premia) SEÇİN; |
Öğretmenlerden zarplata_premia olarak adı, (zarplata+premia) SEÇİN;
Sonuç:
SQL'de toplu işlevler
Sql'deki toplama işlevleri, toplam değerleri almak ve ifadeleri değerlendirmek için kullanılır:
Tüm toplama işlevleri tek bir değer döndürür.
COUNT , MIN ve MAX işlevleri tüm veri türleri için geçerlidir.
TOPLA ve AVG işlevleri yalnızca sayısal alanlar için kullanılır.
COUNT(*) ve COUNT() işlevleri arasında bir fark vardır: ikincisi hesaplama yaparken NULL değerleri dikkate almaz.
Önemli: SQL'de toplama işlevleriyle çalışırken bir işlev sözcüğü kullanılır GİBİ
"Enstitü" veritabanına bir örnek:Öğretmenler arasında en yüksek maaşın değerini alın, toplamı şu şekilde görüntüleyin: "max_zp"
✍ Çözüm:
| Öğretmenlerden MAX (zarplata) max_zp OLARAK SEÇİN; |
Öğretmenlerden max_sal olarak MAX(zarplata) SEÇİN;
Sonuçlar:
Daha fazlasını düşünün karmaşık örnek sql'de toplama işlevlerini kullanma.
✍ Çözüm:
SQL'de GROUP BY deyimi
Sql'deki group by deyimi genellikle toplama işlevleriyle birlikte kullanılır.
Toplama işlevleri, ortaya çıkan tüm sorgu dizelerinde yürütülür. Sorgu bir GROUP BY deyimi içeriyorsa, GROUP BY deyiminde belirtilen her satır grubu bir grup oluşturur ve toplama işlevleri yürütülür her grup için ayrı ayrı.
Ders tablosu ile bir örnek düşünün: 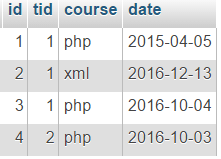
Örnek:
Önemli: Böylece, GROUP BY kullanımının bir sonucu olarak, sorgunun tüm çıktı satırları, bu sütunlarda aynı değer kombinasyonları ile karakterize edilen gruplara bölünür (yani, toplama işlevleri her grup için ayrı ayrı gerçekleştirilir).
Aynı zamanda, NULL değerleri içeren bir alana göre gruplandırırken, bu tür tüm kayıtların tek bir gruba gireceği dikkate alınmalıdır.
Çeşitli yazıcı türleri için ortalama maliyet ve miktarlarını belirleyin (yani lazer, mürekkep püskürtmeli ve matris için ayrı ayrı). Toplama işlevlerini kullanın. Sonuç şöyle görünmelidir:

SQL deyimine sahip olmak
Değerleri kontrol etmek için SQL'deki HAVING yan tümcesi gereklidir, gruplandırmadan sonra toplama işlevi kullanılarak elde edilen(GROUP BY kullandıktan sonra). böyle bir çek WHERE deyiminde yer alamaz.
Örnek: DB Bilgisayar Mağazası. Aynı işlemci hızına sahip bilgisayarların ortalama fiyatını hesaplayın. Hesaplamayı yalnızca ortalama fiyatı 30.000'den az olan gruplar için çalıştırın.
GRUPLANDIRMA teklifine göre(SELECT deyimi), verileri (satırları) bir sütunun veya birden çok sütunun veya ifadenin değerine göre gruplandırmanıza olanak tanır. Sonuç, bir dizi özet satırı olacaktır.
Toplama işlevlerinin işlenenleri olan sabitler ve sütunlar dışında, seçim listesindeki her sütunun GROUP BY yan tümcesinde bulunması gerekir.
Bir tablo, sütunlarının herhangi bir kombinasyonuna göre gruplandırılabilir.
Toplu işlevler bir grup satırdan tek bir özet değer elde etmek için kullanılır. Tüm toplama işlevleri, sütun veya ifade olabilen tek bir bağımsız değişken üzerinde hesaplamalar gerçekleştirir. Herhangi bir toplama işlevinin sonucu, ayrı bir sonuç sütununda görüntülenen sabit bir değerdir.
Toplama işlevleri, GROUP BY deyimi de içerebilen SELECT deyiminin sütun listesinde belirtilir. SELECT deyiminde GROUP BY yan tümcesi yoksa ve seçme sütun listesi en az bir toplama işlevi içeriyorsa, basit sütunlar içermemelidir. Öte yandan, bir sütun seçme listesi, bu sütunlar GROUP BY deyiminin bağımsız değişkenleriyse, toplama işlevinin bağımsız değişkeni olmayan sütun adları içerebilir.
Sorgu bir WHERE yan tümcesi içeriyorsa, toplama işlevleri seçimin sonuçları için bir değer hesaplar.
Toplama işlevleri MIN ve MAX Sırasıyla sütunun en küçük ve en büyük değerini hesaplayın. Bağımsız değişkenler sayılar, dizeler ve tarihler olabilir. Hesaplamadan önce tüm NULL değerleri kaldırılır (yani dikkate alınmazlar).
Toplama işlevi SUM hesaplar toplam tutar sütun değerleri. Bağımsız değişkenler yalnızca sayı olabilir. DISTINCT seçeneğini kullanmak, TOPLA işlevini uygulamadan önce sütundaki tüm yinelenen değerleri ortadan kaldırır. Benzer şekilde, bu toplama işlevi uygulanmadan önce tüm NULL değerleri kaldırılır.
AVG Toplama İşlevi bir sütundaki tüm değerlerin ortalamasını döndürür. Bağımsız değişkenler de yalnızca sayı olabilir ve değerlendirmeden önce tüm NULL değerleri kaldırılır.
Toplam işlev COUNT iki farklı formu vardır:
- COUNT( sütun_adı) - sütun_adı sütunundaki değerlerin sayısını sayar, NULL değerler dikkate alınmaz
- COUNT(*) - tablodaki satır sayısını sayar, NULL değerleri de dikkate alınır
Sorgu, uygulamadan önce DISTINCT anahtar sözcüğünü kullanıyorsa COUNT işlev tüm yinelenen sütun değerleri kaldırılır.
COUNT_BIG işlevi COUNT işlevine benzer. Aralarındaki tek fark, döndürdükleri sonucun türüdür: COUNT_BIG işlevi her zaman BIGINT değerleri döndürürken, COUNT işlevi INTEGER veri değerleri döndürür.
İÇİNDE SAHİP TEKLİF bir satır grubu için geçerli olan bir koşulu tanımlar. Satır grupları için karşılık gelen tablonun içeriği için WHERE yan tümcesiyle aynı anlama sahiptir (Gruplamadan önce WHERE, sonra HAVING geçerlidir).
Aşağıdaki alt bölümlerde, sorgularda kullanılabilen diğer SELECT deyimi yan tümceleri, ayrıca toplama işlevleri ve deyim kümeleri açıklanmaktadır. Bir hatırlatma olarak, şu ana kadar WHERE yan tümcesinin kullanımını ele aldık ve bu makalede GROUP BY, ORDER BY ve HAVING yan tümcelerine bakacağız ve bu yan tümcelerin agrega ile birlikte kullanımına ilişkin bazı örnekler vereceğiz. Transact-SQL'de desteklenen işlevler.
GRUPLANDIRMA teklifine göre
Teklif GRUPLANDIRMAYA GÖRE bir veya daha fazla sütunun veya ifadenin değerlerine dayalı olarak bir dizi özet satır oluşturmak için seçilen satır kümesini gruplandırır. GROUP BY deyiminin basit bir kullanımı aşağıdaki örnekte gösterilmiştir:
SampleDb'yi KULLANIN; Works_On GRUPTAN İşe GÖRE İş SEÇİN;
Bu örnekte çalışan pozisyonları seçilip gruplandırılmıştır.
Yukarıdaki örnekte, GROUP BY deyimi, İş sütununun tüm olası değerleri (NULL dahil) için ayrı bir grup oluşturur.
GROUP BY yan tümcesindeki sütunların kullanımı belirli koşulları karşılamalıdır. Özellikle, sorgunun seçim listesindeki her sütunun GROUP BY yan tümcesinde de yer alması gerekir. Bu gereksinim, bir toplama işlevinin parçası olan sabitler ve sütunlar için geçerli değildir. (Toplu işlevler bir sonraki alt bölümde ele alınmıştır.) Bu mantıklı çünkü yalnızca GROUP BY yan tümcesindeki sütunlar, grup başına bir değer garanti eder.
Bir tablo, sütunlarının herhangi bir kombinasyonuna göre gruplandırılabilir. Aşağıdaki örnek, Works_on tablosunun satırlarının iki sütun halinde gruplandırılmasını gösterir:
SampleDb'yi KULLANIN; Works_On GRUPTAN ProjeNumarasına Göre ProjeNumarası, İş SEÇİN, İş;
Bu sorgunun sonucu:

Sorgunun sonuçlarına göre, farklı proje numarası ve pozisyon kombinasyonlarına sahip dokuz grup olduğunu görebilirsiniz. GROUP BY yan tümcesindeki sütun adlarının sırasının, SELECT sütun listesindekiyle aynı olması gerekmez.
Toplu işlevler
Toplam değerler elde etmek için toplama işlevleri kullanılır. Tüm toplama işlevleri aşağıdaki kategorilere ayrılabilir:
sıradan toplama fonksiyonları;
istatistiksel toplama fonksiyonları;
kullanıcı tarafından tanımlanan toplam işlevler;
analitik toplama fonksiyonları.
Burada ilk üç tür toplama işlevine bakacağız.
Sıradan Toplama Fonksiyonları
Transact-SQL dili, aşağıdaki altı toplama işlevini destekler: DAK, MAKS., TOPLAM, ortalama, SAYMAK, COUNT_BIG.
Tüm toplama işlevleri, sütun veya ifade olabilen tek bir bağımsız değişken üzerinde hesaplamalar gerçekleştirir. (Tek istisna, sırasıyla COUNT(*) ve COUNT_BIG(*) olmak üzere iki işlevin COUNT ve COUNT_BIG'in ikinci biçimidir.) Herhangi bir toplama işlevinin sonucu, ayrı bir sonuç sütununda görüntülenen sabit bir değerdir.
Toplama işlevleri, bir GROUP BY deyimi de içerebilen SELECT deyiminin sütun listesinde belirtilir. SELECT deyiminde GROUP BY yan tümcesi yoksa ve sütun seçme listesi en az bir toplama işlevi içeriyorsa, basit sütunlar içermemelidir (toplama işlevine argüman görevi gören sütunlar dışında). Bu nedenle, aşağıdaki örnekteki kod yanlıştır:
SampleDb'yi KULLANIN; Çalışandan Soyadı, MIN(Id) SEÇİN;
Burada, Çalışan tablosunun Soyadı sütunu, bir toplama işlevi bağımsız değişkeni olmadığı için sütun seçim listesinde olmamalıdır. Öte yandan, bir sütun seçme listesi, bu sütunlar GROUP BY deyiminin bağımsız değişkenleriyse, toplama işlevinin bağımsız değişkeni olmayan sütun adları içerebilir.
Bir toplama işlevi argümanından önce iki olası anahtar kelimeden biri gelebilir:
TÜMSütundaki tüm değerler üzerinde hesaplamaların yapıldığını belirtir. Bu varsayılan değerdir.
BELİRGİNHesaplamalar için yalnızca benzersiz sütun değerlerinin kullanıldığını belirtir.
Toplama işlevleri MIN ve MAX
MIN ve MAX toplama işlevleri sırasıyla bir sütunun en küçük ve en büyük değerini hesaplar. Sorgu bir WHERE yan tümcesi içeriyorsa, MIN ve MAX işlevleri, belirtilen ölçütleri karşılayan satırların en küçük ve en büyük değerini döndürür. Aşağıdaki örnek, MIN toplama işlevinin kullanımını göstermektedir:
SampleDb'yi KULLANIN; -- Çalışandan 2581 SELECT MIN(Id) "Min Id" OLARAK döndürür;
Yukarıdaki örnekte döndürülen sonuç pek bilgilendirici değildir. Örneğin bu numaranın sahibi olan çalışanın adı bilinmiyor. Ama bu soyadını al her zamanki gibi mümkün değildir, çünkü daha önce de belirtildiği gibi, Soyadı sütununun açıkça belirtilmesine izin verilmez. Bir çalışanın en düşük personel sayısı ile birlikte bu çalışanın soyadını almak için bir alt sorgu kullanılır. Aşağıdaki örnek, alt sorgunun önceki örnekteki SELECT deyimini içerdiği böyle bir alt sorgunun kullanımını gösterir:
Sorgu yürütme sonucu:

MAX toplama işlevinin kullanımı aşağıdaki örnekte gösterilmiştir:
MİN ve MAKS işlevleri ayrıca dizeleri ve tarihleri bağımsız değişken olarak alabilir. Bir dize bağımsız değişkeni durumunda, değerler gerçek sıralama düzeni kullanılarak karşılaştırılır. "date" türündeki tüm geçici veri bağımsız değişkenleri için en küçük sütun değeri en erken tarih ve en büyüğü - en yenisi.
DISTINCT anahtar sözcüğünü MIN ve MAX işlevleriyle kullanabilirsiniz. MIN ve MAX toplama işlevleri kullanılmadan önce, tüm NULL değerleri bağımsız değişken sütunlarından çıkarılır.
Toplama işlevi SUM
agrega TOPLA işlevi sütun değerlerinin toplamını hesaplar. Bu toplama işlevinin bağımsız değişkeni her zaman sahip olmalıdır sayısal tip veri. SUM toplama işlevinin kullanımı aşağıdaki örnekte gösterilmiştir:
SampleDb'yi KULLANIN; Projeden TOPLAM (Bütçe) "Özet bütçe" SEÇİN;
Bu örnek, tüm projelerin bütçelerinin toplamını hesaplar. Sorgu yürütme sonucu:

Bu örnekte, toplama işlevi tüm proje bütçe değerlerini gruplandırır ve bunların toplam tutarını belirler. Bu nedenle, sorgu örtük bir gruplama işlevi içerir (tüm benzer sorgular gibi). Yukarıdaki örnekteki örtülü gruplama işlevi, aşağıdaki örnekte gösterildiği gibi açıkça belirtilebilir:
SampleDb'yi KULLANIN; Proje Grubundan (BY()) TOPLAM (Bütçe) "Toplam Bütçe" SEÇİN;
DISTINCT seçeneğini kullanmak, TOPLA işlevini uygulamadan önce sütundaki tüm yinelenen değerleri ortadan kaldırır. Benzer şekilde, bu toplama işlevi uygulanmadan önce tüm NULL değerleri kaldırılır.
AVG Toplama İşlevi
agrega ortalama işlev bir sütundaki tüm değerlerin aritmetik ortalamasını döndürür. Bu toplama işlevinin bağımsız değişkeni her zaman sayısal bir veri türünde olmalıdır. AVG işlevi kullanılmadan önce, bağımsız değişkeninden tüm NULL değerleri kaldırılır.
AVG toplama işlevinin kullanımı aşağıdaki örnekte gösterilmiştir:
SampleDb'yi KULLANIN; -- 133833 döndürür SELECT AVG (Bütçe) Projeden "Proje başına ortalama bütçe";
Burada tüm bütçeler için bütçenin aritmetik ortalaması hesaplanır.
COUNT ve COUNT_BIG İşlevlerini Toplama
agrega SAY işlevi iki farklı formu vardır:
COUNT( sütun_adı) COUNT(*)
İşlevin ilk biçimi sütun_adı sütunundaki değerlerin sayısını sayar. DISTINCT anahtar sözcüğü bir sorguda kullanılıyorsa, COUNT işlevi uygulanmadan önce yinelenen sütun değerleri kaldırılır. COUNT işlevinin bu biçimi, bir sütundaki değerlerin sayısını sayarken NULL değerleri dikkate almaz.
COUNT toplama işlevinin ilk biçiminin kullanımı aşağıdaki örnekte gösterilmiştir:
SampleDb'yi KULLANIN; ProjeNumarasına Göre Works_on GRUBU'NDAN ProjeNumarası SEÇİN, COUNT(DISTINCT Job) "Projedeki işler";
Burası, her proje için farklı pozisyonların sayıldığı yerdir. Bu sorgunun sonucu:

Örnek sorgudan da görebileceğiniz gibi, COUNT işlevi tarafından NULL değerleri dikkate alınmamıştır. (İş sütunundaki tüm değerlerin toplamı olması gerektiği gibi 11 değil 7 çıktı.)
COUNT işlevinin ikinci biçimi, yani. COUNT(*) işlevi, bir tablodaki satır sayısını sayar. COUNT(*) işlevine sahip bir sorgunun SELECT deyimi, koşullu bir WHERE yan tümcesi içeriyorsa, işlev, belirtilen koşulu karşılayan satır sayısını döndürür. COUNT fonksiyonunun ilk formundan farklı olarak ikinci formunda NULL değerleri yok saymaz çünkü bu fonksiyon sütunlar üzerinde değil satırlar üzerinde çalışır. Aşağıdaki örnek, COUNT(*) işlevinin kullanımını göstermektedir:
SampleDb'yi KULLANIN; Works_on GROUP BY Job'DAN "İş türü", COUNT(*) "İşçiye ihtiyaç var" OLARAK İş SEÇİN;
Burada tüm projelerdeki pozisyon sayısı sayılır. Sorgu yürütme sonucu:

COUNT_BIG işlevi COUNT işlevine benzer. Aralarındaki tek fark, döndürdükleri sonucun türüdür: COUNT_BIG işlevi her zaman BIGINT değerleri döndürürken, COUNT işlevi INTEGER veri değerleri döndürür.
İstatistiksel toplama işlevleri
Aşağıdaki işlevler, istatistiksel toplama işlevleri grubunu oluşturur:
VARBir sütunda veya ifadede temsil edilen tüm değerlerin istatistiksel varyansını hesaplar.
VARPBir sütunda veya ifadede temsil edilen tüm değerlerin popülasyonunun istatistiksel varyansını hesaplar.
STDEVBir sütundaki veya ifadedeki tüm değerlerin standart sapmasını (karşılık gelen varyansın karekökü olarak hesaplanır) hesaplar.
STDEVPBir sütun veya ifadedeki tüm değerlerin toplamının standart sapmasını hesaplar.
Kullanıcı Tanımlı Toplama İşlevleri
Veritabanı Motoru, kullanıcı tanımlı işlevlerin uygulanmasını da destekler. Bu yetenek, kullanıcıların sistem toplama işlevlerini kendilerinin uygulayabilecekleri ve yükleyebilecekleri işlevlerle artırmalarına olanak tanır. Bu işlevler, kullanıcı tanımlı işlevlerin özel bir sınıfını temsil eder ve daha sonra daha ayrıntılı olarak ele alınacaktır.
SAHİP TEKLİF
Bir cümlede SAHİP OLMAK bir satır grubu için geçerli olan bir koşulu tanımlar. Dolayısıyla, bu yan tümce, satır grupları için, karşılık gelen tablonun içeriği için WHERE yan tümcesiyle aynı anlama sahiptir. Sözdizimi tekliflere sahip olmak Sonraki:
SAHİP DURUM
Burada, koşul parametresi bir koşulu temsil eder ve toplam işlevleri veya sabitleri içerir.
HAVING yan tümcesinin COUNT(*) toplama işleviyle kullanımı aşağıdaki örnekte gösterilmiştir:
SampleDb'yi KULLANIN; -- "p3" döndürür. Works_on GRUPTAN ProjeNumarasını ProjeNumarasına Göre SEÇİN SAYI(*) VAR
Bu örnekte, GROUP BY deyimi kullanılarak, sistem tüm satırları ProjeNumarası sütunundaki değerlere göre gruplandırır. Daha sonra her gruptaki satır sayısı sayılır ve dörtten az (üç veya daha az) satır içeren gruplar seçilir.
HAVING yan tümcesi, aşağıdaki örnekte gösterildiği gibi toplama işlevleri olmadan da kullanılabilir:
SampleDb'yi KULLANIN; -- "Danışman" döndürür. "%K" GİBİ İş SAHİBİ OLARAK GRUBA GÖRE Works_on'dan İş SEÇİN;
Bu örnek, Works_on tablosundaki satırları konuma göre gruplandırır ve "K" harfiyle başlamayan konumları eler.
HAVING yan tümcesi, GROUP BY yan tümcesi olmadan da kullanılabilir, ancak bu yaygın bir uygulama değildir. Bu durumda, tüm tablo satırları aynı grupta döndürülür.
teklife göre SİPARİŞ
Teklif TARAFINDAN SİPARİŞ sorgu tarafından döndürülen sonuç kümesindeki satırların sıralama düzenini tanımlar. Bu cümle aşağıdaki sözdizimine sahiptir:
Sıralama düzeni col_name parametresinde belirtilir. col_number parametresi, sütunları SELECT deyiminin seçim listesinde göründükleri sırayla tanımlayan alternatif bir sıralama düzeni belirticidir (1, birinci sütun, 2, ikinci sütun vb.). ASC parametresi sıralamayı artan düzende tanımlar ve DESC parametresi- Azalan. Varsayılan ASC'dir.
ORDER BY yan tümcesindeki sütun adlarının sütun seçme listesinde olması gerekmez. Ancak bu, SELECT DISTINCT sorguları için geçerli değildir, çünkü bu tür sorgularda ORDER BY yan tümcesinde belirtilen sütun adlarının da sütun seçme listesinde belirtilmesi gerekir. Ayrıca bu yan tümce, FROM yan tümcesinde listelenmeyen tablolardan sütun adları içeremez.
ORDER BY yan tümcesinin sözdiziminden de görebileceğiniz gibi, sonuç kümesi birden çok sütunda sıralanabilir. Bu sıralama aşağıdaki örnekte gösterilmiştir:
Bu örnek, personel sayısı 20.000'den az olan çalışanlar için departman numaralarını ve çalışan soyadlarını ve adlarını seçer ve soyadı ve adına göre sıralar. Bu sorgunun sonucu:

ORDER BY yan tümcesindeki sütunlar, adlarına göre değil, seçim listesindeki sıraya göre belirtilebilir. Buna göre yukarıdaki örnekteki cümle şu şekilde yeniden yazılabilir:
Çok alternatif yol sıralama ölçütü bir toplama işlevi içeriyorsa, adlar yerine sütunların konumlarına göre belirtilmesi kullanılır. (Başka bir yol da, daha sonra ORDER BY deyiminde görünen sütun adlarını kullanmaktır.) Ancak, ORDER BY deyiminde, sorguyu güncellemeyi kolaylaştırmak için sütunların sayılarla değil adlarıyla belirtilmesi önerilir. sütunların seçim listesine eklenmesi veya listeden çıkarılması gerekiyorsa. ORDER BY yan tümcesindeki sütunların numaralarına göre belirtilmesi aşağıdaki örnekte gösterilmiştir:
SampleDb'yi KULLANIN; Works_on GRUBU'NDAN ProjeNumarasına Göre ProjeNumarası, COUNT(*) "Çalışan sayısı" SEÇİN SİPARİŞ 2 TANIMLA;
Burada, her proje için, proje numarası ve projeye katılan çalışan sayısı seçilir, sonuç çalışan sayısına göre azalan sırada sıralanır.
Transact-SQL artan sıralamada listenin başına, azalan sıralamada ise listenin sonuna NULL değerleri koyar.
Sonuçları Sayfalandırmak İçin ORDER BY Maddesini Kullanma
Geçerli sayfada sorgu sonuçlarının görüntülenmesi şu şekilde uygulanabilir: kullanıcı uygulaması veya veritabanı sunucusuna bunu yapması talimatını verin. İlk durumda, tüm veritabanı satırları, görevi gerekli satırları seçmek ve görüntülemek olan uygulamaya gönderilir. İkinci durumda, sunucu tarafından yalnızca geçerli sayfa için gerekli satırlar seçilir ve görüntülenir. Tahmin edebileceğiniz gibi, sunucu taraflı sayfa oluşturma genellikle daha iyi performans sağlar çünkü istemciye yalnızca görüntüleme için gerekli satırlar gönderilir.
Sunucu tarafı sayfa oluşturmayı desteklemek için SQL Server 2012, iki yeni SELECT deyimi yan tümcesi sunar: OFFSET ve FETCH. Bu iki cümlenin uygulaması aşağıdaki örnekte gösterilmiştir. Burada, AdventureWorks2012 veri tabanından (kaynaklarda bulabilirsiniz), tüm kadın çalışanların işletme kimliği, iş unvanı ve doğum günü alınır ve sonuç, iş unvanına göre artan düzende sıralanır. Ortaya çıkan satır grubu 10 satırlık sayfalara bölünür ve üçüncü sayfa görüntülenir:
Bir cümlede TELAFİ ETMEK görüntülenen sonuçta atlanacak sonuç satırlarının sayısını belirtir. Bu sayı, satırlar ORDER BY yan tümcesine göre sıralandıktan sonra hesaplanır. Bir cümlede SONRAKİ GETİR eşleşen WHERE sayısını ve döndürülecek sıralanmış satırları belirtir. Bu yan tümcenin parametresi bir sabit, bir ifade veya başka bir sorgunun sonucu olabilir. FETCH NEXT yan tümcesi, yan tümceye benzer İLK GETİR.
Sunucu tarafında sayfa oluştururken ana amaç, değişkenleri kullanarak ortak sayfa formlarını uygulayabilmektir. Bu görevi SQL Server paketi aracılığıyla gerçekleştirebilirsiniz.
SELECT deyimi ve KİMLİK özelliği
KİMLİK özelliği belirli bir tablo sütunu için değerleri otomatik olarak artan bir sayaç olarak tanımlamanıza olanak tanır. TINYINT, SMALLINT, INT ve BIGINT gibi sayısal veri türü sütunları bu özelliğe sahip olabilir. Böyle bir tablo sütunu için Veritabanı Motoru, belirtilen başlangıç değerinden başlayarak otomatik olarak sıralı değerler üretir. Böylece IDENTITY özelliği kullanılarak seçilen sütun için tek haneli sayısal değerler üretilebilir.
Bir tablo, IDENTITY özelliğine sahip yalnızca bir sütun içerebilir. Tablonun sahibi, aşağıdaki örnekte gösterildiği gibi başlangıç değerini ve artışını belirleme olanağına sahiptir:
SampleDb'yi KULLANIN; TABLO OLUŞTUR Ürün (Id INT IDENTITY(10000, 1) NOT NULL, Name NVARCHAR(30) NOT NULL, Price MONEY) INSERT INTO Product(Ad, Price) VALUES ("Item1", 10), ("Item2", 15) , ("Öğe3", 8), ("Öğe4", 15), ("Öğe5", 40); -- 10004 döndürür WHERE Üründen KİMLİĞİ SEÇİN Ad = "Ürün5"; -- Önceki ifadeye benzer şekilde SELECT $identity FROM Product WHERE Ad = "Product5";
Bu örnek, önce IDENTITY özelliğine sahip bir Id sütunu içeren bir Ürün tablosu oluşturur. Id sütunundaki değerler sistem tarafından otomatik olarak 10.000'den başlayarak ve sonraki her değer için bir artarak oluşturulur: 10.000, 10.001, 10.002 vb.
Çeşitli sistem işlevleri ve değişkenleri, IDENTITY özelliğiyle ilişkilidir. Örneğin, örnek kod kullanır $kimlik sistem değişkeni. Bu kodun çıktısından da görebileceğiniz gibi, bu değişken otomatik olarak IDENTITY özelliğine başvuruyor. Bunun yerine sistem işlevini de kullanabilirsiniz. KİMLİKCOL.
IDENTITY özelliğine sahip bir sütunun başlangıç değeri ve artışı, işlevler kullanılarak bulunabilir. IDENT_SEED Ve IDENT_INCR sırasıyla. Bu işlevler aşağıdaki gibi uygulanır:
SampleDb'yi KULLANIN; IDENT_SEED("Ürün"), IDENT_INCR("Ürün") SEÇİN
Daha önce de belirtildiği gibi, KİMLİK değerleri sistem tarafından otomatik olarak ayarlanır. Ancak kullanıcı, parametreyi ayarlayarak belirli satırlar için kendi değerlerini açıkça belirtebilir. KİMLİK_GİRİN Açık bir değer eklemeden önce AÇIK:
KİMLİK INSERT tablo adını AÇIK AYARLA
IDENTITY_INSERT seçeneği, yinelenen bir değer de dahil olmak üzere bir IDENTITY özellik sütunu için herhangi bir değer ayarlamak üzere kullanılabildiğinden, IDENTITY özelliği genellikle sütun değerlerinin benzersizliğini zorlamaz. Bu nedenle, sütun değerlerinin benzersizliğini zorlamak için UNIQUE veya PRIMARY KEY kısıtlamaları kullanılmalıdır.
IDENTITY_INSERT açık olarak ayarlandıktan sonra bir tabloya değerler girildiğinde, sistem o sütunun mevcut en büyük değerini artırarak bir sonraki IDENTITY sütun değerini oluşturur.
SIRASI OLUŞTUR deyimi
KİMLİK özelliğinin kullanılması, en önemlileri aşağıdakiler olan birkaç önemli dezavantaja sahiptir:
özellik uygulaması belirtilen tablo ile sınırlıdır;
sütunun yeni değeri, onu uygulamaktan başka bir yolla elde edilemez;
KİMLİK özelliği yalnızca bir sütun oluşturulurken belirtilebilir.
Bu nedenlerden dolayı, SQL Server 2012, IDENTITY özelliğiyle aynı semantiğe sahip, ancak daha önce listelenen dezavantajlar olmadan diziler sunar. Bu bağlamda bir sıra, sütunlar ve değişkenler gibi çeşitli veritabanı nesneleri için sayaç değerleri belirtmenize olanak sağlayan bir veritabanı işlevidir.
Diziler talimat kullanılarak oluşturulur DİZİ OLUŞTUR. CREATE SEQUENCE deyimi, SQL standardında tanımlanmıştır ve IBM DB2 ve Oracle gibi diğer ilişkisel veritabanı sistemleri tarafından desteklenir.
Aşağıdaki örnek, SQL Server'da bir sıranın nasıl oluşturulacağını gösterir:
SampleDb'yi KULLANIN; DİZİ OLUŞTUR dbo.Sequence1 AS INT 1 ARTIRMA İLE 5 MIN DEĞER 1 MAKS DEĞER 256 DÖNGÜ;
Yukarıdaki örnekte, Sıra1'in değerleri sistem tarafından otomatik olarak, 1 değerinden başlayarak sonraki her değer için 5'lik artışlarla oluşturulur. Böylece, içinde teklif BAŞLAT başlangıç değeri belirtilir ve ARTTIRMA teklifi- adım. (Adım pozitif veya negatif olabilir.)
Sonraki iki isteğe bağlı cümlede MİNDEĞER Ve MAKSİMUM DEĞER minimum ve maksimum değer sıra nesnesi. (MİNDEĞER değerinin başlangıç değerinden küçük veya ona eşit olması gerektiğini ve MAKSDEĞER değerinin sıra için belirtilen veri tipinin üst sınırından büyük olamayacağına dikkat edin.) Yan tümcede DÖNGÜ maksimum (veya negatif adımlı bir dizi için minimum) değeri aşıldığında dizinin baştan tekrarlandığını gösterir. Varsayılan olarak, bu yan tümce NO CYCLE'dir; bu, maksimum veya minimum sıra değerinin aşılmasının bir istisnaya neden olduğu anlamına gelir.
Dizilerin ana özelliği, tablolardan bağımsız olmalarıdır, yani. tablo sütunları veya değişkenler gibi herhangi bir veritabanı nesnesiyle kullanılabilirler. (Bu özelliğin depolama ve dolayısıyla performans üzerinde olumlu bir etkisi vardır. Belirli bir dizinin saklanması gerekmez; yalnızca son değeri saklanır.)
ile yeni dizi değerleri oluşturulur. İfadeler İÇİN SONRAKİ DEĞER, kullanımı aşağıdaki örnekte gösterilmiştir:
SampleDb'yi KULLANIN; -- 1 döndürür dbo.sequence1 İÇİN SONRAKİ DEĞERİ SEÇİN; -- 6 döndürür (sonraki adım) dbo.sequence1 İÇİN SONRAKİ DEĞERİ SEÇİN;
Bir dizinin sonucunu bir değişkene veya sütun hücresine atamak için NEXT VALUE FOR ifadesini kullanabilirsiniz. Aşağıdaki örnek, sonuçları bir sütuna atamak için bu ifadenin kullanımını göstermektedir:
SampleDb'yi KULLANIN; TABLO OLUŞTUR Ürün (Id INT NOT NULL, Name NVARCHAR(30) NOT NULL, Price MONEY) INSERT INTO Ürün DEĞERLERİ (dbo.sequence1 İÇİN SONRAKİ DEĞER, "Ürün1", 10); Ürün DEĞERLERİNE EKLEYİN (dbo.sequence1, "Ürün2", 15 İÇİN SONRAKİ DEĞER); -- ...
Yukarıdaki örnek, önce dört sütunlu bir Ürün tablosu oluşturur. Ardından, iki INSERT ifadesi bu tabloya iki satır ekler. İlk sütundaki ilk iki hücre 11 ve 16 değerlerine sahip olacaktır.
Aşağıdaki örnek, katalog görünümünün kullanımını göstermektedir. sistem dizileri bir dizinin geçerli değerini kullanmadan görüntülemek için:
Tipik olarak NEXT VALUE FOR ifadesi, sistemi oluşturulan değerleri eklemeye zorlamak için bir INSERT deyiminde kullanılır. Bu ifade, OVER yan tümcesi kullanılarak çok satırlı bir sorgunun parçası olarak da kullanılabilir.
Mevcut bir dizinin bir özelliğini değiştirmek için şunu kullanın: ALTER SIRASI deyimi. Bu ifadenin en önemli kullanımlarından biri, belirtilen sırayı sıfırlayan RESTART WITH seçeneğidir. Aşağıdaki örnek, Sequence1'in hemen hemen tüm özelliklerini sıfırlamak için ALTER Sequence deyiminin kullanımını göstermektedir:
SampleDb'yi KULLANIN; ALTER SEQUENCE dbo.sequence1 100 ARTIRMA İLE 50 MİN DEĞER 50 MAKS DEĞER 200 DÖNGÜ YOK;
Talimatı kullanarak bir diziyi silin DÜŞME SIRASI.
Operatörleri Ayarla
Daha önce tartışılan işleçlere ek olarak, Transact-SQL üç küme işlecini daha destekler: UNION, INTERSECT ve EXCEPT.
BİRLİK operatörü
BİRLİK operatörü iki veya daha fazla sorgunun sonuçlarını birleştirmedeki tüm sorgulara ait tüm satırları içeren tek bir sonuç kümesinde birleştirir. Buna göre, iki tablonun birleştirilmesinin sonucu, orijinal tablolardan birinde veya bu tabloların her ikisinde yer alan tüm satırları içeren yeni bir tablodur.
UNION operatörünün genel formu şöyle görünür:
seç_1 BİRLİK seç_2(seç_3])...
select_1, select_2, ... seçenekleri, bir birleştirme oluşturan SELECT deyimleridir. ALL seçeneği kullanılırsa, yinelenenler dahil tüm satırlar görüntülenir. UNION operatöründe ALL parametresi, SELECT seçim listesindekiyle aynı anlama sahiptir, bir farkla: SELECT seçim listesi için bu parametre varsayılan olarak uygulanır, ancak UNION operatörü için açıkça belirtilmesi gerekir.
Orijinal haliyle SampleDb veritabanı, UNION operatörünün kullanımını göstermek için uygun değildir. Bu nedenle, bu bölüm, mevcut Çalışan tablosuyla aynı olan ancak ek bir Şehir sütunu olan yeni bir ÇalışanEnh tablosu oluşturur. Bu sütun, çalışanların nerede yaşadığını gösterir.
ÇalışanEnh tablosunu oluşturmak bize yan tümcenin kullanımını gösterme fırsatı sağlar. İÇİNE SELECT ifadesinde. SELECT INTO deyimi iki işlem gerçekleştirir. İlk olarak, SELECT seçim listesinde listelenen sütunlarla yeni bir tablo oluşturulur. Ardından, orijinal tablonun satırları yeni tabloya eklenir. Yeni tablonun adı INTO yan tümcesinde, kaynak tablonun adı ise FROM yan tümcesinde belirtilir.
Aşağıdaki örnek, Çalışan tablosundan ÇalışanEnh tablosunun oluşturulmasını göstermektedir:
SampleDb'yi KULLANIN; Çalışan'dan ÇalışanEnh'e * SEÇİN; ALTER TABLE ÇalışanEnh EKLE Şehir NCHAR(40) NULL;
Bu örnekte, SELECT INTO deyimi, ÇalışanEnh tablosunu oluşturur, Çalışan tablosundaki tüm satırları tabloya ekler ve ardından ALTER TABLE deyimi, Şehir sütununu yeni tabloya ekler. Ancak eklenen Şehir sütunu herhangi bir değer içermiyor. Bu sütundaki değerler, Management Studio aracılığıyla veya aşağıdaki kod kullanılarak eklenebilir:
SampleDb'yi KULLANIN; GÜNCELLEME ÇalışanEnh SET City="Kazan" WHERE Id=2581; GÜNCELLEME ÇalışanEnh SET Şehir = "Moskova" WHERE Id = 9031; GÜNCELLEME ÇalışanEnh SET Şehir = "Yekaterinburg" WHERE Id = 10102; GÜNCELLEME ÇalışanEnh SET Şehir = "Saint Petersburg" WHERE Id = 18316; GÜNCELLEME ÇalışanEnh SET Şehir = "Krasnodar" WHERE Id = 25348; GÜNCELLEME ÇalışanEnh SET City="Kazan" WHERE Id=28559; GÜNCELLEME ÇalışanEnh SET City="Perm" WHERE Id=29346;
Artık UNION ifadesinin kullanımını göstermeye hazırız. Aşağıdaki örnekte, bu ifadeyi kullanarak EmployeeEnh ve Department tabloları arasında bir birleştirme oluşturmak için bir sorgu gösterilmektedir:
SampleDb'yi KULLANIN; ÇalışanEnh BİRLİĞİNDEN "Şehir" OLARAK İl SEÇİN Departmandan Yer SEÇİN;
Bu sorgunun sonucu:
UNION deyimi kullanılarak yalnızca uyumlu tablolar birleştirilebilir. Uyumlu tablolar derken, seçimdeki her iki sütun listesinin de aynı sayıda sütun içermesi ve karşılık gelen sütunların uyumlu veri türlerine sahip olması gerektiğini kastediyoruz. (Uyumluluk açısından INT ve SMALLINT veri türleri uyumlu değildir.)
Bir birleştirmenin sonucu, aşağıdaki örnekte gösterildiği gibi yalnızca son SELECT deyimindeki ORDER BY yan tümcesi kullanılarak sıralanabilir. GROUP BY ve HAVING yan tümceleri bireysel SELECT deyimleriyle kullanılabilir, ancak birleştirmenin kendisinde kullanılamaz.
Bu örnekteki sorgu, d1 departmanında çalışan veya 1 Ocak 2008'den önce proje üzerinde çalışmaya başlayan çalışanları getirir.
UNION işleci ALL seçeneğini destekler. Bu seçenek kullanıldığında, kopyalar sonuç kümesinden kaldırılmaz. Bir veya daha fazla UNION işleci tarafından birleştirilen tüm SELECT deyimleri aynı tabloya başvuruyorsa, UNION işleci yerine OR işlecini kullanabilirsiniz. Bu durumda, SELECT deyimleri kümesi, OR deyimlerinden oluşan tek bir SELECT deyimi ile değiştirilir.
INTERSECT ve EXCEPT ifadeleri
Kümelerle çalışmak için diğer iki operatör, KESİŞTİRME Ve HARİÇ, sırasıyla kesişimi ve farkı tanımlayın. Bu bağlamda kesişme noktasının altında her iki tabloya ait satırlar kümesi bulunur. Ve iki tablonun farkı, birinci tabloya ait olan ve ikincide olmayan tüm değerler olarak tanımlanır. Aşağıdaki örnek, INTERSECT deyiminin kullanımını göstermektedir:
Transact-SQL, ALL seçeneğinin INTERSECT deyimi veya EXCEPT deyimi ile kullanımını desteklemez. EXCEPT deyiminin kullanımı aşağıdaki örnekte gösterilmiştir:
Bu üç operatör kümesinin farklı yürütme önceliğine sahip olduğunu unutmayın: INTERSECT operatörü en yüksek önceliğe sahiptir, ardından EXCEPT operatörü gelir ve UNION operatörü en düşük önceliğe sahiptir. Birden çok farklı küme işleci kullanılırken yürütme önceliğine dikkat edilmemesi beklenmeyen sonuçlara yol açabilir.
CASE ifadeleri
Veritabanı uygulama programlama alanında, bazen verilerin sunumunu değiştirmek gerekir. Örneğin, insanlar sırasıyla erkekleri, kadınları ve çocukları ifade eden 1, 2 ve 3 değerleri kullanılarak sosyal ilişkilerine göre kodlanarak alt gruplara ayrılabilir. Bu programlama tekniği, programı uygulamak için gereken süreyi azaltabilir. CASE ifadesi Transact-SQL dili, bu tür kodlamayı uygulamayı kolaylaştırır.
Çoğu programlama dilinden farklı olarak, CASE bir ifade değil, bir ifadedir. Bu nedenle, bir CASE ifadesi, Transact-SQL dilinin ifadelerin kullanımına izin verdiği hemen hemen her yerde kullanılabilir. CASE ifadesinin iki biçimi vardır:
basit bir CASE ifadesi;
arama ifadesi CASE.
Basit bir CASE ifadesinin sözdizimi aşağıdaki gibidir:
Basit bir CASE ifadesine sahip bir ifade, önce içindeki tüm ifadelerin listesini arar. WHEN yan tümcesi ifade_1 ile eşleşen ve ardından karşılık gelen ifadeyi çalıştıran ilk ifade THEN cümlesi. WHEN listesinde eşleşen bir ifade yoksa, o zaman BAŞKA yan tümce.
Bir CASE arama ifadesinin sözdizimi şöyledir:
İÇİNDE bu durum ilk eşleşen koşul aranır ve ardından karşılık gelen THEN yan tümcesi yürütülür. Koşullardan hiçbiri gereksinimlerle eşleşmezse, ELSE yan tümcesi yürütülür. CASE arama ifadesinin kullanımı aşağıdaki örnekte gösterilmiştir:
SampleDb'yi KULLANIN; ProjeAdı, Bütçe > 0 VE Bütçe 100000 VE Bütçe 150000 VE Bütçe OLDUĞUNDA VAKA SEÇİN
Bu sorgunun sonucu:

Bu örnek, tüm projelerin bütçelerini ağırlıklandırır ve hesaplanan ağırlıklarını ilgili proje adlarıyla birlikte görüntüler.
Aşağıdaki örnek, CASE ifadesini kullanmanın başka bir yolunu gösterir; burada WHEN yan tümcesi, ifadenin parçası olan alt sorguları içerir:
SampleDb'yi KULLANIN; ProjeAdı SEÇİN, CASE WHEN p1.Budget (Proje p2'DEN ORTALAMA(p2.Bütçe) SEÇİN) SONRA Proje p1'DEN "Ortalamanın Üstünde" SON "Bütçe Kategorisi"ni SONLANDIRIN;
Bu sorgunun sonucu aşağıdaki gibidir:

Veritabanında bulunan bilgileri özetlemek için SQL, toplama işlevleri sağlar. Toplama işlevi, tüm veri sütununu bağımsız değişken olarak alır ve bu sütunu bir şekilde özetleyen tek bir değer döndürür.
Örneğin, AVG() toplama işlevi, bir sayı sütununu bağımsız değişken olarak alır ve bunların ortalamasını hesaplar.
Bir Zelenograd sakininin kişi başına ortalama gelirini hesaplamak için aşağıdaki sorguya ihtiyacınız var:
'ORTALAMA GELİR=', ORTALAMA(TOPLAM) SEÇİN
SQL, elde etmenize izin veren altı toplama işlevine sahiptir. Farklı türdeözet bilgi (Şekil 1):
– SUM(), sütunda yer alan tüm değerlerin toplamını hesaplar;
– AVG(), sütunda yer alan değerler arasındaki ortalamayı hesaplar;
– MIN(), sütunda yer alan tüm değerler arasından en küçüğünü bulur;
– MAX(), sütunda yer alan tüm değerler arasında en büyüğünü bulur;
– COUNT(), bir sütunda yer alan değerlerin sayısını sayar;
– COUNT(*), sorgu sonuç tablosundaki satır sayısını sayar.
Toplam işlev bağımsız değişkeni, önceki örnekte olduğu gibi basit bir sütun adı veya kişi başına verginin hesaplanmasını belirten aşağıdaki sorguda olduğu gibi bir ifade olabilir:
ORTALAMA SEÇ(TOPLA*0,13)
Bu sorgu, PERSON tablosundaki her satır için değerleri (SUMD*0.13) içeren geçici bir sütun oluşturur ve ardından geçici sütunun ortalamasını hesaplar.
Tüm Zelenograd sakinlerinin gelirlerinin toplamı, SUM toplama işlevi kullanılarak hesaplanabilir:
KİŞİDEN TOPLAM(TOPLAM) SEÇİN
Birkaç kaynak tablo birleştirilerek elde edilen bir sonuç tablosu için toplamları hesaplamak için bir toplama işlevi de kullanılabilir. Örneğin, "Burs" adı verilen bir kaynaktan sakinlerin aldığı toplam gelir miktarını hesaplayabilirsiniz:
TOPLAM(PARA) SEÇ
KARDAN, HAVE_D
NERDE PROFIT.ID=HAVE_D.ID
VE PROFIT.SOURCE='Burs'
Toplama işlevleri MIN() ve MAX(), sırasıyla en küçük ve en büyük değer masada. Ancak, sütun sayısal veya dize değerleri ya da tarih veya saat değerleri içerebilir.
Örneğin, şunları tanımlayabilirsiniz:
(a) ikamet edenler tarafından alınan en düşük toplam gelir ve ödenecek en yüksek vergi:
MIN(TOPLAM), MAKS(TOPLAM*0,13) SEÇİN
(b) ikamet eden en yaşlı ve en genç kişinin doğum tarihleri:
MIN(RDATE), MAX(RDATE) SEÇİN
(c) listedeki ilk ve en son ikamet edenlerin soyadları, adları ve soyadı, alfabetik olarak sıralanmıştır:
MIN(FIO), MAX(FIO) SEÇİN
Bu toplama işlevlerini uygularken, sayısal verilerin aritmetik kurallara göre karşılaştırıldığını, tarihlerin sırayla karşılaştırıldığını (önceki tarih değerleri sonrakilerden daha küçük kabul edilir), zaman aralıklarının sürelerine göre karşılaştırıldığını hatırlamanız gerekir.
Dize verileriyle MIN() ve MAX() işlevlerini kullanırken, iki diziyi karşılaştırmanın sonucu kullanılan karakter kodlama tablosuna bağlıdır.
COUNT() toplama işlevi, herhangi bir türdeki bir sütundaki değerlerin sayısını sayar:
(a) 1. mikro bölgede kaç daire var?
ADR'NİN "%, 1_ _-%" GİBİ ADR'NİN YERİNDEN COUNT(ADR) SEÇİN
(b) kaç sakinin gelir kaynağı var?
HAVE_D'DEN SAYI (FARKLI NOM) SEÇİN
(c) Sakinler tarafından kaç tane gelir kaynağı kullanılıyor?
HAVE_D'DEN SAYI SEÇ(DISTINCT ID) (DISTINCT anahtar sözcüğü, bir sütundaki yinelenmeyen değerlerin sayıldığını belirtir).
Özel toplama işlevi COUNT(*), veri değerlerini değil, sonuç tablosundaki satırları sayar:
(a) 2. mikro bölgede kaç daire var?
ADR'NİN "%, 2__-%" GİBİ ADR'NİN YERİNDEN COUNT(*) SEÇİN
(b) Ivanov Ivan Ivanovich'in kaç tane gelir kaynağı var?
PERSON'DAN SAYI(*) SEÇİN, HAVE_D WHERE FIO="Ivanov Ivan Ivanovich" VE PERSON.NOM=HAVE_D.NOM
(c) Belirli bir adresteki bir apartman dairesinde kaç kişi yaşıyor?
ADR'NİN OLDUĞU KİŞİDEN SAYI(*) SEÇİN=“Zelenograd, 1001-45”
Toplama işlevlerine sahip özet sorguların nasıl yürütüldüğünü anlamanın bir yolu, sorgu yürütmeyi iki parçaya bölünmüş olarak düşünmektir. İlk olarak, sorgunun toplama işlevleri olmadan nasıl çalışacağı belirlenir ve birden çok sonuç satırı döndürülür. Toplama işlevleri daha sonra tek bir özet satırı döndürerek sorgu sonuçlarına uygulanır.
Örneğin, aşağıdaki karmaşık sorguyu ele alalım: kişi başına düşen ortalama toplam geliri, sakinlerin toplam gelirlerinin toplamını ve kaynağın ortalama gelirini, sakinlerin toplam gelirinin yüzdesi olarak bulun. Cevap operatör tarafından verilir.
PERSON, PROFIT, HAVE_D WHERE PERSON.NOM=HAVE_D.NOM AND HAVE_D.ID=PROFIT.ID'DEN ORTALAMA(TOPLAM), TOPLAM(TOPLAM), (100*ORTA(MONEY/SUMD)) SEÇİN
Toplama işlevleri olmadan, sorgu şöyle görünür:
KİŞİDEN TOPLAM, TOPLAM, PARA/TOPLAM SEÇİN, KAR, HAVE_D WHERE PERSON.NOM=HAVE_D.NOM VE HAVE_D.ID=KAR.ID
ve her ikamet eden kişi ve belirli bir gelir kaynağı için bir satır sonuç döndürür. Toplama işlevleri, özet sonuçları olan tek satırlık bir tablo oluşturmak için sorgunun sonuç tablosunun sütunlarını kullanır.
Herhangi bir sütun adı yerine, döndürülen sütunlar dizesinde bir toplama işlevi belirtebilirsiniz. Örneğin, iki toplama işlevinin değerlerini toplayan veya çıkaran bir ifadenin parçası olabilir:
KİŞİDEN MAX(SUMD)-MIN(SUMD) SEÇİN
Bununla birlikte, bir toplama işlevi, başka bir toplama işlevinin argümanı olamaz, örn. iç içe toplama işlevleri yasaktır.
Ayrıca, döndürülen sütunlar listesinde toplama işlevlerini ve normal sütun adlarını aynı anda kullanamazsınız, çünkü bu bir anlam ifade etmez, örneğin:
KİŞİDEN FIO, SUM(TOPLA) SEÇİN
Burada, listenin ilk öğesi DBMS'ye birkaç satırdan oluşacak ve her sakin için bir satır içerecek bir tablo oluşturmasını söyler. Listenin ikinci öğesi, DBMS'den SUMD sütunundaki değerlerin toplamı olan tek bir sonuç değeri döndürmesini ister. Bu iki yön birbiriyle çelişir ve bir hataya neden olur.
Yukarıdakiler, alt sorguların ve gruplandırmalı sorguların işlenmesi durumları için geçerli değildir.
ISO standardı aşağıdaki beş şeyi tanımlar: toplama işlevleri:
SAYMAK– belirtilen sütundaki değerlerin sayısını döndürür;
TOPLAM– belirtilen sütundaki değerlerin toplamını döndürür;
ortalama– belirtilen sütundaki ortalama değeri verir;
DAK– belirtilen sütundaki minimum değeri döndürür;
MAKS.- belirtilen sütundaki maksimum değeri döndürür.
Bu işlevlerin tümü, tek bir tablo sütunundaki değerler üzerinde çalışır ve tek bir değer döndürür. COUNT, MIN ve MAX işlevleri hem sayısal hem de sayısal olmayan alanlar için geçerliyken TOPLA ve AVG işlevleri yalnızca sayısal alanlar için kullanılabilir. COUNT(*) dışında, herhangi bir işlevin sonuçları hesaplanırken önce tüm boş değerler elenir, ardından gerekli işlem yalnızca sütunun boş olmayan kalan değerlerine uygulanır. COUNT (*) değişkeni, COUNT işlevi için özel bir kullanım durumudur - amacı, bir tablodaki tüm satırları saymaktır; ister boş değerler, yinelenenler veya başka bir değer içersinler. Bir toplama işlevini kullanmadan önce yinelenen değerleri ortadan kaldırmak istiyorsanız, işlev tanımındaki sütun adından önce DISTINCT anahtar sözcüğünü kullanmalısınız. ISO standardı, yinelenen değerlerin ortadan kaldırılmasının gerekli olmadığını açıkça belirtmek için ALL anahtar kelimesinin kullanılmasına izin verir, ancak başka hiçbir niteleyici belirtilmezse bu anahtar kelime varsayılan olarak ima edilir. DISTINCT anahtar sözcüğünün MIN ve MAX işlevleri için bir anlamı yoktur. Ancak kullanımı TOPLA ve AVG işlevlerinin sonuçlarını etkileyebilir, bu nedenle her birinde bulunup bulunmadığını önceden düşünmelisiniz. özel durum. Ayrıca DISTINCT anahtar sözcüğü her sorguda en fazla bir kez belirtilebilir.
Toplama işlevlerinin yalnızca bir SELECT seçim listesinde ve bir HAVING yan tümcesinde kullanılabileceğini unutmayın (bkz. bölüm 5.3.4). Diğer tüm durumlarda, bu işlevlerin kullanımına izin verilmez. SELECT listesi bir toplama işlevi içeriyorsa ve sorgu gövdesinde verilerin gruplandırılmasını sağlayan GROUP BY yan tümcesi yoksa, SELECT seçim listesinin hiçbir öğesi, o sütun toplama işlevi olarak kullanılmadığı sürece herhangi bir sütun referansı içeremez. parametre. Örneğin, aşağıdaki sorgu geçersiz:
SEÇMEpersonelHayır,SAYMAK (maaş)
İTİBARENkadro;
Hata şu ki verilen istek eksik tasarım GRUPLANDIRMAYA GÖRE, ve SELECT listesindeki staffNo sütununa bir toplama işlevi kullanılmadan erişilir.
Örnek 13: COUNT(*) İşlevini KullanmaAyda 350 Sterlin'den fazla kira bedeline sahip kiralık mülklerin sayısını belirleyin,
SAYI SEÇ(*) AS sayısı
İTİBARENözellik forrent
NEREDEkira > 350;
Yalnızca kirası ayda 350 £'dan fazla olan kiralık nesneleri sayma kısıtlaması, WHERE yan tümcesi kullanılarak uygulanır. Belirtilen koşulu karşılayan toplam kiralanan nesne sayısı, COUNT toplama işlevi kullanılarak belirlenebilir. Sorgu yürütmenin sonuçları Tablo'da sunulmuştur. 23.
Tablo 23
| saymak |
Örnek 14. COUNT(DISTINCT) işlevini kullanma.Mayıs 2001'de müşteriler tarafından kaç farklı kiralık mülkün denetlendiğini belirleyin.
SAYI SEÇİN(FARKLIözellikNo) AS sayısı
İTİBARENGörüntüleme
Yine, sorgu sonuçlarının yalnızca Mayıs 2001'de incelenen kiralamaları ayrıştırmakla sınırlandırılması, WHERE yan tümcesi kullanılarak elde edilir. Belirtilen koşulu karşılayan denetlenen nesnelerin toplam sayısı, COUNT toplama işlevi kullanılarak belirlenebilir. Bununla birlikte, aynı nesne farklı istemciler tarafından birden çok kez görüntülenebildiğinden, yinelenen değerleri hesaplamadan çıkarmak için işlev tanımında DISTINCT anahtar sözcüğü belirtilmelidir. Sorgu yürütmenin sonuçları Tablo'da sunulmuştur. 24.
Tablo 24
Örnek 16. MIN, MAXnAVG işlevlerini kullanma.Asgari, azami ve ortalama ücretlerin değerini hesaplayın.
DK SEÇİN(maaş) GİBİ dakika, MAKS.(maaş) GİBİ maksimum, ortalama(maaş) GİBİ ortalama
İTİBARENkadro;
Bu örnekte, şirketteki tüm personel hakkındaki bilgileri işlemeniz gerekir, bu nedenle WHERE yan tümcesini kullanmanız gerekmez. Personel tablosunun maaş sütununa uygulanan MIN, MAX ve AVG fonksiyonları kullanılarak gerekli değerler hesaplanabilir. Sorgu yürütmenin sonuçları Tablo'da sunulmuştur. 26.
Tablo 26
Sorgu sonucu
| dakika | maks. | ortalama |
| 9000.00 | 30000.00 | 17000.00 |
Gruplandırma sonuçları (GROUP BY yapısı). Yukarıdaki özet veri örnekleri, genellikle raporların sonunda bulunan özet satırlarına benzer. Sonuç olarak, tüm ayrıntılı rapor verileri tek bir özet satırında sıkıştırılır. Ancak, raporlarda sıklıkla ara toplamların da oluşturulması gerekir. Bu amaçla, SELECT deyiminde GROUP BY deyimi belirtilebilir. GROUP BY deyimi içeren bir sorgu çağrılır. grup sorgusu,çünkü SELECT işleminden kaynaklanan verileri gruplandırır ve ardından her bir grup için tek bir özet satırı oluşturulur. GROUP BY yan tümcesinde listelenen sütunlar gruplandırılmış sütunlar ISO standardı, SELECT ve GROUP BY yan tümcelerinin yakından ilişkili olmasını gerektirir. Bir SELECT deyiminde GROUP BY deyimini kullanırken, SELECT seçim listesindeki her liste öğesinin sahip olması gerekir. tüm grup için tek değer. Ayrıca, bir SELECT yapısı yalnızca aşağıdaki öğe türlerini içerebilir:
Sütun adları;
toplama işlevleri;
sabitler;
Yukarıdaki öğelerin kombinasyonlarını içeren ifadeler.
Sütun adı yalnızca bir toplama işlevinde kullanılmadığı sürece, SELECT listesindeki tüm sütun adları da GROUP BY yan tümcesinde görünmelidir. Tersi ifade her zaman doğru değildir - GROUP BY yan tümcesi, SELECT listesinde olmayan sütun adları içerebilir. WHERE yan tümcesi GROUP BY yan tümcesi ile birlikte kullanılırsa, önce o işlenir ve yalnızca arama koşulunu sağlayan satırlar gruplanır. ISO standardı, gruplama yapıldığında tüm eksik değerlerin eşit kabul edildiğini belirtir. Aynı gruplama sütunundaki iki tablo satırı NULL değerler içeriyorsa ve boş olmayan diğer tüm gruplandırma sütunlarında aynı değerler varsa, bunlar aynı gruba yerleştirilir.
Örnek 17: GROUP BY deyiminin kullanılması.Şirketin her bir bölümünde çalışan personel sayısını ve toplam ücretlerini belirleyin.
SEÇMEşubelerHayır, SAYMAK(personelNo) GİBİ saymak, TOPLAM(maaş) GİBİ toplam
İTİBARENKadro
GRUPLANDIRMAYA GÖREşubeHayır
TARAFINDAN SİPARİŞşubeNo;
GROUP BY öğe listesine staffNo ve maaş sütun adlarını dahil etmeye gerek yoktur, çünkü bunlar yalnızca toplama işlevleriyle SEÇ listesinde görünürler. Aynı zamanda SELECT yan tümcesinin listesindeki BranchNo sütunu herhangi bir toplama işleviyle ilişkili değildir ve bu nedenle GROUP BY yan tümcesinde belirtilmelidir. Sorgu yürütmenin sonuçları Tablo'da sunulmuştur. 27.
Tablo 27
Sorgu sonucu
| şubeHayır | Saymak | toplam |
| B003 | 54000.00 | |
| B005 | 39000.00 | |
| B007 | 9000.00 |
Kavramsal olarak, bu istek işlenirken aşağıdaki eylemler gerçekleştirilir.
1. Personel tablosunun satırları, şirket şube numarası sütunundaki değerlere göre gruplara dağıtılır. Grupların her birinde, şirketin bölümlerinden birinin tüm personeline ilişkin veriler bulunur. Örneğimizde, Şekil l'de gösterildiği gibi üç grup oluşturulacaktır. 1.
2. Grupların her biri için, departman çalışanlarının sayısına eşit olan toplam satır sayısı ve ayrıca tüm departmanların ücretlerinin toplamı olan maaş sütunundaki değerlerin toplamı hesaplanır. bizi ilgilendiren çalışanlar. Ardından, tüm kaynak satır grubu için tek bir özet satırı oluşturulur.
3. Ortaya çıkan tablonun gelen satırları, şubeNo sütununda belirtilen şube numarasına göre artan sırada sıralanır.
| şubeHayır | personelHayır | Maaş |
| B00Z | SG37 | 12000.00 |
| B00Z | SG14 | 18000.00 |
| B00Z | SG5 | 24000.00 |
| B005 | SL21 | 30000.00 |
| B005 | SL41 | 9000.00 |
| B007 | SA9 | 9000.00 |
| COUNT(personelNo) | TOPLAM(maaş) |
| 54000.00 | |
| 39000.00 | |
| 9000.00 |
Pirinç. 1. Bir sorgu yürütülürken oluşturulan üç kayıt grubu
SQL standardı, alt sorguların SELECT seçim listesine yerleştirilmesine izin verir. Bu nedenle, yukarıdaki sorgu aşağıdaki gibi de temsil edilebilir:
SEÇMEşubeNo, (SEÇ SAYISI(personelNo)GİBİ saymak
İTİBARENpersonel
NEREDEs.branchNo = b.branchNo),
(SUM(maaş) TOPLAM OLARAK SEÇİN
İTİBARENpersonel
NEREDEs.branchNo = b.branchNo)
İTİBARENşube b
TARAFINDAN SİPARİŞşubeNo;
Ancak sorgunun bu versiyonunda, Şube tablosunda açıklanan şirketin şubelerinin her biri için toplama fonksiyonlarının hesaplanmasının iki sonucu üretilir, bu nedenle bazı durumlarda sıfır değerler içeren satırlar görünebilir.
Gruplandırma kısıtlamaları (HAVING yapısı). HAVING yan tümcesinin, GROUP BY yan tümcesiyle birlikte, bunları seçmek için kısıtlamalar belirtmek üzere kullanılması amaçlanmıştır. gruplar, sonuçta ortaya çıkan sorgu tablosuna yerleştirilecek. HAVING ve WHERE yan tümceleri benzer sözdizimine sahip olsa da amaçları farklıdır. WHERE yan tümcesi, ortaya çıkan sorgu tablosunu doldurması amaçlanan tek tek satırları seçmek için tasarlanmıştır ve HAVING yapısı, seçmek için kullanılır. gruplar, sonuç sorgu tablosuna yerleştirilir. ISO standardı, HAVING yan tümcesinde kullanılan sütun adlarının GROUP BY öğeleri listesinde bulunmasını veya toplama işlevlerinde kullanılmasını gerektirir. Uygulamada, bir HAVING yan tümcesindeki arama koşulları her zaman en az bir toplama işlevi içerir; aksi takdirde, bu arama terimleri bir WHERE yan tümcesine yerleştirilmeli ve tek tek satırları seçmek için uygulanmalıdır. (Toplama işlevlerinin bir WHERE yan tümcesinde kullanılamayacağını unutmayın.) HAVING yan tümcesi, SQL dilinin gerekli bir parçası değildir; HAVING yan tümcesi kullanılarak yazılan herhangi bir sorgu, bu yan tümce kullanılmadan başka türlü gösterilebilir.
Örnek 18: HAVING yapısının kullanılması.Birden fazla çalışanı olan şirketin her şubesi için çalışan sayısını ve ücret tutarını belirleyiniz.
SEÇMEşubelerHayır, SAYI T(personelNo) GİBİ saymak, TOPLAM(maaş) GİBİ toplam
İTİBARENKadro
GRUPLANDIRMAYA GÖREşubeHayır
SAYISI OLAN(personelNo) > 1
TARAFINDAN SİPARİŞşubeNo;
Bu örnek bir öncekine benzer, ancak yalnızca şirketin birden fazla kişiyi istihdam eden departmanları hakkındaki bilgilerle ilgilendiğimizi belirtmek için ek kısıtlamalar kullanır. Benzer bir gereksinim gruplar için geçerlidir, bu nedenle sorgu HAVING yapısını kullanmalıdır. Sorgu yürütmenin sonuçları Tablo'da sunulmuştur. 28.
Tablo 28
| şubeHayır toplamı saymak |
| В00З 3 54000.00 |
| B005 2 39000.00 |
Alt sorgular. Bu bölümde, başka bir SELECT deyiminin gövdesine gömülü tam SELECT deyimlerinin kullanımını tartışacağız. Harici(ikinci) SELECT ifadesi yürütme sonucunu kullanır dahili Tüm işlemin nihai sonucunun içeriğini belirlemek için (ilk) ifade. İç sorgular, dış SELECT ifadesinin WHERE ve HAVING yan tümcelerinde olabilir, bu durumda çağrılırlar. alt sorgular veya iç içe sorgular Ayrıca dahili SELECT ifadeleri INSERT, UPDATE ve DELETE ifadelerinde kullanılabilir. . Üç tür alt sorgu vardır.
skaler alt sorgu bir sütunun bir satırla kesişiminden seçilen bir değer döndürür, örn. tek değer. Prensip olarak, tek bir değerin gerekli olduğu her yerde bir skaler alt sorgu kullanılabilir. Sayısal alt sorguların varyantları örnek 13 ve 14'te gösterilmiştir.
Dize alt sorgusu bir tablonun birden çok sütununun değerlerini, ancak tek bir satır olarak döndürür. Bir dize alt sorgusu, bir dize değeri oluşturucusunun kullanıldığı her yerde kullanılabilir - genellikle yüklemlerdir. Dize alt sorgusunun bir çeşidi örnek 15'te gösterilmiştir.
Tablo alt sorgusu birden fazla satırı kapsayan bir tablonun bir veya daha fazla sütununun değerlerini döndürür. Tablo alt sorgusu, IN yükleminin işleneni gibi tabloya izin verilen her yerde kullanılabilir.
Örnek 19: Eşitlik testiyle bir alt sorgu kullanmak. Oluştur 463 Main St1 adresinde bulunan şirketin şubesinde görev yapan personel listesi.
SEÇME
İTİBARENKadro
NEREDEşubeNo = (ŞubeNo'yu SEÇİN
İTİBARENdal
NEREDEsokak = "163 Ana Cadde");
Dahili SELECT deyimi (SELECT BranchNo FROM Branch ...), "163 Main St" adresinde bulunan şirketin şube numarasını belirlemek için tasarlanmıştır. (Şirketin yalnızca bir şubesi vardır, bu nedenle bu örnek bir skaler alt sorgu örneğidir.) İstenen şube numarası elde edildikten sonra, o şubedeki çalışanlar hakkında ayrıntılı bilgi almak için harici bir alt sorgu yürütülür. Yani iç SELECT deyimi "BOOV" tek değerinden oluşan bir tablo döndürür.Bu, şirketin "163 Main St1. Sonuç olarak, dış SELECT ifadesi şöyle olur:
SEÇMEpersonelNo, fName, IName, pozisyon
İTİBARENKadro
NEREDEşubeNo = "B0031;
Bu sorgunun sonuçları Tablo'da sunulmuştur. 29.
Tablo 29
Sorgu sonucu
| personelHayır | fAd | İsim | konum |
| SG37 | Ann | Kayın | asistan |
| SG14 | Davut | ford | süpervizör |
| SG5 | Susan | marka | müdür |
Alt sorgu, içeriği harici bir operatör tarafından alınan ve işlenen geçici bir tablo oluşturmak için kullanılan bir araçtır. Alt sorgu, doğrudan karşılaştırma operatörlerinden sonra belirtilebilir (yani operatörler =,<, >, <=, >=, <>) WHERE veya HAVING yan tümcesinde. Alt sorgu metni parantez içine alınmalıdır.
Örnek 20. Toplama işlevleriyle alt sorguları kullanma. Ortalamanın üzerinde maaş alan tüm çalışanların, maaşlarının işletmedeki ortalama maaşı ne kadar aştığını gösteren bir listesini yapın.
SEÇMEpersonelNo, fName, IName, pozisyon, maaş - ( ORTALAMA SEÇ(maaş) İTİBAREN kadro) GİBİ salDiff
İTİBARENKadro
NEREDEmaaş > ( ORTALAMA SEÇ(maaş) İTİBAREN Kadro) ;
Doğrudan yapılamayacağına dikkat edilmelidir. dahil etmek sorgu ifadesi"NEREDE maaş > AVG(maaş)", toplamanın kullanılmasından bu yana WHERE yan tümcesindeki işlevlere izin verilmez. İstenen sonuca ulaşmak için, ortalama yıllık maaşı hesaplayan bir alt sorgu oluşturmalı ve ardından bunu, maaşı bu ortalamayı aşan şirket çalışanları hakkında bilgi seçmek için bir dış SELECT deyiminde kullanmalısınız. Başka bir deyişle, alt sorgu, şirketin yıllık ortalama maaşını, yani 17.000 £'u döndürür.
Bu skaler alt sorgunun yürütülmesinin sonucu, hem ücretlerin ortalama seviyeden sapmasını hesaplamak hem de çalışanlar hakkında bilgi seçmek için dış SELECT ifadesinde kullanılır. Böylece dış SELECT ifadesi şöyle olur:
SEÇMEpersonelNo, fName, IName, pozisyon, maaş - 17000 Gibi salDiff
İTİBARENKadro
NEREDEmaaş > 17000;
Sorgu yürütmenin sonuçları Tablo'da sunulmuştur. otuz.
Tablo 30
Sorgu sonucu
| personelHayır | fAd | İsim | konum | salDiff |
| SL21 | John | Beyaz | müdür | 13000.00 |
| SG14 | Davut | ford | süpervizör | 1000.00 |
| SG5 | Susan | marka | müdür | 7000.00 |
Alt sorgular geçerlidir kurallara uymak ve kısıtlamalar.
1. Alt sorgular ORDER BY yan tümcesini kullanmamalıdır, ancak dış SELECT deyiminde bulunabilir.
2. Alt sorguda EXISTS anahtar sözcüğü kullanılmadığı sürece, alt sorgunun SELECT listesi, bağımsız sütun adlarından veya bunlardan oluşan ifadelerden oluşmalıdır.
3. Varsayılan olarak, alt sorgudaki sütunların adları, alt sorgunun FROM yan tümcesinde adı belirtilen tabloya başvurur. Bununla birlikte, dış sorgunun FROM yan tümcesinde belirtilen tablonun sütunlarına, nitelikli sütun adları kullanılarak (aşağıda açıklandığı gibi) atıfta bulunulmasına da izin verilir.
4. Alt sorgu, karşılaştırma işleminde yer alan iki işlenenden biriyse, bu işlemin sağ tarafında alt sorgu belirtilmelidir. Örneğin, aşağıdaki önceki örnekteki sorgu gösterimi yanlıştır çünkü alt sorgu, maaş sütununun değerine göre karşılaştırma işleminin sol tarafına yerleştirilir.
SEÇME
İTİBARENKadro
NEREDE(Personelden AVG(maaş) SEÇİN)< salary;
Örnek 21. Yuvalanmış alt sorgular ve IN yükleminin kullanımı. "163 Main st1.
SEÇMEpropertyNo, sokak, şehir, posta kodu, tür, odalar, kira
İTİBARENözellik forrent
Bölüm 5. SQL Dili: Veri Manipülasyonu 189
NEREDEpersonelNo GİRİŞİ (personelHayır'ı SEÇİN
İTİBARENKadro
NEREDEbrancliNo = (şubeNo'yu SEÇ
İTİBARENdal
NEREDEcadde = "163 Ana Cadde")) ;
İlk, en iç sorgu, şirketin 463 Ana Cadde'de bulunan şube numarasını belirlemek için tasarlanmıştır. "İkinci, ara sorgu, bu şubede çalışan personel hakkındaki bilgileri seçer. Bu durumda, birden fazla satır veri seçilidir ve bu nedenle = karşılaştırma operatörünü kullanamazsınız. Bunun yerine IN anahtar kelimesini kullanmalısınız. ara sorgunun sonucu.Sorgunun sonuçları Tablo 31'de gösterilmiştir.
Tablo 31
Sorgu sonucu
| özellikHayır | sokak | şehir | posta kodu | tip | Odalar | kira |
| PG16 | 5 Yeni Doktor | Glasgow | G129AX | Düz | ||
| PG36 | 2 Malikane Yolu | Glasgow | G324QX | Düz | ||
| PG21 | 18 Dale Yolu | Glasgow | G12 | Ev |
HERHANGİ ve TÜM anahtar kelimeler. ANY ve ALL anahtar sözcükleri, tek bir sayı sütunu döndüren alt sorgularla kullanılabilir. Alt sorgu ALL anahtar sözcüğünden önce geliyorsa, karşılaştırma koşulu yalnızca alt sorgunun sonuç sütunundaki tüm değerler için doğruysa karşılanmış sayılır. Alt sorgu metninden önce ANY anahtar sözcüğü geliyorsa, sonuçta ortaya çıkan alt sorgu sütununda en az bir (bir veya daha fazla) değer sağlanıyorsa karşılaştırma koşulu sağlanmış olarak kabul edilecektir. Alt sorgu boş bir değerle sonuçlanırsa, ALL anahtar sözcüğü için karşılaştırma koşulu yerine getirilmiş olarak kabul edilecek ve ANY anahtar sözcüğü için başarısız olarak değerlendirilecektir. ISO standardına göre, ANY anahtar sözcüğünün eşanlamlısı olan SOME anahtar sözcüğünü de kullanabilirsiniz.
Örnek 22. HERHANGİ ve BAZI anahtar sözcüklerini kullanarak. Maaşı en az maaşını aşan tüm çalışanları bul bir şirketin bir şubesinin "booz" numarasıyla çalışanı.
SEÇMEpersonelNo, fName, IName, pozisyon, maaş
İTİBARENKadro
NEREDEmaaş > BAZI(maaş SEÇİN
İTİBARENKadro
NEREDEşubeNo="B003");
Bu sorgu, "WHO" numaralı departman personeli için asgari ücreti belirten bir alt sorgu kullanılarak yazılabilmesine rağmen, bundan sonra dış alt sorgu, maaşı bu değeri aşan şirketin tüm personeli hakkında bilgi seçebilir (bkz. Örnek 20), SOME/ANY anahtar kelimelerinin kullanımından oluşan başka bir yaklaşım da mümkündür. Bu durumda, iç alt sorgu bir dizi değer (12000, 18000, 24000) üretir ve dış sorgu, maaşı bu değerlerden herhangi birinden daha yüksek olan işçilerin ayrıntılarını seçer.
ayarlayın (aslında minimum değerden daha fazla - 12000). Bu alternatif yöntem, asgari ücreti bir alt sorguda tanımlamaktan daha doğal sayılabilir. Ancak her iki durumda da, Tablo'da sunulan aynı sorgu yürütme sonuçları oluşturulur. 32 .
Tablo 32
Sorgu sonucu
| personelHayır | fAd | İsim | konum | maaş |
| SL21 | John | Beyaz | müdür | 30000.00 |
| SG14 | Davut | ford | süpervizör | 18000.00 |
| SG5 | Susan | marka | müdür | 24000.00 |
Örnek 23. ALL anahtar sözcüğünü kullanarak. "Booz" numaralı şirketin şubesinde ücreti herhangi bir çalışanın ücretinden fazla olan tüm çalışanları bulunuz.
SEÇMEstaffNo, fName, INarae, pozisyon, maaş
İTİBARENKadro
NEREDEmaaş > TÜM(maaş SEÇİN
İTİBARENKadro
NEREDEşubeNo = "BOG3");
Genel olarak, bu sorgu bir öncekine benzer. Ve bu durumda, departman personelinin maaşının maksimum değerini "BOOS" numarası altında belirleyen bir alt sorgu kullanmak ve ardından şirketin tüm çalışanları hakkında bilgi seçmek için harici bir sorgu kullanmak mümkün olacaktır. maaş bu değeri aşıyor. Ancak bu örnekte ALL anahtar kelime yaklaşımı seçilmiştir. Sorgu yürütmenin sonuçları Tablo'da sunulmuştur. 33 .
Tablo 33
Sorgu sonucu
| personelHayır | İsim | fAd | konum | maaş |
| SL21 | Beyaz | John | müdür | 30000,00 |
Çok tablolu sorgular. Yukarıda tartışılan tüm örnekler aynı önemli sınırlamaya sahiptir: sonuç tablosuna yerleştirilen sütunlar her zaman tek bir tablodan seçilir. Ancak birçok durumda bu yeterli değildir. Ortaya çıkan tabloda birkaç kaynak tablodan sütunları birleştirmek için işlemi gerçekleştirmelisiniz. bağlantılar. SQL'de birleştirme işlemi, her tablodan seçilen ilgili satır çiftlerini oluşturarak iki tablodaki bilgileri birleştirmek için kullanılır. Birleştirilmiş tabloya yerleştirilen satır çiftleri, içlerinde yer alan belirtilen sütunların değerlerinin eşitliği ile oluşturulur.
Birden fazla tablodan bilgi almanız gerekiyorsa, bir alt sorgu kullanabilir veya tabloları birleştirebilirsiniz. Ortaya çıkan sorgu tablosunun farklı kaynak tablolardan sütunlar içermesi gerekiyorsa, tablo birleştirme mekanizmasının kullanılması tavsiye edilir. Bir birleştirme gerçekleştirmek için FROM yan tümcesinde iki veya daha fazla tablonun adını virgülle ayırarak belirtmek ve ardından belirtilen tabloları birleştirmek için kullanılan sütunların tanımıyla birlikte WHERE yan tümcesini sorguya dahil etmek yeterlidir. Ayrıca tablo adları yerine kullanabileceğiniz takma adlar, FROM yapısında onlara atanır. Bu durumda, tablo adları ve bunlara atanan takma adlar boşluklarla ayrılmalıdır. Takma adlar, belirli bir sütunun hangi tabloya ait olduğu konusunda belirsizlik olduğunda, sütun adlarını nitelemek için kullanılabilir. Ek olarak, takma adlar tablo adlarını kısaltmak için kullanılabilir. Bir tablo için alias tanımlanmışsa, o tablonun adının gerekli olduğu her yerde kullanılabilir.
Örnek 24. Basit bağlantı. Halihazırda en az bir kiralık mülk görmüş ve bu konuda görüş bildirmiş olan tüm müşterilerin adlarının bir listesini yapın.
SEÇMEc.clientNo, fName, IName, özellikNo, açıklama
İTİBARENİstemci c, Görüntüleme v
NEREDEc.clientNo = v.clientNo;
Bu raporun hem Müşteri tablosundan hem de Görüntüleme tablosundan bilgi sunması gerekir, bu nedenle bir sorgu oluştururken tablo birleştirme mekanizmasını kullanacağız. SELECT yapısı, sorgunun sonuç tablosuna yerleştirilmesi gereken tüm sütunları listeler. Birleştirmeye katılan başka bir tabloda böyle bir sütun da bulunabileceğinden, müşteri numarası sütununun (clientNo) nitelenmesi gerektiğini unutmayın. Bu nedenle, hangi tablo değerleriyle ilgilendiğimizi açıkça belirtmek gerekir. (Bu örnekte Viewing tablosundan clientNo kolonunun değerlerini de seçmiş olabilirsiniz). Ad kalifikasyonu, sütun adının önüne karşılık gelen tablonun adının (veya diğer adının) eklenmesiyle gerçekleştirilir. Örneğimizde, "c" değeri Müşteri tablosu için takma ad olarak belirtilmiştir. Ortaya çıkan satırları oluşturmak için, kaynak tabloların clientNo sütununda aynı değere sahip olan satırları kullanılır. Bu koşul, c.clientNo=v.clientNo arama koşulu belirtilerek belirlenir. Kaynak tabloların benzer sütunlarına denir eşleşen sütunlar Açıklanan işlem, işleme eşdeğerdir eşitlikle birleşirilişkisel cebir. Sorgu yürütmenin sonuçları Tablo'da sunulmuştur. 34.
Tablo 34
Sorgu sonucu
| müşteriHayır | fAd | İsim | özellikHayır | Yorum |
| CR56 | Aline | stewart | PG36 | |
| CR56 | Aline | stewart | PA14 | çok küçük |
| CR56 | Aline | stewart | PG4 | |
| CR62 | Mary | üç dişli | PA14 | yemek odası yok |
| CR76 | John | Kay | PG4 | çok uzak |
Çoğu zaman, çoklu tablo sorguları, bire çok (1:*) ilişkisi veya üst-alt ilişkisi ile birbirine bağlanan iki tablo üzerinde gerçekleştirilir. İstemci ve Görüntüleme tablolarına erişimi içeren yukarıdaki örnekte, ikincisi tam da böyle bir ilişkiyle birbirine bağlıdır. Görüntüleme tablosunun (alt) her satırı, Müşteri tablosunun (üst) yalnızca bir satırıyla ilişkilendirilirken, Müşteri tablosunun (üst) aynı satırı ilişkilendirilebilir
Görüntüleme tablosunun (alt) birçok satırıyla. Bir sorgu yürütüldüğünde oluşturulan satır çiftleri, alt ve üst tablolardaki tüm geçerli satır kombinasyonlarının sonucudur. Bölüm 3.2.5, ilişkisel bir veritabanında tabloların birincil ve yabancı anahtarlarının nasıl bir "ebeveyn-alt" ilişkisi oluşturduğunu ayrıntılarıyla anlatır. Yabancı anahtar içeren bir tablo genellikle bir çocuktur, birincil anahtar içeren bir tablo ise her zaman bir ebeveyn olacaktır. Bir SQL sorgusunda üst-alt ilişkisini kullanmak için, yabancı ve birincil anahtarları karşılaştıran bir arama koşulu belirtmeniz gerekir. Örnek 24, Müşteri tablosunun birincil anahtarını (v. clientNo) Görüntüleme tablosunun (v. clientNo) yabancı anahtarıyla karşılaştırır.
SQL standardı ayrıca belirli bir bağlantıyı tanımlamak için aşağıdaki yolları sağlar:
İTİBARENile müşteri KATILMAK v'yi görüntüleme AÇIK c.clientNo = v.clientNo
İTİBARENMüşteri J OİN Görüntüleme KULLANMAK müşteriHayır
İTİBARENmüşteri DOĞAL BİRLEŞTİRME Görüntüleme
Her durumda, FROM yan tümcesi orijinal FROM ve WHERE yan tümcelerinin yerini alır. Bununla birlikte, ilk durumda, iki özdeş clientNo sütunu ile bir tablo oluşturulurken, diğer iki durumda ortaya çıkan tablo yalnızca bir clientNo sütunu içerecektir.
Örnek 25. Tablo birleştirme sonuçlarını sıralayın. Şirketin her bir şubesi için personel sayısı ve kiralanan tesislerde sorumlu çalışanların adları ile kiralanan tesislerin listesi
ki cevap veriyorlar.
SEÇMEs.branchNo, s.staffNo, fName, IName, propertyNo
İTİBARENPersonel s, PropertyForRent p
NEREDEs.staffNo = p.staffNo
TARAFINDAN SİPARİŞs.branchNo, s.staffNo, özellikNo;
Sonuçların okunmasını kolaylaştırmak için çıktı, ana sıralama anahtarı olarak departman numarası ve ikincil anahtarlar olarak personel numarası ve mülk numarası kullanılarak sıralanır. Sorgu yürütmenin sonuçları Tablo'da sunulmuştur. 35.
Tablo 35
Sorgu sonucu
| şubeHayır | PersonelHayır | fAd | İsim | özellikHayır |
| DSÖ | SG14 | Davut | ford | PG16 |
| DSÖ | SG37 | Ann | Kayın | PG21 |
| DSÖ | SG37 | Ann | Kayın | PG36 |
| BOO5 | SL41 | Mary | Lee | PL94 |
| SBI7 | SA9 | Julie | nasıl | PA14 |
Örnek 26.Üç tabloyu birleştirmek. Şirketin her bir şubesi için, şubenin bulunduğu şehir de dahil olmak üzere, kiralanan herhangi bir tesisten sorumlu çalışanların isimlerini ve personel numaralarını ve her bir çalışanın sorumlu olduğu nesnelerin numaralarını listeleyin.
SEÇME b.branchNo, b.city, s.staffNo, fName, IName, propertyNo
İTİBARENŞube b, Personel s, PropertyForRent p
NEREDE b.branchNo = s.branchNo VE s.staffNo = p.staffNo
TARAFINDAN SİPARİŞ b.branchNo, s.staffNo, özellikNo;
Ortaya çıkan tablo, üç kaynak tablodan - Branch, Staff ve PropertyForRent - sütunlar içermelidir, dolayısıyla sorgu bu tablolara katılmalıdır. Şube ve Personel tabloları, b.branchNo=*s .branchNo koşulu kullanılarak şirketin şubelerini bu şubelerde çalışan personele bağlayacak şekilde birleştirilebilir. Staff ve PropertyForRent tabloları, s.staffNo=p.staffNo koşulu kullanılarak birleştirilebilir. Sonuç olarak, her çalışan, sorumlu olduğu kiralanan nesnelerle ilişkilendirilecektir. Sorgu yürütmenin sonuçları Tablo'da sunulmuştur. 36.
Tablo 36
Sorgu Sonuçları
| şubeHayır | şehir | personelMo | fAd | İsim | özellikHayır |
| B003 | Glasgow | SG14 | Davut | ford | PG16 |
| B003 | Glasgow | SG37 | Ann | Kayın | PG21 |
| B003 | Glasgow | SG37 | Ann | Kayın | PG36 |
| B005 | Londra | SL41 | Julie | Lee | PL94 |
| B007 | Aberdeen | SA9 | Mary | nasıl | PA14 |
SQL standardının kullanmanıza izin verdiğini unutmayın. Alternatif seçenek FROM ve WHERE yan tümcelerinin ifadeleri:
İTİBAREN(Şube b JOIN Personeli şubeyi KULLANIYORHayır) GİBİ bs
KATILMAKPropertyForRent p KULLANMAK personelHayır
Örnek 27. Birden çok sütuna göre gruplama. Şirketin her çalışanının sorumlu olduğu kiralık nesnelerin sayısını belirleyin.
SEÇMEs.branchNo, S.staffNo, SAYMAK(*) GİBİ saymak
FROM Staff s, PropertyForRent p
NEREDE S.staffNo = p.staffNo
GRUPLANDIRMAYA GÖREs.şubeHayır, s.personelHayır
TARAFINDAN SİPARİŞs.şubeNo, s.personelNo;
Gerekli raporu hazırlamak için öncelikle şirket çalışanlarından hangisinin kiralanan nesnelerden sorumlu olduğunu bulmak gerekir. Bu sorun, FROM/WHERE yan tümcelerindeki staffNo sütunundaki Staff ve PropertyForRent tablolarını birleştirerek çözülebilir. Daha sonra GROUP BY yapısının kullanılması gereken çalışanlarının şube numarası ve personel numaralarından oluşan gruplar oluşturmak gerekir. Son olarak, ortaya çıkan tablo ORDER BY deyimi kullanılarak sıralanmalıdır. Sorgu yürütmenin sonuçları Tablo'da sunulmuştur. 37.
Tablo 37
Sorgu sonucu
| şubeHayır | personelHayır | saymak |
| B00Z | SG14 | |
| B00Z | SG37 | |
| B005 | SL41 | |
| B007 | SA9 |
Bağlantılar kurmak. Birleştirme, iki tablodan alınan daha genel bir veri kombinasyonunun alt kümesidir. Kartezyen. İki tablonun Kartezyen çarpımı, her iki tablonun parçası olan olası tüm satır çiftlerinden oluşan başka bir tablodur. Ortaya çıkan tablonun sütun kümesi, ilk tablonun tüm sütunları ve ardından ikinci tablonun tüm sütunlarıdır. WHERE yan tümcesi belirtmeden iki tablo üzerinde sorgu girerseniz, SQL ortamında sorgu sonucu bu tabloların Kartezyen ürünü olacaktır. Ek olarak, ISO standardı, iki tablonun Kartezyen çarpımını hesaplamanıza izin veren SELECT deyimi için özel bir format sağlar:
SEÇ(* j sütunListesi]
tableNamel'den ÇAPRAZ BİRLEŞTİRMECayeUlte2
İstemci ve Görüntüleme tablolarının bağlantısının, müşteriNo ortak sütunu kullanılarak gerçekleştirildiği bir örneği tekrar ele alalım.İçeriği Tablo'da verilen tablolarla çalışırken. 3.6 ve 3.8'de, bu tabloların Kartezyen çarpımı 20 satıra sahip olacaktır (Müşteri tablosunun 4 satırı x görüntüleme tablosunun 5 satırı = 20 satır). Bu, Örnek 5-24'te kullanılan sorguyu yayınlamaya eşdeğerdir, ancak WHERE yan tümcesi yoktur. SELECT ifadesi kullanılarak iki tablonun birleştirilmesinin sonuçlarını içeren bir tablo oluşturma prosedürü aşağıdaki gibidir.
1. FROM yapısında belirtilen tabloların Kartezyen çarpımı oluşturulur.
2. Sorgu bir WHERE yan tümcesi içeriyorsa, arama koşullarını Kartezyen çarpım tablosunun her satırına uygulayın ve tabloda yalnızca verilen koşulları sağlayan satırları saklayın. İlişkisel cebir açısından bu işleme denir. sınırlama Kartezyen ürün.
3. Kalan her satır için, SEÇ listesinde belirtilen her bir öğenin değeri belirlenir ve sonuçta ortaya çıkan tablonun ayrı bir satırı elde edilir.
4. Orijinal sorguda SELECT DISTINCT yapısı varsa, yinelenen tüm satırlar sonuç tablosundan kaldırılır.
5. Yürütülmekte olan sorgu bir ORDER BY yan tümcesi içeriyorsa,
©2015-2019 sitesi
Tüm hakları yazarlarına aittir. Bu site yazarlık iddiasında bulunmaz, ancak ücretsiz kullanım.
Sayfa oluşturma tarihi: 2016-08-07