Jak vytvořit neuronovou síť s knihovnou Keras v Pythonu: příklad. Python a neuronové sítě
- Překlad
O čem je ten článek
Osobně se nejlépe učím s malým pracovním kódem, se kterým si mohu pohrát. V tomto tutoriálu se naučíme algoritmus zpětné šíření chyby na příkladu malé neuronové sítě implementované v Pythonu.Dejte mi kód!
X = np.array([ ,,, ]) y = np.array([]).T syn0 = 2*np.random.random((3,4)) - 1 syn1 = 2*np.random.random ((4,1)) - 1 pro j v rozsahu x(60000): l1 = 1/(1+np.exp(-(np.dot(X,syn0)))) l2 = 1/(1+np. exp(-(np.dot(l1,syn1)))) l2_delta = (y - l2)*(l2*(1-l2)) l1_delta = l2_delta.dot(syn1.T) * (l1 * (1-l1) )) syn1 += l1.T.dot(l2_delta) syn0 += X.T.dot(l1_delta)Příliš stručné? Pojďme si to rozebrat na jednodušší části.
Část 1: Malá hračka neuronová síť
Neuronová síť trénovaná pomocí zpětného šíření se snaží použít vstup k predikci výstupu.Předpokládejme, že na základě vstupních dat potřebujeme předpovědět, jak bude vypadat sloupec „výstup“. Tento problém by mohl být vyřešen výpočtem statistické korespondence mezi nimi. A viděli bychom, že levý sloupec 100% koreluje s výstupem.
Backpropagation, ve své nejjednodušší podobě, vypočítává podobné statistiky pro vytvoření modelu. Zkusme to.
Neuronová síť ve dvou vrstvách
import numpy as np # Sigmoid def nonlin(x,deriv=False): if(deriv==True): return f(x)*(1-f(x)) return 1/(1+np.exp(-x )) # sada vstupních dat X = np.array([ , , , ]) # výstupní data y = np.array([]).T # do náhodná čísla více definované np.random.seed(1) # inicializovat váhy náhodně se střední hodnotou 0 syn0 = 2*np.random.random((3,1)) - 1 pro iter v xrange(10000): # dopředné šíření l0 = X l1 = nonlin(np.dot(l0,syn0)) # jak moc se mýlíme? l1_error = y - l1 # toto vynásobte sigmoidním sklonem # na základě hodnot v l1 l1_delta = l1_error * nonlin(l1,True) # !!! # aktualizovat váhy syn0 += np.dot(l0.T,l1_delta) # !!! tisk "Výstup po tréninku:" tisk l1Výstup po tréninku: [[ 0,00966449] [ 0,00786506] [ 0,99358898] [ 0,99211957]]
Proměnné a jejich popisy.
"*" - násobení po prvcích - dva vektory stejné velikosti vynásobí odpovídající hodnoty a výstupem je vektor stejné velikosti
"-" – odečítání vektorů po prvku
x.dot(y) - pokud jsou x a y vektory, pak výstupem bude bodový součin. Pokud se jedná o matice, dostaneme násobení matic. Pokud je matice pouze jednou z nich, jedná se o násobení vektoru a matice.
- porovnejte l1 po první iteraci a po poslední
- podívejte se na funkci nonlin.
- podívejte se, jak se změní l1_error
- analyzovat řádek 36 - zde jsou shromážděny hlavní tajné přísady (označené!!!)
- analyzovat řádek 39 - celá síť se připravuje na tuto konkrétní operaci (označeno !!!)
Pojďme si kód rozebrat řádek po řádku
import numpy jako npImporty numpy, knihovna lineární algebra. Naše jediná závislost.
Def nonlin(x,deriv=False):
Naše nelinearita. Tato konkrétní funkce vytváří „esovitou kost“. Mapuje libovolné číslo na hodnotu mezi 0 a 1 a převádí čísla na pravděpodobnosti a má několik dalších užitečných vlastností pro trénování neuronových sítí.
If(deriv==True):
Tato funkce může také vrátit derivaci sigmatu (deriv=True). To je jedna z jeho užitečných vlastností. Pokud je výstupem funkce proměnná out, bude derivace mimo * (1-out). Efektivní.
X = np.array([ , ...
Inicializace pole vstupních dat jako numpy matice. Každý řádek je příkladem školení. Sloupce jsou vstupní uzly. Získáme 3 vstupní uzly v síti a 4 tréninkové příklady.
Y = np.array([]).T
Inicializuje výstup. ".T" – přenosová funkce. Po překladu má matice y 4 řádky s jedním sloupcem. Stejně jako u vstupních dat je každý řádek příkladem školení a každý sloupec (v našem případě jeden) je výstupním uzlem. Ukazuje se, že síť má 3 vstupy a 1 výstup.
np.random.seed(1)
Tím náhodné rozdělení bude pokaždé stejný. To nám umožní snadněji sledovat výkon sítě po provedení změn v kódu.
Syn0 = 2*np.random.random((3,1)) - 1
Matice váhy sítě. syn0 znamená "synapse nula". Protože máme pouze dvě vrstvy, vstupní a výstupní, potřebujeme jednu váhovou matici, která je spojí. Jeho rozměr je (3, 1), protože máme 3 vstupy a 1 výstup. Jinými slovy, l0 má velikost 3 a l1 má velikost 1. Protože spojujeme všechny uzly v l0 se všemi uzly v l1, potřebujeme matici dimenzí (3, 1).
Všimněte si, že je inicializován náhodně a průměr je nula. Za tím je poměrně složitá teorie. Zatím to budeme brát jen jako doporučení. Všimněte si také, že naše neuronová síť je právě touto matricí. Máme "vrstvy" l0 a l1, ale jsou to dočasné hodnoty založené na datové sadě. Neskladujeme je. Všechna školení jsou uložena v syn0.
Pro iter v xrange(10000):
Zde začíná hlavní síťový tréninkový kód. Cyklus s kódem se mnohokrát opakuje a optimalizuje síť pro soubor dat.
První vrstva, l0, jsou pouze data. X obsahuje 4 tréninkové příklady. Zpracujeme je všechny najednou – říká se tomu skupinový trénink. Celkem máme 4 různé struny l0, ale můžete si je představit jako jeden tréninkový příklad - v této fázi je to jedno (můžete jich načíst 1000 nebo 10000 bez jakýchkoli změn v kódu).
L1 = nonlin(np.dot(l0,syn0))
Toto je prediktivní krok. Necháme síť, aby se pokusila předpovědět výstup na základě vstupu. Pak uvidíme, jak to udělá, abychom to mohli vyladit směrem ke zlepšení.
Řádek obsahuje dva kroky. První provádí maticové násobení l0 a syn0. Druhý prochází výstup přes sigmatu. Jejich rozměry jsou následující:
(4 x 3) tečka (3 x 1) = (4 x 1)
Násobení matice vyžaduje, aby se rozměry shodovaly uprostřed rovnice. Výsledná matice má stejný počet řádků jako první a stejný počet sloupců jako druhá.
Nahráli jsme 4 tréninkové příklady a dostali 4 odhady (matice 4x1). Každý výstup odpovídá odhadu sítě pro daný vstup.
L1_error = y - l1
Protože l1 obsahuje odhady, můžeme jejich rozdíl porovnat se skutečností odečtením l1 od správné odpovědi y. l1_error je vektor kladných a záporná čísla, která charakterizuje "miss" sítě.
A tady je tajná přísada. Tento řádek je třeba analyzovat po částech.
První část: derivace
Neline(l1,True)
L1 představuje tyto tři body a kód vydává sklon čar zobrazených níže. Všimněte si, že při velkých hodnotách jako x=2,0 (zelená tečka) a velmi malých hodnotách jako x=-1,0 (fialová) mají čáry mírný sklon. Největší úhel je v bodě x=0 (modrý). Má to velká důležitost. Všimněte si také, že všechny derivace jsou mezi 0 a 1.

Úplný výraz: derivace vážená chybami
L1_delta = l1_error * nonlin(l1,True)
Matematicky je jich víc přesné způsoby, ale v našem případě je vhodný i tento. l1_error je matice (4,1). nonlin(l1,True) vrací matici (4,1). Zde je vynásobíme prvek po prvku a na výstupu dostaneme i matici (4,1), l1_delta.
Vynásobením derivací chybami snížíme chyby předpovědí provedených s vysokou spolehlivostí. Pokud byl sklon čáry malý, pak síť obsahuje buď velmi velkou nebo velmi malou hodnotu. Pokud se odhad v síti blíží nule (x=0, y=0,5), pak to není příliš jisté. Tyto nejisté předpovědi aktualizujeme a předpovědi s vysokou spolehlivostí ponecháme na pokoji tím, že je vynásobíme hodnotami blízkými nule.
Syn0 += np.dot(l0.T,l1_delta)
Jsme připraveni na upgrade sítě. Podívejme se na jeden příklad školení. V něm aktualizujeme váhy. Aktualizovat váhu nejvíce vlevo (9,5)

weight_update = vstupní_hodnota * l1_delta
Pro váhu zcela vlevo by to bylo 1,0 * l1_delta. Pravděpodobně to vzroste jen nepatrně 9,5. Proč? Protože předpověď už byla dostatečně sebevědomá a předpovědi byly prakticky správné. Malá chyba a mírný sklon čáry znamená velmi malou aktualizaci.

Ale protože provádíme skupinový trénink, opakujeme výše uvedený krok pro všechny čtyři tréninkové příklady. Vypadá to tedy velmi podobně jako na obrázku výše. Co tedy naše linka dělá? Počítá aktualizace hmotnosti pro každou váhu, pro každý příklad tréninku, sčítá je a aktualizuje všechny váhy, vše na jednom řádku.
Po sledování aktualizace sítě se vraťme k našim tréninkovým datům. Když je vstup i výstup 1, zvýšíme váhu mezi nimi. Když je vstup 1 a výstup 0, snížíme váhu.
Vstup Výstup 0 0 1 0 1 1 1 1 1 0 1 1 0 1 1 0
V našich čtyřech příkladech cvičení níže se tedy váha prvního vstupu vzhledem k výstupu bude neustále zvyšovat nebo zůstat konstantní a další dvě váhy se budou zvyšovat a snižovat v závislosti na příkladech. Tento efekt přispívá k síťovému učení založenému na korelacích vstupních a výstupních dat.
Část 2: úkol je obtížnější
Vstup Výstup 0 0 1 0 0 1 1 1 1 0 1 1 1 1 1 0Zkusme předpovědět výstupní data na základě tří vstupních sloupců dat. Žádný ze vstupních sloupců nekoreluje 100% s výstupem. Třetí sloupec nesouvisí vůbec s ničím, protože obsahuje jedničky. Zde však můžete vidět i schéma - pokud jeden z prvních dvou sloupců (ale ne oba najednou) obsahuje 1, bude výsledek také 1.
Jedná se o nelineární obvod, protože přímá shoda neexistují žádné individuální sloupce. Shoda je založena na kombinaci vstupních dat, sloupce 1 a 2.
Zajímavé je, že rozpoznávání vzorů je velmi podobný úkol. Pokud máte 100 stejně velkých obrázků jízdních kol a dýmek, přítomnost určitých pixelů na určitých místech přímo nekoreluje s přítomností jízdního kola nebo dýmky na obrázku. Statisticky se jejich barva může zdát náhodná. Některé kombinace pixelů ale nejsou náhodné – ty, které tvoří obraz jízdního kola (nebo trubky).


Strategie
Chcete-li spojit pixely do něčeho, co může mít individuální shodu s výstupem, musíte přidat další vrstvu. První vrstva kombinuje vstup, druhá přiřazuje výstup pomocí výstupu první vrstvy jako vstupu. Dávejte pozor na stůl.Vstup (l0) Skrytá závaží (l1) Výstup (l2) 0 0 1 0,1 0,2 0,5 0,2 0 0 1 1 0,2 0,6 0,7 0,1 1 1 0 1 0,3 0,2 0,3 0,9 1 2 1 0,0 1 0.0
Náhodným přiřazením vah získáme skryté hodnoty pro vrstvu #1. Zajímavé je, že druhý sloupec skrytých vah už má malou korelaci s výstupem. Není to ideální, ale existuje. A to je také důležitá součást tréninkového procesu sítě. Školení tuto korelaci jen posílí. Aktualizuje syn1, aby odpovídal výstupu, a syn0, aby lépe získal vstup.
Neuronová síť ve třech vrstvách
import numpy jako np def nonlin(x,deriv=False): if(deriv==True): return f(x)*(1-f(x)) return 1/(1+np.exp(-x)) X = np.array([, , , ]) y = np.array([, , , ]) np.random.seed(1) # náhodné váhy, průměr 0 syn0 = 2*np.random.random ((3 ,4)) - 1 syn1 = 2*np.random.random((4,1)) - 1 pro j v xrange(60000): # přejít vpřed přes vrstvy 0, 1 a 2 l0 = X l1 = nonlin(np .dot(l0,syn0)) l2 = nonlin(np.dot(l1,syn1)) # jak moc se mýlíme ohledně požadované hodnoty? l2_error = y - l2 if (j% 10000) == 0: print "Chyba:" + str(np.mean(np.abs(l2_error))) # kterým směrem se máme pohybovat? # pokud jsme si byli jistí předpovědí, tak ji nemusíme moc měnit l2_delta = l2_error*nonlin(l2,deriv=True) # jak moc ovlivňují hodnoty l1 chyby v l2? l1_error = l2_delta.dot(syn1.T) # kterým směrem se máme pohybovat, abychom se dostali na l1? # pokud jsme si byli jistí předpovědí, není třeba ji moc měnit l1_delta = l1_error * nonlin(l1,deriv=True) syn1 += l1.T.dot(l2_delta) syn0 += l0.T.dot( l1_delta)Chyba:0,496410031903 Chyba:0,00858452565325 Chyba:0,00578945986251 Chyba:0,00462917677677
Proměnné a jejich popisy
X je matice vstupní datové sady; struny - tréninkové příkladyy je matice výstupní datové sady; struny - tréninkové příklady
l0 je první vrstva sítě definovaná vstupními daty
l1 - druhá vrstva sítě nebo skrytá vrstva
l2 je poslední vrstva, to je naše hypotéza. Při procvičování byste se měli ke správné odpovědi přiblížit.
syn0 - první vrstva vah, Synapse 0, kombinuje l0 s l1.
syn1 - druhá vrstva závaží, Synapse 1, kombinuje l1 s l2.
l2_error - chyba sítě v kvantitativním vyjádření
l2_delta je chyba sítě v závislosti na jistotě předpovědi. Téměř totožné s chybou, s výjimkou silných předpovědí
l1_error - vážením l2_delta vahami ze syn1 vypočítáme chybu ve střední/skryté vrstvě
l1_delta - chyby sítě od l1, škálované podle spolehlivosti predikce. Téměř stejné jako l1_error, kromě jistých předpovědí
Kód by měl být poměrně samovysvětlující – je to jen předchozí implementace sítě, naskládaná ve dvou vrstvách, jedna na druhé. Výstup první vrstvy li je vstupem druhé vrstvy. Něco nového je až v dalším řádku.
L1_error = l2_delta.dot(syn1.T)
Použije chyby vážené spolehlivostí předpovědí z l2 k výpočtu chyby pro l1. Dostaneme, dalo by se říci, chybu váženou příspěvky - vypočítáme, jaký příspěvek k chybám v l2 mají hodnoty v uzlech l1. Tento krok se nazývá backpropagation. Poté aktualizujeme syn0 pomocí stejného algoritmu jako ve dvouvrstvé neuronové síti.
James Loy, Georgia Tech University. Průvodce pro začátečníky, po kterém si můžete vytvořit vlastní neuronovou síť v Pythonu.
Motivace: se zaměřením na osobní zkušenost při učení hlubokého učení jsem se rozhodl vytvořit neuronovou síť od nuly bez složitosti vzdělávací knihovna, jako je například . Věřím, že pro začátečníka Data Scientist je důležité porozumět vnitřní struktuře .
Tento článek obsahuje to, co jsem se naučil, a doufám, že bude užitečný i pro vás! Další užitečné související články:
Co je to neuronová síť?
Většina článků o neuronových sítích při jejich popisu kreslí paralely s mozkem. Považuji za jednodušší popsat neuronové sítě jako matematická funkce, který mapuje daný vstup na požadovaný výstup, aniž by zacházel do podrobností.
Neuronové sítě se skládají z následujících komponent:
- vstupní vrstva, x
- libovolné množství skryté vrstvy
- výstupní vrstva, ŷ
- souprava váhy A ofsety mezi každou vrstvou W A b
- výběr pro každou skrytou vrstvu σ ; v této práci použijeme funkci Sigmoid aktivace
Níže uvedený diagram ukazuje architekturu dvouvrstvé neuronové sítě (všimněte si, že vstupní úroveň obvykle vyloučeno při počítání počtu vrstev v neuronové síti).
Vytvoření třídy neuronové sítě v Pythonu vypadá jednoduše:
Trénink neuronové sítě
Výstup ŷ jednoduchá dvouvrstvá neuronová síť:
Ve výše uvedené rovnici jsou váhy W a odchylky b jediné proměnné, které ovlivňují výstup ŷ.
Správné hodnoty vah a vychýlení samozřejmě určují přesnost předpovědí. Proces doladění váhy a odchylky ze vstupu jsou známé jako .
Každá iterace procesu učení se skládá z následujících kroků
- výpočet předpokládaného výstupu ŷ, nazývaného dopředné šíření
- aktualizace vah a zkreslení, tzv
Níže uvedený sekvenční graf ilustruje proces:
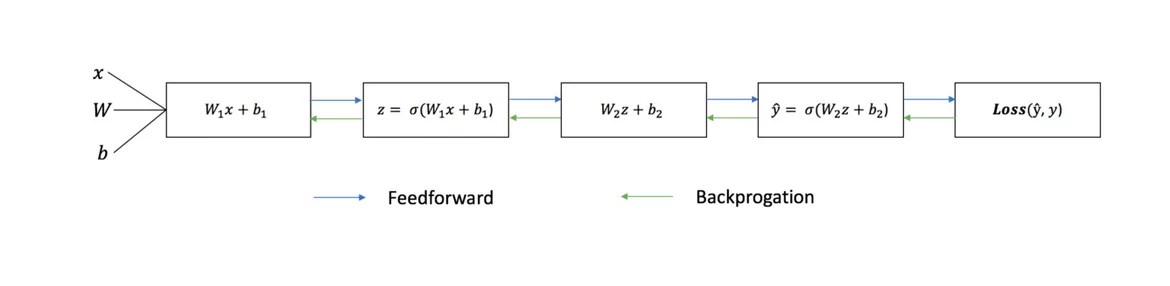
přímé šíření
Jak jsme viděli v grafu výše, dopředné šíření - je jen jednoduchý výpočet a pro základní 2vrstvou neuronovou síť je výstup neuronové sítě dán vztahem:
K tomu přidáme do našeho kódu Python funkci dopředného šíření. Všimněte si, že pro jednoduchost jsme předpokládali, že offsety jsou 0.
Potřebujeme však způsob, jak vyhodnotit „faktor kvality“ našich předpovědí, tedy jak daleko jsou naše předpovědi.) Ztrátová funkce jen nám to umožňuje.
Ztrátová funkce
K dispozici je mnoho ztrátových funkcí a povaha našeho problému by měla diktovat naši volbu ztrátové funkce. V této práci použijeme součet čtverečních chyb jako ztrátová funkce.

Součet čtverců chyb - je průměr rozdílu mezi každou předpokládanou a skutečnou hodnotou.
Cílem učení je najít soubor vah a zkreslení, který minimalizuje ztrátovou funkci.
zpětné šíření
Nyní, když jsme změřili naši chybu predikce (ztrátu), musíme najít způsob šíření chyby zpět a aktualizovat naše váhy a odchylky.
Abychom znali vhodný součet pro úpravu vah a odchylek, potřebujeme znát derivaci ztrátové funkce s ohledem na váhy a odchylky.
Připomeňte si z analýzy, že derivace funkce - je tangens směrnice funkce.

Pokud máme derivaci, můžeme jednoduše aktualizovat váhy a odchylky jejich zvýšením/snížením (viz diagram výše). To se nazývá .
Nemůžeme však přímo vypočítat derivaci ztrátové funkce s ohledem na váhy a odchylky, protože rovnice ztrátové funkce váhy a odchylky neobsahuje. Potřebujeme tedy řetězové pravidlo, které nám pomůže s výpočtem.

Fuj! Bylo to těžkopádné, ale umožnilo nám to získat to, co potřebujeme – derivaci (sklon) funkce ztráty s ohledem na váhy. Nyní můžeme podle toho upravit váhy.
Přidejme do našeho kódu Python funkci backpropagation (backpropagation):
Kontrola provozu neuronové sítě
Nyní, když máme náš kompletní Python kód pro dopředné a zpětné šíření, vezměme naši neuronovou síť jako příklad a podívejme se, jak funguje.
 Ideální sada vah
Ideální sada vah Naše neuronová síť se potřebuje naučit ideální sadu vah, aby reprezentovala tuto vlastnost.
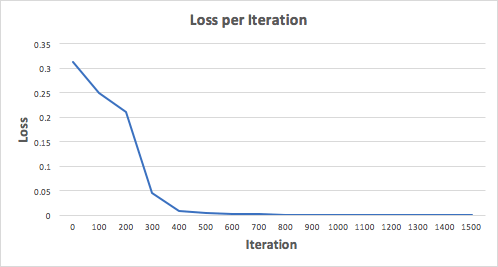
Pojďme trénovat neuronovou síť na 1500 iterací a uvidíme, co se stane. Při pohledu na iterační ztrátový graf níže jasně vidíme, že ztráta monotónně klesá na minimum. To je v souladu s algoritmem sestupu gradientu, o kterém jsme hovořili dříve.
Podívejme se na konečnou předpověď (inferenci) z neuronové sítě po 1500 iteracích.

Dokázali jsme to! Náš algoritmus dopředného a zpětného šíření ukázal úspěšnou činnost neuronové sítě a předpovědi se sbližují se skutečnými hodnotami.
Všimněte si, že mezi předpovědí a skutečnými hodnotami je nepatrný rozdíl. To je žádoucí, protože to zabraňuje nadměrnému přizpůsobení a umožňuje neuronové síti lépe zobecňovat neviditelná data.
Závěrečné myšlenky
Naučil jsem se hodně v procesu psaní vlastní neuronové sítě od nuly. I když knihovny hluboké učení, jako jsou TensorFlow a Keras, umožňují vytvoření hluboké sítě bez úplného pochopení vnitřní práce neuronové sítě, považuji za užitečné pro začínající datové vědce, aby jim porozuměli hlouběji.
Investoval jsem do toho hodně svého osobního času tato práce a doufám, že vám to bude užitečné!

Umělé neuronové sítě (ANN) - matematické modely, stejně jako jejich softwarové či hardwarové implementace, postavené na principu organizace a fungování biologických neuronové sítě- sítě nervových buněk živého organismu.ANN jsou systémem vzájemně propojených a interagujících jednoduché procesory(umělé neurony).
Neuronové sítě nejsou naprogramovány v obvyklém slova smyslu, jsou natrénované. Schopnost učit se je jednou z hlavních výhod neuronových sítí oproti tradičním algoritmům. wikipedie
Neuronové sítě byly inspirovány naším vlastním mozkem. Standardní neuronový model byl vynalezen před více než padesáti lety a skládá se ze tří hlavních částí:
- Dentrit(y) (dendrit)- zodpovědný za sběr příchozích signálů;
- soma (soma)- zodpovědný za hlavní zpracování a sčítání signálů;
- Axon (Axon)- zodpovědný za signalizaci dalším dendritům.
Práci neuronu lze popsat asi takto: dendrity sbírají signály přijaté od jiných neuronů, potom somas provádějí sumaci a výpočet signálů a dat a nakonec na základě výsledku zpracování dokážou „sdělit“ axony pro přenos signálu dále. Předávání dále závisí na řadě faktorů, ale toto chování můžeme modelovat jako přenosová funkce An, která převezme vstup, zpracuje ho a připraví výstup, pokud jsou splněny vlastnosti přenosové funkce.
biologický neuron - komplexní systém, matematický model která ještě nebyla zcela postavena. Bylo zavedeno mnoho modelů, které se liší výpočetní složitostí a podobností se skutečným neuronem. Jedním z nejdůležitějších je formální neuron (FN). Navzdory jednoduchosti FN mohou sítě postavené z takových neuronů tvořit na výstupu libovolnou vícerozměrnou funkci (zdroj: Zaentsev I.V. Neural networks: basic models).

Neuron se skládá z vážené sčítačky a nelineárního prvku. Fungování neuronu je určeno vzorcem:
Neuron má více vstupů X a jeden výstup VEN. Parametry neuronu, které určují jeho činnost, jsou: vektor vah w, prahová úroveň θ a forma aktivační funkce F.
Neuronové sítě přitahují pozornost díky následujícím vlastnostem:
- schopen řešit obtížné formalizované úkoly;
- vlastní paralelní princip práce, která je velmi důležitá při zpracování velkého množství dat;
- schopnost učit se a schopnost zobecňovat;
- tolerance chyb;
Mezi hlavní vlastnosti neuronových sítí patří:
Schopnost učit se. Neuronové sítě se neprogramují, ale trénují se na příkladech. Po předložení vstupních signálů (případně spolu s požadovanými výstupy) síť upraví své parametry tak, aby poskytovala požadovanou odezvu.
Zobecnění. Odezva sítě po trénování může být poněkud necitlivá na malé změny ve vstupních signálech. Tato inherentní schopnost „vidět" obraz prostřednictvím šumu a zkreslení je velmi důležitá pro rozpoznávání vzorů. Je důležité poznamenat, že umělá neuronová síť provádí zobecnění automaticky díky své struktuře, a nikoli pomocí „lidské inteligence" v formou speciálně napsaných počítačových programů.
Rovnoběžnost. Informace v síti jsou zpracovávány paralelně, což umožňuje provádět dostatečně komplexní zpracování dat pomocí velkého množství jednoduchých zařízení.
Vysoká spolehlivost. Síť může správně fungovat, i když některý z neuronů selže, a to díky tomu, že výpočty jsou prováděny lokálně a paralelně.
Algoritmus pro řešení problémů pomocí vícevrstvého perceptronu(zdroj: Zaentsev I. V. Neuronové sítě: základní modely)
Chcete-li sestavit vícevrstvý perceptron, musíte vybrat jeho parametry. Nejčastěji vyžaduje výběr závaží a prahů trénink, tzn. postupné změny hmotnosti a prahových úrovní.
Obecný algoritmus řešení:
- Určete, jaký význam mají složky vstupního vektoru X. Vstupní vektor musí obsahovat formalizovanou podmínku problému, tzn. všechny informace, které potřebujete k získání odpovědi.
- Vyberte výstupní vektor y tak, aby jeho součásti obsahovaly úplnou odpověď na úkol.
- Vyberte typ nelinearity v neuronech (aktivační funkce). V tomto případě je žádoucí vzít v úvahu specifika problému, protože dobrá volba zkrátí dobu tréninku.
- Vyberte počet vrstev a neuronů ve vrstvě.
- Nastavte rozsah vstupů, výstupů, váhy a prahové úrovně s ohledem na sadu hodnot zvolené aktivační funkce.
- Přiřaďte počáteční hodnoty vahám a prahům a další možnosti(například strmost aktivační funkce, pokud se bude ladit při tréninku). Počáteční hodnoty by neměly být velké, aby neurony nebyly nasyceny (na horizontální části aktivační funkce), jinak bude učení velmi pomalé. Počáteční hodnoty by neměly být příliš malé, aby se výstupy většiny neuronů nerovnaly nule, jinak se zpomalí i učení.
- Poskytnout školení, tzn. zvolte parametry sítě tak, aby byl úkol vyřešen co nejlépe. Na konci školení je síť připravena řešit problémy typu, na který byla trénována.
- Zadejte podmínky úlohy na vstup sítě ve formě vektoru X. Vypočítejte výstupní vektor y, který poskytne formalizované řešení problému.
Problémy k řešení
Problémy řešené pomocí neuronových sítí ().
Klasifikace obrázků. Úkolem je určit, zda vstupní obrázek (například řečový signál nebo ručně psaný znak) reprezentovaný příznakovým vektorem patří do jedné nebo více předdefinovaných tříd. Mezi známé aplikace patří rozpoznávání písmen, rozpoznávání řeči, klasifikace signálu elektrokardiogramu a klasifikace krevních buněk.
Shlukování/kategorizace. Při řešení problému shlukování, který je také známý jako "bez dozoru" klasifikace obrázků, neexistuje žádný trénovací vzorek s popisky tříd. Algoritmus shlukování je založen na podobnosti obrázků a umístí podobné obrázky do jednoho shluku. Clustering se používá k extrahování znalostí, komprimaci dat a zkoumání vlastností dat.
Aproximace funkcí. Předpokládejme, že máme trénovací vzorek ((x1,y1), (x2,y2)..., (xn,yn)) (vstupně-výstupní datové páry), který je generován neznámou funkcí (x) zkreslenou šumem. Problémem aproximace je najít odhad pro neznámou funkci (x). Aproximace funkcí je nezbytná pro řešení mnoha inženýrských a vědeckých modelovacích problémů.
Předpověď / Předpověď. Nechť je dáno n diskrétních vzorků (y(t1), y(t2)..., y(tn)) v po sobě jdoucích časech t1, t2,..., tn . Problém je předpovědět hodnotu y(tn+1) v nějakém budoucím čase tn+1. Predikce/prognóza má významný dopad na rozhodování v podnikání, vědě a technice. Předpověď ceny na burze a předpověď počasí jsou typické aplikace predikční/předpovědní techniky.
Optimalizace. Za optimalizační problémy lze považovat četné problémy v matematice, statistice, inženýrství, vědě, medicíně a ekonomii. Úkolem optimalizačního algoritmu je najít řešení, které vyhovuje systému omezení a maximalizuje nebo minimalizuje Objektivní funkce. NP-úplný problém obchodního cestujícího je klasickým příkladem optimalizačního problému.
Paměť adresovatelná podle obsahu. Ve von Neumannově modelu výpočtu je přístup do paměti dostupný pouze přes adresu, která je nezávislá na obsahu paměti. Pokud navíc dojde k chybě při výpočtu adresy, lze nalézt zcela jiné informace. Asociativní paměť nebo je u zadaného obsahu k dispozici obsahově adresovatelná paměť. Obsah paměti lze vyvolat i částečným zadáním nebo zkomoleným obsahem. Asociativní paměť je velmi žádoucí při vytváření multimédií informační základny data.
Řízení. Zvážit dynamický systém, daný množinou (u(t), y(t)), kde u(t) je vstupní řídicí akce a y(t) je výstup systému v čase t. V řídicích systémech s referenční model cílem řízení je vypočítat takovou vstupní akci u(t), ve které systém sleduje požadovanou trajektorii diktovanou referenčním modelem. Příkladem je optimální řízení motoru.
Typy architektur
Architektura neuronové sítě- způsob organizace a komunikace jednotlivé prvky neuronové sítě (neurony). Architektonické rozdíly samotných neuronů jsou především ve využití různých aktivačních (excitačních) funkcí. Podle architektury spojení lze neuronové sítě rozdělit do dvou tříd: sítě přímého šíření a rekurentní sítě.
Klasifikace umělých neuronových sítí podle jejich architektury je znázorněna na obrázku níže.
Podobná klasifikace, ale mírně rozšířená

Síť přímého šíření (síť přímého přenosu)- neuronová síť bez zpětná vazba(smyčky). V takové síti je zpracování informací jednosměrné: signál je přenášen z vrstvy na vrstvu ve směru od vstupní vrstvy neuronové sítě k výstupní. Výstupní signál (síťová odezva) je zaručen po předem stanoveném počtu kroků (rovném počtu vrstev). Dopředné sítě se snadno implementují a jsou dobře srozumitelné. Řešení složitých problémů vyžaduje velký počet neuronů.
srovnávací tabulka vícevrstvý perceptor A RBF sítě
| Vícevrstvý perceptron | RBF sítě |
|---|---|
| Rozhodovací hranicí je průsečík nadrovin | Hranicí rozhodování je průsečík hypersfér, který vymezuje hranici složitějšího tvaru |
| Komplexní topologie spojení mezi neurony a vrstvami | Jednoduchá dvouvrstvá neuronová síť |
| Složitý a pomalu konvergující algoritmus učení | Postup rychlého učení: řešení soustavy rovnic + shlukování |
| Práce na malém tréninkovém vzorku | Pro přijatelný výsledek vyžaduje značné množství trénovacích dat |
| Všestrannost použití: shlukování, aproximace, řízení atd. | Zpravidla pouze aproximace funkcí a shlukování |
Hodnotu derivace lze snadno vyjádřit pomocí funkce samotné. Rychlý výpočet derivace urychluje učení.
Gaussova křivka
Používá se v případech, kdy by odezva neuronu měla být maximální pro nějakou konkrétní hodnotu NET.
python moduly pro neuronové sítě
Jednoduchý příklad
Jako příklad uvedu jednoduchou neuronovou síť (simple perceptron), který po výcviku bude schopen rozpoznat létající objekty, ne všechny, ale pouze racek:), všechny ostatní vstupní obrázky budou rozpoznány jako UFO.
# encoding=utf8 import random class NN: def __init__(vlastní, práh, velikost): """ Nastavte počáteční parametry. """ self.threshold = práh self.size = velikost self.init_weight() def init_weight(self): """ Inicializujte matici vah náhodnými daty. """ vlastní.váhy = [ pro j v xrozsahu(vlastní.velikost)] def check(self, sample): """ Čtení výstupu pro vzorek obrázku. If vsum > self. práh, pak můžeme předpokládat, že vzorek má obrázek racka. """ vsum = 0 pro i v xrange(self.size): pro j v xrange(self.size): vsum += self.weights[i][ j] * sample[i][j] if vsum > self.threshold: return True else: return False def learn(self, sample): """ Trénink neuronové sítě. """ pro i v xrange(self.size) : for j in xrange(self.size): self.weights[i][j] += sample[i][j] nn = NN(20, 6) # Trénujte neuronovou síť. tsample1 = [ , , , , , , ] nn.teach(tsample1) tsample2 = [ , , , , , , ] nn.teach(tsample2) tsample3 = [ , , , , , , ] nn.teach(tsample3 =) [ , , , , , , ] nn.teach(tsample4) # Zkontrolujte, co neuronová síť umí. # Předejte obrázek racka, který je zhruba podobný tomu, o kterém ví perceptron. wsample1 = [ , , , , , , ] vytisknout u"racek", pokud nn.check(wsample1) else u"UFO" # Předat v neznámém vzoru. wsample2 = [ , , , , , , ] print u"racek" if nn.check(wsample2) else u"UFO" # Předej obrázek racka, který je zhruba podobný tomu, o kterém ví perceptron. wsample3 = [ , , , , , , ] vytisknout u"racek", pokud nn.check(wsample3) else u"UFO"
Někteří z vás pravděpodobně nedávno absolvovali kurzy na Stanfordu, zejména ai-class a ml-class. Jedna věc je však sledovat pár videopřednášek, odpovídat na kvízové otázky a napsat tucet programů v Matlabu / Octave, druhá věc je začít využití získaných znalostí v praxi. Aby znalosti získané od Andrewa Nga nespadly do stejného temného koutu mého mozku, kde se ztratily dft , Speciální teorie relativity a Euler Lagrangeova rovnice, rozhodl jsem se neopakovat chyby institutu, a dokud mám znalosti ještě čerstvé v paměti , cvičte co nejvíce.A právě tehdy DDoS přišel na naše stránky. Bylo možné se bránit tomu, které metody admin-programování (grep / awk / atd.), nebo se uchýlit k použití technologií strojového učení.
Příklad sestavení slovníku a feature-vektoru „a
Předpokládejme, že trénujeme naši neuronovou síť pouze dvěma příklady: jedním dobrým a jedním špatným. Poté se jej pokusíme aktivovat na testovacím záznamu.Záznam z "špatného" logu:
0.0.0.0 - - "POST /forum/index.php HTTP/1.1" 503 107 "http://www.mozilla-europe.org/" "-"
Záznam z "dobrého" deníku:
0.0.0.0 - - "GET /forum/rss.php?topic=347425 HTTP/1.0" 200 1685 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; pl; rv:1.9) Gecko/2008052906 Firefox/ 3,0"
Výsledný slovník:
["__UA___OS_U", "__UA_EMPTY", "__REQ___METHOD_POST", "__REQ___HTTP_VER_HTTP/1.0", "__REQ___URL___NETLOC_", "__REQ___URL___PATH_/forum/rsRE". __REQ___URL___SCHEME_", "__REQ___HTTP_VER_ http / 1.1", "__UA___VER_Firefox/3.0", "__REFER___NETLOC_www.mozilla-europe.org", "__UA___OS_Windows", "__UA___BASE_Mozilla/5.0", "__CODE_503", "__UAA_FER", "S__CHERE_TH", "S__CHERE_TH" ME_http", "__NO_REFER__" , "__REQ___METHOD_GET", "__UA___OS_Windows NT 5.1", "__UA___OS_rv:1.9", "__REQ___URL___QS_topic", "__UA___VER_Gecko/2008052906"]
Testovací záznam:
0.0.0.0 - - "GET /forum/viewtopic.php?t=425550 HTTP/1.1" 502 107 "-" "BTWebClient/3000(25824)"
Jeho rys-vektor:
Všimněte si, jak "řídký" je feature-vector - toto chování bude pozorováno u všech požadavků.
Rozdělení datové sady
Je dobrým zvykem rozdělit datovou sadu "a" na několik částí. Rozdělil jsem ji na dvě části v poměru 70/30:- tréninkový set. Trénujeme na něm naši neuronovou síť.
- testovací sada. Pomocí něj kontrolujeme, jak dobře je naše neuronová síť natrénovaná.
Pokud si v budoucnu budete muset lámat hlavu nad výběrem optimálních konstant, bude potřeba datovou sadu rozdělit na 3 části v poměru 60/20/20: Tréninková sada , Testovací sada a Křížová validace . Poslední bude sloužit jako výběr optimální parametry neuronové sítě (například váhový úpadek).
Zejména neuronové sítě
Nyní, když již nemáme po ruce žádné textové protokoly, ale pouze matice prvků a vektorů, můžeme začít budovat samotnou neuronovou síť.Začněme výběrem struktury. Vybral jsem síť z jedné skryté vrstvy, která je dvakrát větší než vstupní vrstva. Proč? Je to jednoduché: toto odkázal Andrew Ng v případě, že nevíte, kde začít. Myslím, že v budoucnu si s tím můžete pohrát tím, že si nakreslíte tréninkové plány.
Jako aktivační funkce pro skrytou vrstvu je zvolen únavný sigmoid a pro výstupní vrstvu je zvolen Softmax. To druhé je vybráno v případě, že to musíte udělat
vícetřídní klasifikace se vzájemně se vylučujícími třídami. Například posílejte „dobré“ požadavky na backend, „špatné“ požadavky – na zákaz firewallu a „šedé“ požadavky – pro vyřešení captcha.
Neuronová síť má tendenci jít na lokální minimum, takže ve svém kódu sestavím několik sítí a vyberu si tu s nejmenší testovací chybou (Poznámka, je to chyba na testovací sadě, ne na cvičné sadě).
Zřeknutí se odpovědnosti
Nejsem opravdový svářeč. O strojovém učení vím jen to, co jsem získal z ml-class a ai-class. Začal jsem programovat v pythonu relativně nedávno a níže uvedený kód byl napsán za 30 minut (čas, jak chápete, utíkal) a později byl jen mírně uložen.Tento kód také není soběstačný. Stále potřebuje scénář. Pokud například IP odešle N špatných požadavků během X minut, zakažte ji na firewallu.
Výkon
- lfu_cache. Portováno z ActiveState, aby se výrazně urychlilo zpracování „vysokofrekvenčních“ požadavků. Nevýhoda – zvýšená spotřeba paměti.
- PyBrain je náhle napsán v pythonu, a proto není příliš rychlý, může však používat modul arac založený na ATLASu, pokud je při vytváření sítě zadáno Fast=True. Více si o tom můžete přečíst v dokumentaci PyBrain.
- Paralelizace. Svou neuronovou síť jsem trénoval na poměrně "tlustém" serveru Nehalem, ale i tam jsem cítil nevýhodu jednovláknového tréninku. Můžete přemýšlet o paralelizaci tréninku neuronové sítě. Jednoduchým řešením je natrénovat několik neuronových sítí v paralelní a vybrat si z nich tu nejlepší, ale tím dojde k dodatečnému zatížení paměti, což také není příliš dobré. řešení na jednom místě. Možná má smysl vše jednoduše přepsat do C, protože celý teoretický základ ve třídě ml byl sežvýkaný.
- Spotřeba paměti a počet funkcí. Dobrou optimalizací paměti byl přechod ze standardních Pythonových polí na numpy. Také zmenšení velikosti slovníku a/nebo použití PCA může hodně pomoci, více o tom níže.
Pro budoucnost
- Další pole v protokolu. Do kombinovaného protokolu můžete přidat mnohem více, měli byste přemýšlet o tom, která pole pomohou při identifikaci robotů. Možná má smysl vzít v úvahu první oktet IP adresy, protože v nemezinárodním webovém projektu jsou čínští uživatelé s největší pravděpodobností boti.
Neuronové sítě jsou vytvářeny a trénovány především na jazyk Python. Proto je velmi důležité mít základní znalosti o tom, jak na něm psát programy. V tomto článku budu stručně a jasně mluvit o základních pojmech tohoto jazyka: proměnné, funkce, třídy a moduly.
Materiál je určen lidem, kteří se nevyznají v programovacích jazycích.
Nejprve musíte nainstalovat Python. Pak je potřeba nastavit pohodlné prostředí pro psaní programů v Pythonu. Tyto dva kroky jsou věnovány portálu.
Pokud je vše nainstalováno a nakonfigurováno, můžete začít.
Proměnné
Variabilní- klíčový pojem v jakémkoli programovacím jazyce (a nejen v nich). Nejjednodušší je představit si proměnnou jako krabici s popiskem. Tato krabice obsahuje něco (číslo, matici, předmět, ...), co má pro nás hodnotu.
Řekněme například, že chceme vytvořit proměnnou x, která by měla uchovávat hodnotu 10. V Pythonu by kód pro vytvoření této proměnné vypadal takto:

Vlevo my oznámit proměnná s názvem x. To odpovídá skutečnosti, že jsme na krabici nalepili osobní štítek. Následuje rovnítko a číslo 10. Rovnítko zde hraje neobvyklou roli. Neznamená to "x je 10". Rovnost v tento případ vloží do rámečku číslo 10. Přesněji řečeno my přiřadit proměnná x číslo 10.
Nyní v kódu níže můžeme přistupovat k této proměnné a provádět s ní různé akce.
Hodnotu této proměnné můžete jednoduše zobrazit na obrazovce:
X=10 tisk (x)
Nápis print(x) je volání funkce. Budeme je dále zvažovat. Nyní je důležité, že tato funkce vytiskne do konzole to, co se nachází mezi závorkami. Mezi závorkami máme x. Dříve jsme x přiřadili hodnotu 10. To je přesně 10, která se zobrazí v konzole, pokud spustíte program výše.
S proměnnými, které ukládají čísla, můžete provádět různé jednoduché operace: sčítat, odečítat, násobit, dělit a zvyšovat na mocninu.
X = 2 y = 3 # Sečti z = x + y tisk(z) # 5 # Rozdíl z = x - y tisk(z) # -1 # Produkt z = x * y tisk(z) # 6 # Rozděl z = x / y print(z) # 0,66666... # Umocnění z = x ** y print(z) # 8
Ve výše uvedeném kódu nejprve vytvoříme dvě proměnné obsahující 2 a 3. Poté vytvoříme proměnnou z, která uloží výsledek operace na x a y a vytiskne výsledky do konzole. Tento příklad jasně ukazuje, že proměnná může během provádění programu změnit svou hodnotu. Naše proměnná z tedy změní svou hodnotu až 5krát.
Funkce
Někdy je nutné provést stejné akce mnohokrát. Například v našem projektu často potřebujeme zobrazit 5 řádků textu.
"Toto je velmi důležitý text!"
"Tento text nelze přečíst"
"Chyba v horním řádku byla provedena záměrně"
"Dobrý den a na shledanou"
"Konec"
Náš kód bude vypadat takto:
X = 10 y = x + 8 - 2 print("Toto je velmi důležitý text!") print("Tento text se nesmí číst") print("Úmyslně byla chyba v horním řádku") print( "Ahoj a nazdar") print ("Konec") z = x + y print("Toto je velmi důležitý text!") print("Tento text nelze přečíst") print("V horním řádku došlo k chybě schválně") print("Ahoj a nazdar") print ("Konec") test = z print("Toto je velmi důležitý text!") print("Tento text nelze přečíst") print("Chyba v horní řádek byl vytvořen záměrně") print("Ahoj a sbohem") print(" Konec")
Všechno to vypadá velmi nadbytečně a nepohodlně. Ve druhém řádku je také chyba. Dá se to opravit, ale bude to muset být opraveno na třech místech najednou. A pokud je v našem projektu těchto pět řádků voláno 1000krát? A všechno uvnitř různá místa a soubory?
Zejména pro případy, kdy je nutné často provádět stejné příkazy, mohou programovací jazyky vytvářet funkce.
Funkce- samostatný blok kódu, který lze volat jménem.
Funkce je definována pomocí klíčového slova def. Následuje název funkce, za ním závorky a dvojtečka. Dále, odsazeno, musíte vypsat akce, které budou provedeny při volání funkce.
Def print_5_lines(): print("Toto je velmi důležitý text!") print("Tento text nelze přečíst") print("Horní řádek byl záměrně špatně") print("Ahoj a nashle") print(" Konec")
Nyní jsme definovali funkci print_5_lines(). Nyní, pokud v našem projektu znovu potřebujeme vložit pět řádků, pak jednoduše zavoláme naši funkci. Automaticky provede všechny akce.
# Definujte funkci def print_5_lines(): print("Toto je velmi důležitý text!") print("Tento text nelze přečíst") print("Chyba v horním řádku byla provedena záměrně") print("Ahoj and bye") print(" End") # Kód našeho projektu x = 10 y = x + 8 - 2 print_5_lines() z = x + y print_5_lines() test = z print_5_lines()
Pohodlné, že? Výrazně jsme zlepšili čitelnost kódu. Kromě toho jsou funkce také dobré, protože pokud chcete změnit některé akce, pak stačí vyladit samotnou funkci. Tato změna bude fungovat na všech místech, kde se volá vaše funkce. To znamená, že můžeme opravit chybu na druhém řádku výstupního textu („nepovoleno“ > „nepovoleno“) v těle funkce. Správná varianta bude automaticky vyvolána na všech místech našeho projektu.

Funkce s parametry
Jen opakování několika kroků je samozřejmě pohodlné. Ale to není vše. Někdy chceme naší funkci předat nějakou proměnnou. Funkce tedy může přijímat data a používat je v procesu provádění příkazů.
Volají se proměnné, které funkci předáme argumenty.
Pojďme psát jednoduchá funkce, který sečte dvě čísla a vrátí výsledek.
Def sum(a, b): výsledek = a + b vrátí výsledek
První řádek vypadá téměř stejně jako běžné funkce. Ale mezi závorkami jsou nyní dvě proměnné. Tento možnosti funkcí. Naše funkce má dva parametry (to znamená, že potřebuje dvě proměnné).
Parametry lze použít uvnitř funkce stejně jako běžné proměnné. Na druhém řádku vytvoříme proměnnou result , která se rovná součtu parametrů a a b . Na třetím řádku vrátíme hodnotu výsledné proměnné.
Nyní v dalším kódu můžeme napsat něco jako:
Nový = součet(2, 3) tisk (nový)
Zavoláme funkci součtu a předáme jí postupně dva argumenty: 2 a 3. 2 se stane hodnotou proměnné a a 3 se stane hodnotou proměnné b . Naše funkce vrátí hodnotu (součet 2 a 3) a použijeme ji k vytvoření nové proměnné new .
Pamatovat si. Ve výše uvedeném kódu jsou čísla 2 a 3 argumenty součtové funkce. A v samotné součtové funkci jsou proměnné a a b parametry. Jinými slovy, proměnné, které předáme funkci při jejím volání, se nazývají argumenty. Ale uvnitř funkce se tyto předané proměnné nazývají parametry. Ve skutečnosti se jedná o dva názvy pro stejnou věc, ale neměli byste je zaměňovat.
Zvažme ještě jeden příklad. Vytvořme funkci square(a), která vezme jedno číslo a odmocní ho:
Def square(a): vrátí a * a
Naše funkce se skládá pouze z jednoho řádku. Okamžitě vrátí výsledek vynásobení parametru a a .
Myslím, že jste již uhodli, že také produkujeme výstup dat do konzole pomocí funkce. Tato funkce se nazývá print() a vypíše argument, který jí byl předán do konzole: číslo, řetězec, proměnná.
Pole
Pokud lze proměnnou chápat jako krabici, která obsahuje něco (ne nutně číslo), pak pole lze považovat za regály. Obsahují několik proměnných najednou. Zde je příklad pole tří čísel a jednoho řetězce:
pole=
Zde je příklad, kdy proměnná neobsahuje číslo, do nějakého jiného objektu. V tomto případě naše proměnná obsahuje pole. Každý prvek pole je očíslován. Zkusme zobrazit nějaký prvek pole:
Pole = tisk (pole)
V konzoli uvidíte číslo 89. Ale proč 89 a ne 1? Jde o to, že v Pythonu, stejně jako v mnoha jiných programovacích jazycích, číslování polí začíná od 0. Proto nám pole dává druhý prvek pole, nikoli první. Chcete-li zavolat první, museli jste napsat array .
Velikost pole
Někdy je velmi užitečné získat počet prvků v poli. K tomu můžete použít funkci len(). Automaticky spočítá počet prvků a vrátí jejich počet.
Pole = tisk(délka(pole))
Na konzole se zobrazí číslo 4.
Podmínky a cykly
Ve výchozím nastavení všechny programy jednoduše provádějí všechny příkazy shora dolů v řadě. Jsou ale situace, kdy potřebujeme zkontrolovat nějakou podmínku a podle toho, zda je pravdivá nebo ne, provést různé akce.
Navíc je často nutné opakovat téměř stejnou sekvenci příkazů mnohokrát.
V první situaci pomáhají podmínky a ve druhé cykly.
Podmínky
Podmínky jsou potřebné k provedení dvou různých sad akcí v závislosti na tom, zda je testované tvrzení pravdivé nebo nepravdivé.

V Pythonu lze podmínky zapsat pomocí konstrukce if: ... else: .... Řekněme, že máme nějakou proměnnou x = 10 . Pokud je x menší než 10, pak chceme x vydělit 2. Pokud je x větší nebo rovno 10, pak chceme vytvořit další proměnnou new , která se rovná součtu x a čísla 100. Kód by vypadal takto:
X = 10 if(x< 10): x = x / 2 print(x) else: new = x + 100 print(new)
Po vytvoření proměnné x začneme psát naši podmínku.
Vše začíná klíčovým slovem if (přeloženo z angličtiny „if“). V závorce uvedeme výraz ke kontrole. V tomto případě kontrolujeme, zda je naše proměnná x opravdu menší než 10. Pokud je skutečně menší než 10, pak ji vydělíme 2 a výsledek vytiskneme do konzole.
Pak přijde klíčové slovo else , po kterém začíná blok akcí, které budou provedeny, pokud je výraz v závorkách za if nepravdivý.
Pokud je větší nebo rovna 10, pak vytvoříme novou proměnnou new , která se rovná x + 100 a také ji vytiskneme do konzole.
Cykly
Smyčky se používají k opakování akcí znovu a znovu. Předpokládejme, že chceme zobrazit tabulku druhých mocnin prvních 10 přirozených čísel. Dá se to udělat takto.
Print("Čtverec 1 je " + str(1**2)) print("Čtverec 2 je " + str(2**2)) print("Čtverec 3 je " + str(3**2)) print( "Čtverec 4 je " + str(4**2)) print("Čtverec 5 je " + str(5**2)) print("Čtverec 6 je " + str(6**2)) print("Čtverec 7 je " + str(7**2)) print("Čtverec 8 je " + str(8**2)) print("Čtverec 9 je " + str(9**2)) print("Čtverec 10 je " + str(10**2))
Nedivte se tomu, že přidáváme provázky. "začátek řetězce" + "konec" v Pythonu jednoduše znamená zřetězení řetězců: "začátek řetězce". Stejným způsobem výše přidáme řetězec „Čtverec x se rovná“ a výsledek zvýšení čísla na 2. mocninu převedeme pomocí funkce str (x ** 2).
Výše uvedený kód vypadá velmi nadbytečně. Co když ale potřebujeme vytisknout druhé mocniny prvních 100 čísel? Jsme mučeni stáhnout se...
K tomu slouží cykly. V Pythonu existují 2 typy smyček: while a for . Pojďme se s nimi postupně vypořádat.
Cyklus while opakuje potřebné příkazy, dokud podmínka zůstává pravdivá.
X = 1, zatímco x<= 100: print("Квадрат числа " + str(x) + " равен " + str(x**2)) x = x + 1
Nejprve vytvoříme proměnnou a přiřadíme jí číslo 1. Poté vytvoříme while cyklus a zkontrolujeme, zda je naše x menší než (nebo rovno) 100. Pokud je menší než (nebo rovno), provedeme dvě akce:
- Odvodíme čtverec x
- Zvýšit x o 1
Po druhém příkazu se program vrátí do podmínky. Pokud je podmínka opět pravdivá, provedeme tyto dvě akce znovu. A tak dále, dokud se x nestane rovno 101. Pak podmínka vrátí hodnotu false a smyčka se již nebude provádět.
Smyčka for je navržena tak, aby iterovala přes pole. Napišme stejný příklad s druhými mocninami prvních sta přirozených čísel, ale přes cyklus for.
Pro x v rozsahu (1 101): print("Čtverec " + str(x) + " je " + str(x**2))
Pojďme analyzovat první řádek. K vytvoření smyčky používáme klíčové slovo for. Dále označíme, že chceme opakovat určité akce pro všechna x v rozsahu od 1 do 100. Funkce range(1,101) vytvoří pole 100 čísel, počínaje 1 a končící 100.
Zde je další příklad iterace přes pole pomocí cyklu for:
Pro i v: tisk (i * 2)
Kód výše zobrazuje 4 číslice: 2, 20, 200 a 2000. Zde můžete jasně vidět, jak bere každý prvek pole a provádí sadu akcí. Poté vezme další prvek a zopakuje stejnou sadu akcí. A tak dále, dokud nedojdou prvky v poli.
Třídy a objekty
V reálném životě neoperujeme s proměnnými nebo funkcemi, ale s objekty. Pero, auto, muž, kočka, pes, letadlo - objekty. Nyní se pojďme podívat na kočku podrobně.
Má to nějaké možnosti. Patří mezi ně barva srsti, barva očí, její přezdívka. Ale to není vše. Kromě parametrů může kočka provádět různé akce: předení, syčení a škrábání.
Právě jsme popsali schematicky všechny kočky obecně. Podobný popis vlastností a akcí nějaký objekt (například kočka) v jazyce Python a nazývá se třída. Třída je jednoduše sbírka proměnných a funkcí, které popisují nějaký druh objektu.
Je důležité pochopit rozdíl mezi třídou a objektem. třída - systém A, které popisuje objekt. Předmětem je ona materiálové provedení. Třída kočky je popis jejích vlastností a akcí. Kočičí objekt je samotná kočka. Může existovat mnoho různých skutečných koček - mnoho kočičích předmětů. Ale existuje jen jedna třída koček. Níže uvedený obrázek je dobrou ukázkou:

Třídy
Chcete-li vytvořit třídu (schéma naší kočky), musíme napsat klíčové slovo class a poté zadat název této třídy:
třídní kočka:
Dále musíme vyjmenovat akce této třídy (akce kočky). Akce, jak jste možná uhodli, jsou funkce definované v rámci třídy. Takové funkce v rámci třídy se nazývají metody.
Metoda- funkce definovaná v rámci třídy.
Slovně jsme již výše popsali kočičí metody: vrnění, syčení, škrábání. Udělejme to nyní v Pythonu.
# Třída třídy kočky Kočka: # Předení def předení(sebe): print("Purrr!") # Syčení def syčení(sebe): print("Kshh!") # Poškrábání def scrabble(self): print("Scratch-scratch !")
Je to tak jednoduché! Vzali jsme a definovali tři běžné funkce, ale pouze uvnitř třídy.
Abychom se vypořádali s nepochopitelným parametrem self, dodejme naší kočce ještě jednu metodu. Tato metoda zavolá všechny tři již vytvořené metody najednou.
# Třída třídy kočky Kočka: # Předení def předení(sebe): print("Purrr!") # Syčení def syčení(sebe): print("Kshh!") # Poškrábání def scrabble(self): print("Scratch-scratch !") # Vše dohromady def all_in_one(self): self.purr() self.hiss() self.scrabble()
Jak vidíte, parametr self, který je povinný pro jakoukoli metodu, nám umožňuje přístup k metodám a proměnným samotné třídy! Bez tohoto argumentu bychom takové akce nemohli provádět.
Pojďme si nyní nastavit vlastnosti naší kočky (barva srsti, barva očí, přezdívka). Jak to udělat? V absolutně jakékoli třídě můžete definovat funkci __init__(). Tato funkce je volána vždy, když vytváříme skutečný objekt naší třídy.
V metodě __init__() zvýrazněné výše jsme nastavili proměnné naší kočky. jak to uděláme? Nejprve této metodě předáme 3 argumenty, které jsou zodpovědné za barvu srsti, barvu očí a přezdívku. Pak použijeme parametr self, abychom při vytváření objektu okamžitě nastavili naší kočce 3 výše popsané atributy.
Co tento řádek znamená?
Vlastní.barva_vlny = barva_vlny
Na levé straně vytvoříme atribut pro naši kočku nazvaný wool_color a pak tento atribut nastavíme na hodnotu obsaženou v parametru wool_color, který jsme předali funkci __init__() . Jak vidíte, řádek výše se neliší od obvyklého vytváření proměnné. Pouze předpona self označuje, že tato proměnná patří do třídy Cat.
Atribut- proměnná, která patří do nějaké třídy.
Takže jsme vytvořili hotovou třídu koček. Zde je jeho kód:
# Třída třídy Cat Cat: # Akce, které je třeba provést při vytváření objektu Cat def __init__(self, wool_color, eyes_color, name): self.wool_color = wool_color self.eyes_color = eyes_color self.name = name # Purr def purr( self): print("Purrr!") # Scrabble def syč(self): print("Psst!") # Scrabble def scrabble(self): print("Scratch-scratch!") # Vše dohromady def all_in_one(self) : self. předení() self.syčení() self.scrabble()
Objekty
Vytvořili jsme schéma kočky. Nyní vytvořte skutečný kočičí objekt podle tohoto schématu:
My_cat = Cat("černá", "zelená", "Zosya")
Ve výše uvedeném řádku vytvoříme proměnnou my_cat a poté k ní přiřadíme objekt třídy Cat. Celé to vypadá jako volání nějaké funkce Cat(...) . Ve skutečnosti je. Tímto záznamem zavoláme metodu __init__() třídy Cat. Funkce __init__() v naší třídě přebírá 4 argumenty: samotný objekt třídy self, který není třeba specifikovat, a dále 3 další různé argumenty, které se pak stávají atributy naší kočky.
S pomocí výše uvedeného řádku jsme tedy vytvořili skutečný kočičí objekt. Naše kočka má tyto atributy: černé vlasy, zelené oči a přezdívku Zosya. Vytiskneme tyto atributy do konzole:
Tisk(moje_kocka.barva_vlny) tisk(moje_kocka.barva_oci) tisk(moje_kocka.jmeno)
To znamená, že můžeme odkazovat na atributy objektu napsáním názvu objektu, uvedením tečky a zadáním názvu požadovaného atributu.
Atributy kočky lze změnit. Změňme například jméno naší kočky:
My_cat.name = "Nyusha"
Nyní, pokud znovu vytisknete jméno kočky do konzole, místo Zosie uvidíte Nyusha.
Dovolte mi připomenout, že třída naší kočky jí umožňuje provádět některé akce. Když pohladíme naši Zosyu / Nyushu, začne vrnět:
My_cat.purr()
Po provedení tohoto příkazu se na konzole zobrazí text „Murrr!“. Jak vidíte, přístup k metodám objektu je stejně snadný jako přístup k jeho atributům.
Moduly
Každý soubor s příponou .py je modul. I ten, ve kterém pracujete na tomto článku. K čemu jsou potřeba? Pro pohodlí. Mnoho lidí vytváří soubory s užitečnými funkcemi a třídami. Ostatní programátoři zahrnují tyto moduly třetích stran a mohou využívat všechny funkce a třídy v nich definované, čímž si zjednodušují práci.
Například pro práci s maticemi nemusíte trávit čas psaním vlastních funkcí. Stačí zahrnout modul numpy a používat jeho funkce a třídy.
Dosud jiní programátoři Pythonu napsali přes 110 000 různých modulů. Výše zmíněný numpy modul umožňuje rychle a pohodlně pracovat s maticemi a vícerozměrnými poli. Matematický modul poskytuje mnoho metod pro práci s čísly: sinus, kosinus, převod stupňů na radiány a tak dále a tak dále...
Instalace modulu
Python se instaluje spolu se standardní sadou modulů. Tato sada obsahuje velmi velké množství modulů, které umožňují pracovat s matematikou, webovými dotazy, číst a zapisovat soubory a provádět další potřebné akce.
Pokud chcete použít modul, který není součástí standardní sady, budete jej muset nainstalovat. Chcete-li nainstalovat modul, otevřete příkazový řádek (Win + R, do zobrazeného pole zadejte "cmd") a zadejte do něj příkaz:
Instalace Pip [název_modulu]
Začne proces instalace modulu. Po dokončení můžete bezpečně používat nainstalovaný modul ve vašem programu.
Připojení a používání modulu
Modul třetí strany se připojuje velmi jednoduše. Stačí napsat jeden krátký řádek kódu:
Importovat [název_modulu]
Chcete-li například importovat modul, který vám umožní pracovat s matematickými funkcemi, musíte napsat následující:
importovat matematiku
Jak získat přístup k funkci modulu? Musíte napsat název modulu, poté vložit tečku a napsat název funkce / třídy. Například faktoriál 10 se nachází takto:
Math.factorial(10)
To znamená, že jsme se obrátili na funkci faktoriál(a), která je definována uvnitř matematického modulu. To je výhodné, protože nemusíme ztrácet čas a ručně vytvářet funkci, která vypočítá faktoriál čísla. Modul můžete připojit a okamžitě provést potřebnou akci.