Program pro rozpoznávání naskenovaných obrázků. Nejlepší bezplatný software pro skenování a OCR
Software OCR umožňuje převádět vyfotografované nebo naskenované dokumenty přímo na věty.
Faktem je, že text na obrázku je prezentován jako rastr, sada bodů.
Zmíněný software převede sadu bodů do plnohodnotného textu, dostupného pro editaci a uložení.
Rozpoznávání písmen je navrženo tak, aby optimalizovalo proces digitalizace papírových tištěných nebo ručně psaných knih a dokumentů.
Tento způsob digitalizace je řádově rychlejší než rychlost ručního psaní z obrázku. Je široce používán při digitalizaci knihoven a archivů.
ABBYY Fine Reader 10
FineReader je nesporným lídrem mezi všemi programy, které rozpoznávají text na obrázku. Konkrétně neexistuje žádný software, který by azbuku zpracoval přehledněji.
FineReader má obecně 179 jazyků, jejichž text je rozpoznán mimořádně úspěšně.
Jediná okolnost, která může uživatele zklamat, je, že program je placený.
Pouze bezplatná distribuce zkušební verze po dobu 15 dnů. Během této doby je povoleno skenování 50 stran.
Zdroj je zcela irelevantní. Ať už se jedná o fotografii, sken stránky nebo jakýkoli obrázek s písmeny.
výhody:
- přesné rozpoznávání;
- obrovské množství jazyků čtení;
- tolerance ke kvalitě zdrojového obrazu.
Chyba:
- zkušební verze na 15 dní.
OCR CuneiForm

Bezplatný program pro čtení textových informací z obrázků. Přesnost rozpoznávání je o řád nižší než u předchozího uvažovaného programu.
Ale jak pro bezplatný nástroj, funkčnost je stále na vrcholu.
Program umí číst a ukládat písmo a velikost rozpoznaného textu. Databáze obsahuje většinu používaných druhů písma.
Podporuje dokonce rozpoznávání textu na psacím stroji.
Pro zajištění přesnosti jsou na proces rozpoznávání napojeny speciální slovníky, které doplňují slovní zásobu z naskenovaných dokumentů.
výhody:
- bezplatná distribuce;
- používání slovníků ke kontrole správnosti textu;
- skenování textu z fotokopií Špatná kvalita.
nedostatky:
- relativně nízká přesnost;
- Ne velký počet podporované jazyky.
WinScan2PDF

Nejedná se ani o plnohodnotný program, ale o utilitu. Instalace není nutná a spustitelný soubor váží jen několik kilobajtů.
Proces rozpoznávání je extrémně rychlý, nicméně výsledné dokumenty se ukládají výhradně ve formátu PDF.
Ve skutečnosti se celý proces provádí stisknutím tří tlačítek: výběrem zdroje, cíle a vlastně spuštěním programu.
Nástroj je navržen pro rychlé dávkové zpracování více souborů. Pro pohodlí uživatelů velký jazykový balíček rozhraní.
výhody:
- přenosnost;
- rychlá práce;
- snadnost použití.
nedostatky:
Problém je v tom, že ruština není zahrnuta ani v jazykovém balíčku rozhraní, ani v seznamu jazyků podporovaných pro rozpoznávání.
Pokud však chcete skenovat angličtinu, dánštinu nebo francouzštinu, pak nejlépe možnost zdarma nelze najít.
Ve svém oboru program poskytuje přesné dekódování písem, odstranění šumu a extrakci grafického obrazu.
Rozhraní programu je navíc vestavěné, téměř totožné s WordPadem, což značně zvyšuje použitelnost programu.
výhody:
- přesné rozpoznávání textu;
- pohodlný textový editor;
- odstranění šumu z obrazu.
nedostatky:
- úplná absence ruského jazyka.
Pravděpodobně každý zná situaci, kdy je třeba převést sken dokumentu, například stránky knihy, do tištěného textu. Pro toto existují speciální programy, ale většina z nich je velmi málo známá. Snad jen na slyšení všech ABBYY FineReader. FineReader skutečně nemá konkurenci. Toto je nejlepší program pro skenování a OCR v ruštině, ale je vydáván výhradně v placené verze a je dost drahý. Kolik z nich je připraveno zaplatit téměř 7 000 rublů za nejlevnější licenci, pokud budou zpracovávat jednu nebo dvě knihy ročně?
Pokud uvažujete o koupi drahé komerční produkt neodůvodněné, proč nepoužít analogy, mezi nimiž jsou bezplatné? Ano, nejsou tak bohaté na funkce, ale docela úspěšně si poradí s mnoha úkoly, na které je podle mnohých „příliš těžký“ pouze FineReader. Pojďme se tedy podívat na několik dostupných alternativ. A zároveň se podívejme, jak se liší od obecně uznávaného standardu.
Chcete-li porovnat jiné programy s ABBYY FineReader, pojďme zjistit, proč je tak dobrý. Zde je seznam jeho hlavních funkcí:
- Práce s fotografiemi, skeny a papírovými dokumenty.
- Úprava obsahu pdf souborů - text, jednotlivé bloky, interaktivní prvky a další.
- Převést pdf do formátu Microsoft slovo a naopak. Vytvářejte soubory PDF z libovolných textových dokumentů.
- Porovnejte obsah dokumentů ve 35 jazycích, jako je naskenovaný papír a elektronický (ne ve všech vydáních).
- Rozpoznávání a převod naskenovaných textů, tabulek, matematických vzorců.
- Automatické provádění rutinních operací (ne ve všech edicích).
- Podpora pro 192 národních abeced.
- Zkontrolujte pravopis rozpoznaného textu v ruštině, ukrajinštině a 46 dalších jazycích.
- Podpora 10 grafických a 10 textových vstupních formátů souborů, nepočítaje pdf.
- Ukládání souborů v grafické a textové formáty, stejně jako e-knihy EPUB a FB2.
- Čtení čárových kódů.
- Rozhraní ve 20 jazycích, včetně ruštiny a ukrajinštiny.
- Většinová podpora stávající modely skenery.

Možnosti programu jsou skvělé, ale pro domácí uživatele, kteří nezpracovávají dokumenty v průmyslových objemech, jsou nadbytečné. Pro ty, kteří potřebují rozpoznat jen několik stránek, však společnost ABBYY poskytuje služby zdarma – prostřednictvím webové služby FineReaderOnline. Po registraci je k dispozici zpracování 10 stran naskenovaného nebo nafoceného textu, v budoucnu - 5 stran měsíčně. Více - za poplatek.
Cena nejlevnější licence FineReader pro instalaci do počítače je 6990 rublů (standardní verze).
Malý a extrémně jednoduchý bezplatný nástroj samozřejmě nemůže konkurovat monstru, ale řeší hlavní úkol - rozpoznání naskenovaného textu, jak má být. Navíc k tomu ani nevyžaduje instalaci na PC (přenosný). A ovládá se pouze třemi tlačítky.

Pro rozpoznání textu pomocí WinScan2PDF klikněte na "Vybrat zdroj" a vyberte připojený skener (program bohužel nepracuje s hotovými soubory). Vložte dokument do skeneru a klikněte na "Skenovat". Pokud chcete operaci zrušit, klikněte na Storno. To jsou všechny pokyny.
Nástroj podporuje 23 jazyků včetně ruštiny a pracuje s vícestránkovými soubory. Hotový výsledek je uložen ve formátu pdf, naskenovaný dokument je uložen ve formátu jpg.
Webová služba Free-OCR.com

Free-OCR.com (OCR - Optické rozpoznávání znaků, optické rozpoznávání znaků) je bezplatná internetová služba pro rozpoznávání naskenovaných nebo vyfotografovaných textů uložených v grafickém obrazovém formátu (jpg, gif, tiff, bmp) nebo pdf. Podporuje 29 jazyků, včetně ruštiny a ukrajinštiny, a uživatel si může vybrat ne jeden, ale několik, pokud je zdrojový text obsahuje.
Free-OCR nevyžaduje registraci a nemá žádná omezení počtu nahraných dokumentů. Omezená je pouze velikost souboru – do 6 Mb. Služba nezpracovává vícestránkové dokumenty, přesněji vše kromě prvního listu ignoruje.
Rychlost rozpoznávání naskenovaného textu je poměrně vysoká. List A4 s fragmentem knihy v ruštině byl zpracován asi za 5 sekund, ale kvalita nepotěšila. Velká písma- stejně jako v dětských knihách rozpozná 100% a střední a malé - asi 80%. S anglicky psanými dokumenty je to o něco lepší – malé a málo kontrastní písmo bylo správně rozpoznáno asi z 95 %.
Bezplatná online webová služba OCR

- další bezplatná webová služba, velmi podobná předchozí, ale s rozšířenou funkčností. On:
- Podporuje 106 jazyků.
- Procesy vícestránkové dokumenty, včetně několika jazyků.
- Rozpoznává texty na skenech a fotografických dokumentech mnoha typů. Kromě 10 grafických obrazových formátů zpracovává pdf, djvu, doxc, odt, zip archivy A komprimované soubory Unix.
- Ukládá výstupní soubory v jednom ze 3 formátů: txt, doc a pdf.
- Podporuje rozpoznávání matematické rovnice.
- Umožňuje otočit obraz o 90-180° v obou směrech.
- Správně rozpozná text ve více sloupcích na stejné stránce.
- Dokáže rozpoznat jeden vybraný fragment.
- Po zpracování nabízí zkopírování souboru do schránky, stažení do počítače, nahrání do služby Google dokumenty nebo publikovat online. K dispozici je také možnost okamžitě přeložit text do jiného jazyka pomocí Google Translate nebo Bing Translator.
Free Online OCR musíme pochválit za to, že docela dobře čte obrázky s nízkým rozlišením a nízkým kontrastem. Výsledek uznání všech ruskojazyčných textů, které mu byly podávány, odmítl být 100% nebo se mu blížit.
Online OCR zdarma je podle našeho názoru jedním z nich nejlepší alternativy FineReader, ale zdarma zpracuje pouze 20 stránek (není však uvedeno za jaké období). Další využití služby stojí od 0,5 USD za stránku.
Microsoft OneNote
Program Microsoft OneNote na psaní poznámek, s výjimkou velmi staré a nejnovější verze 17, také obsahuje funkci OCR. Není tak pokročilý jako ve specializovaných aplikacích, ale stále použitelný, pokud nejsou jiné možnosti.
Chcete-li rozpoznat text z obrázku pomocí pomocí OneNotu, vložte obrázek do souboru („Obrázek“ - „Vložit“), klikněte na něj pravým tlačítkem a vyberte „Kopírovat text z obrázku“.
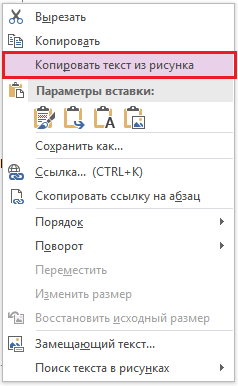
Poté vložte zkopírovaný text kamkoli do poznámky.
Výchozí jazyk rozpoznávání je angličtina. Pokud potřebujete ruštinu nebo jinou, změňte nastavení ručně.
Kvalita rozpoznávání textu v ruském jazyce v Microsoft OneNote ponechává mnoho přání, takže ji nelze nazvat plnohodnotnou náhradou za FineReader. Ano a je velmi nepohodlné v něm zpracovávat velké vícestránkové dokumenty.
simpleocr

Starý bezplatný program SimpleOCR je také velmi slušný nástroj rozpoznávání textu z elektronických obrázků a skenů, ale bohužel bez podpory ruského jazyka. Má však jedinečnou funkci čtení ručně psaných slov a také editor, který vám umožní opravit chyby před uložením hotového výsledku.
Další funkce SimpleOCR:
- Kontrola pravopisu s možností ručního doplňování slovníku.
- Čtení dokumentů v nízkém rozlišení a se skvrnami (je zde možnost vyčistit "šum").
- Nejbližší výběr písma a převod stylů psaní (tučné, kurzíva). Pokud chcete, můžete tuto funkci zakázat.
- Současné zpracování několika listů nebo jednoho fragmentu.
- Výběr možné chyby v hotovém textu pro ruční úpravu.
- Podpora mnoha modifikací skenerů.
- Vstupní formáty elektronických dokumentů: tif, jpg, bmp, inkoust i skeny.
- Uložení hotového textu do txt formáty a doc.
Kvalita rozpoznávání tištěných textů i rukopisů je poměrně vysoká.
Program by se dal nazvat univerzální, nebýt omezené jazykové podpory. Nejnovější verze podporuje pouze angličtinu, francouzštinu a dánštinu, pravděpodobně nebude přidána. Rozhraní je kompletně v angličtině, ale snadno pochopitelné. V hlavním okně je navíc tlačítko „Demo“, které spustí výukové video o práci se SimpleOCR.
Program belgického vývojáře I.R.I.S je skutečně skutečnou konkurencí ruského ABBYY FineReaderu. Výkonný, rychlý, multiplatformní, založený na proprietárním OCR enginu používaném výrobci Adobe, HP a Canon, dokonale rozpoznává i ty nejobtížněji čitelné texty. Podporuje 137 jazyků, včetně ruštiny a ukrajinštiny.
Vlastnosti a funkce aplikace Readiris:
- Nejvíc vysoká rychlost zpracování souborů mezi aplikacemi této třídy, určenými pro velké objemy.
- Zachování formátování zdrojového textu (fonty, velikost, styl psaní).
- Single a dávkové zpracování soubory, podpora vícestránkových dokumentů.
- Rozpoznávání matematických rovnic, speciální znaky a čárové kódy.
- Očištění textu od "šumu" - čar, skvrn atd.
- Integrace s různými cloudové služby- Dokumenty Google, Evernote, Dropbox, SharePoint a některé další.
- Podpora pro všechny moderní modely skenery.
- Vstupní datové formáty: pdf, djvu, jpg, png a další, do kterých se uloží grafické obrázky, stejně jako přijaté přímo ze skeneru.
- Výstupní formáty dat: doc, docx, xls, xlsx, txt, rtf, html, csv, pdf. Podporuje konverzi na djvu.
Rozhraní programu je ruské, použití je intuitivní. Neposkytuje uživatelům možnost upravovat obsah souborů PDF, jako je FineReader, ale podle našeho názoru odvádí vynikající práci s hlavním úkolem - rozpoznáváním textu.
Readiris je k dispozici ve dvou placených verzích. Cena Pro licence je € 99,00, Firemní je € 199. Skoro jako ABBYY.
Freemore OCR

Freemore OCR - (! webové stránky programu http://freemoresoft.com/freeocr/index.php může být blokován antiviry kvůli reklamnímu „smetí“ zabudovanému v instalátoru) je další jednoduchá, kompaktní a bezplatná utilita, která také dobře rozpoznává texty, ale standardně pouze v angličtině. Ostatní jazykové balíčky je nutné stáhnout a nainstalovat samostatně.
Další vlastnosti a funkce Freemore OCR:
- Současná práce s několika skenery.
- Podpora mnoha formátů grafických dat, včetně proprietárních, jako je psd ( soubor Adobe photoshop). Podporovány jsou všechny standardní grafické formáty.
- Podpora PDF.
- Uložení hotového výsledku ve formátu pdf, txt nebo docx a pro export textu do Wordu stačí kliknout na jedno tlačítko na panelu nástrojů.
- Vestavěný editor (program bohužel neuloží formátování původního dokumentu).
- Zobrazit vlastnosti dokumentu.
- Tisk rozpoznaného textu přímo z hlavního okna.
- Ochrana souborů pdf heslem.
Rozhraní programu se na první pohled může zdát složité, ale ve skutečnosti je velmi snadné. Nástroje jsou rozděleny do skupin jako na pásu karet Microsoft Office. Když se na ně podíváte blíže, rychle vám bude jasný účel konkrétního tlačítka.
Pro načtení elektronického dokumentu do okna Freemore OCR nejprve vyberte jeho typ – obrázek nebo pdf soubor a poté stiskněte příslušné tlačítko „Načíst“. Proces rozpoznávání spustíte kliknutím na tlačítko „OCR“ ve stejnojmenné skupině nástrojů vedle obrázku Kouzelná hůlka(zobrazeno na snímku obrazovky).
Výsledek skenování anglických textů z dobře čitelných i špatně čitelných obrázků dopadl vcelku uspokojivě. Jediná věc, která se mi nelíbila, bylo, že spolu s programem jsou na počítači nainstalovány všechny druhy odpadu - některé falešné antivirové skenery, optimalizátory a další nepotřebné věci a bez možnosti je odmítnout při instalaci. Jedním slovem, nebýt tohoto nedostatku, lze aplikaci doporučit jako dobrou bezplatnou alternativu k FineReaderu.
Potřeba pracovat s textem prezentovaným ve formě grafických souborů se objevuje poměrně často. Ať už se jedná o obrázek, naskenovaný dokument nebo fotokopii, ruční zadávání informací v nich uvedených může trvat poměrně dlouho.
přehled programu
Pro tento účel existuje mnoho programů. Abyste s nimi mohli začít pracovat, stačí mít obrázek nebo naskenovaný dokument, který je potřeba převést na text. Většina z nich je si svými funkcemi podobná, ale zároveň mají unikátní nástroje vhodné pro konkrétní účely. Jak se neztratit v jejich rozmanitosti a které stojí za pozornost? Budeme to dále zvažovat.
CuneiForm
První program, na který se zaměříme, je CuneiForm. Toto je bezplatný software od společnosti Cognitive Technologies. Jeho hlavním účelem je optické rozpoznání textů prezentovaných ve formuláři elektronické kopie nebo obrázky. Rychle převede grafický soubor na text, se kterým lze pracovat v jakékoli kancelářské aplikaci.

Hlavní rysy programu:

Freemore OCR
Freemore OCR je ve svých funkcích podobný. Jedná se o jednoduchý a volně dostupný program, který dokáže extrahovat text z obrázků v různé formáty a PDF dokumenty. Po dokončení skenování lze výsledek uložit do souboru, který se otevře v programu Poznámkový blok nebo Word.
Freemore OCR je:

Poznámka! Práce podobných aplikací s dokumenty v ve formátu PDF může kvůli velkému množství zdrojového materiálu trvat déle než u běžného grafického souboru.
freeocr
FreeOCR je další šikovná aplikace pro optické rozpoznávání textu. Má intuitivní rozhraní a obsahuje sadu všech potřebných nástrojů k tomu. Stojí za zmínku, že nabídka programu je zapnutá anglický jazyk, ale díky neobvyklému přístupu k jeho designu je každému uživateli jasný. Nástroj podporuje práci s různými obrázky v různých formátech a soubory PDF.

Funkce FreeOCR:
- schopnost převádět obrázky ve všech populárních formátech;
- absence standardní menu, místo toho jsou uživateli nabídnuty velké ikony znázorňující požadovanou akci;
- minimalistické rozhraní, ve kterém je uloženo jen to nejnutnější;
- podpora rozpoznávání mnoha jazyků, včetně ruštiny;
- nízké systémové požadavky.
Důležité! K instalaci FreeOCR je vyžadováno připojení k internetu. Po spuštění programu v automatický režim aktualizuje svou databázi a stáhne chybějící slovníky z online úložiště. Pokud během provozu narazí na neznámé znaky nebo jazyky, může FreeOCR také navrhnout aktualizaci.
Video: rozpoznání textu z obrázku
simpleocr
SimpleOCR je podobný program pro OCR po skenování. Je skvělá pro práci s cizími jazyky, protože má velkou a neustále se zlepšující slovní zásobu. Kromě standardní sady funkcí má možnost vyhledání slova nebo kombinace v přijatém textu a pokročilé možnosti formátování. Dobře se hodí pro zpracování velkých textů.
Charakteristické rysy SimpleOCR:

RiDoc
RiDoc je aplikace, jejíž hlavní funkcí je pracovat s naskenovanými kopiemi dokumentů a převádět je na prostý text. Vše je v ní připraveno ke skenování – stačí připojit tiskárnu a začít pracovat, načež program začne zpracovávat vybrané soubory.

Navíc umožňuje zmenšit velikost dokumentu bez ztráty kvality zdrojového materiálu. Vlastnosti RiDoc:
- velká sada nástrojů pro práci s tiskárnami, podpora pro nejoblíbenější modely;
- schopnost sloučit několik dokumentů do jednoho souboru, upravovat je a uspořádat;
- vytvoření galerie, ve které jsou uloženy všechny získané výsledky;
- export do MS Word, PDF a grafických souborů;
- odeslání výsledku e-mailem přímo z rozhraní aplikace;
- vytváření vodoznaků, které chrání výsledek;
- rychlost a pohodlí.
img2txt
img2txt- standardní aplikace, transformace různé druhy grafické soubory do textového materiálu. Program podporuje většinu známých formátů, snadno se používá a je volně dostupný.
Hlavní funkce a vlastnosti:
- převod obrázků v různých formátech na textové soubory;
- rozpoznávání skenů dokumentů a fragmentů textu v obrázcích;
- extrémně jednoduché menu obsahující dostatečnou sadu nástrojů;
- uložení výsledku v různých formátech;
- distribuce zdarma.
Poznámka! img2txt má stejně jako další podobné aplikace svou online verzi, na jejímž vývoji a vylepšování nyní jeho tvůrci zaměřili svou pozornost.
SunnyPage
SunnyPage je šikovný nástroj, který vám umožní nahrávat a převádět různé typy obrázků, ať už se jedná o naskenovanou kopii dokumentu, obrázek nebo fotografii v dobrá kvalita. Podporuje také PDF dokumenty. Program obsahuje rozsáhlý slovník a automatické rozpoznávání jazyka.

SunnyPage navíc:
- podporuje načítání dalších slovníků a ruční přidávání nových slov a frází;
- pracuje s velkými objemy s možností uložit je do jednoho souboru;
- má sadu funkcí pro úpravu obrázků, automatické ladění jejich jas a zbavení se vad;
- "čte" většinu známých formátů;
- umožňuje uložit výsledek do souboru Word;
- má vícejazyčné rozhraní.
Abbyy Finereader pro skenování a OCR
ABBYY FineReader je zaslouženě nejlepší OCR software svého druhu. Jeho popularita je způsobena přítomností všech potřebných funkcí, které uživatel v takových aplikacích hledá. Je plně kompatibilní s Microsoft Office, což umožňuje začít pracovat s dokumentem ihned po ukončení procesu převodu.
Co umí ABBYY FineReader?

Capture2Text
Capture2Text je přenosná aplikace se širokou škálou funkcí pro práci s dokumenty. Jeho charakteristický rys je možnost pořídit snímek obrazovky nebo jeho část a uložit jej jako obrázek. Poté se můžete pustit do práce a přenést přijaté informace do dokumentu tradičních formátů.
Capture2Text nevyžaduje instalaci a lze jej spustit z flash disku. Díky tomu je použitelný v mnoha oblastech a prostě nepostradatelný pro ty, kteří potřebují mít vždy po ruce jednoduchý a výkonný měnič.

Capture2Text má mnoho zajímavých funkcí:
- standardní převod obrázků (obrázků, skenů, fotokopií) do dokumentů aplikace Word;
- rozpoznávání řeči (včetně ruštiny) a hlasové vytáčení;
- schopnost přiřadit horké klávesy;
- zachycení textu z plochy nebo její části a následné zpracování.
Google dokumenty
Kromě všech výše uvedených nástrojů je v Dokumentech Google přítomna funkce OCR. Tato služba podporuje soubory JPG, PNG a GIF i vícestránkové dokumenty PDF. Zdrojem mohou být obrázky získané pomocí skenerů, ale i běžné fotografie.

Je třeba poznamenat, že při použití tuto službu v důsledku toho není vždy zachováno původní formátování. Některé struktury, jako jsou seznamy, sloupce a poznámky pod čarou, mohou být ztraceny.
To je do značné míry ovlivněno kvalitou stahovaného obsahu grafický soubor. Přijaté dokumenty lze uložit do služba Google Disk, poté stažen do počítače nebo odeslán e-mailem.
Každý z uvažovaných programů má dostatečné nástroje, aby splnil svůj původní účel – převod souborů různé formáty do textových dokumentů. Liší se však svou sestavou další funkce, rozhraní a podporované jazyky. Pro práci byste si měli vybrat aplikaci (nebo několik), která vyhovuje vašim potřebám a je schopna co nejpřesněji se s úkolem vyrovnat.
>Setkali jste se s tím, že potřebujete něco naskenovat, například nějaké dokumenty? Ať už se jedná o textové materiály nebo jen fotografie, program RiDoc je ideální pro běžné „uživatele“, protože. má jednoduché, praktické a velmi přátelské rozhraní.
Ridoc je software pro skenování dokumentů, který umožňuje digitalizovat informace, tedy přenášet informace z papíru do digitální ( HDD počítač), čímž se zjednoduší život uživatele a šetří les. Tyto dokumenty lze navíc odeslat prostřednictvím E-mailem nebo nahrát do cloudové úložiště, udělte přístup dalším uživatelům (v závislosti na úkolu).
RiDoc navíc poskytuje funkce, které mohou upravit velikost digitálního dokumentu (výběr kvality obrazu). Rozhraní má nástroj, který umožňuje rozpoznat text ze skeneru (textové informace) a také uchovávat historii všech dříve naskenovaných dokumentů (například ve formátu pdf).
Aplikace umožňuje ukládat digitální možnosti dokumenty v nejběžnějších formátech: bmp, tiff, jpeg, png, Word, PDF, což je velmi pohodlné, protože většina z nich má software pro práci s těmito soubory uživatelé počítačů odpovídající aplikace lze navíc vždy zdarma stáhnout z našeho portálu.

Nejčastěji se RiDoc používá jako programy pro skenování z hp a canon zařízení kvůli skutečnosti, že poslední jmenované jsou pro většinu uživatelů extrémně oblíbené. To ale v žádném případě neznamená, že ostatní výrobci zůstávají stranou – RiDoc dokonale spolupracuje s jakýmkoliv cenově dostupný model skener, takže si můžete bezpečně stáhnout tento bezplatný program pro skenování dokumentů v ruštině.
Hlavní funkce softwaru:
- Existuje technologie rychlé složky“, které vám umožní pohodlně spravovat digitalizované dokumenty;
- Pokud máte papírový textový dokument, který chcete přenést do počítače, pak je program schopen provést rozpoznání textu, který lze později upravit v libovolném oblíbeném textový editor, například v OpenOffice popř Microsoft Word;
- Funkce vodoznaku. Uživateli je dána příležitost upravit jeho velikost, po upřesnění průhlednosti;
- Všechny naskenované (digitalizované) PDF dokumenty lze umístit do jednoho souboru, pro kompaktnější uložení, možnost nastavit společné parametry pro každou jednotlivou funkci.
- K dispozici je vestavěná tiskárna RiDoc, která vám umožní exportovat soubory do formátu PDF;
- Všechny naskenované soubory lze přirozeně odeslat k tisku;

Tento software doporučujeme jako nepostradatelnou aplikaci, která bude užitečná jak pro studenty, tak pro studenty jednoduchý uživatel, a stane se také nepostradatelným nástrojem pro kancelářského pracovníka. Pro stažení programu stačí kliknout na příslušné tlačítko v dolní části článku.
Dobré odpoledne.
Pravděpodobně každý z nás čelil úkolu přeložit papírový dokument do elektronické podobě. To je zvláště často nutné pro ty, kteří studují, pracují s dokumentací, překládají texty pomocí elektronických slovníků atd.
Ne každý hned pochopí jednu věc. Po naskenování (vložení všech listů na skener) budete mít obrázky ve formátu BMP, JPG, PNG, GIF (mohou být i jiné formáty). Z tohoto obrázku je tedy třeba získat text – tento postup se nazývá rozpoznávání. V tomto pořadí bude prezentace níže.
1. Co potřebujete pro skenování a rozpoznávání?
1) Skener
K překladu tištěných dokumentů do textové zobrazení, nejprve potřebujete skener a podle toho i „nativní“ programy a ovladače, které jsou s ním dodané. S jejich pomocí bude možné dokument naskenovat a uložit pro další zpracování.
Můžete použít i jiné analogy, ale software dodaný se skenerem v sadě obvykle funguje rychleji a má více možností.
V závislosti na tom, jaký typ skeneru máte, se rychlost práce může výrazně lišit. Existují skenery, které dokážou získat obrázek z listu za 10 sekund, jsou takové, které jej přijmou za 30 sekund. Pokud naskenujete knihu o 200-300 listech – myslím, že není těžké spočítat, kolikrát tam bude časový rozdíl?
2) Program pro rozpoznávání
V našem článku vám ukážu práci v jednom z nejlepší programy pro skenování a rozpoznávání naprosto jakýchkoli dokumentů - ABBYY FineReader. Protože program je placený, pak hned dám odkaz na jiný - jeho bezplatný analog. Pravda, nesrovnával bych je, jelikož FineReader vítězí ve všech ohledech, přesto doporučuji vyzkoušet.
ABBYY FineReader 11
Jeden z nejlepších programů svého druhu. Je navržen tak, aby rozpoznával text v obrázku. Mnoho vestavěných možností a funkcí. Dokáže analyzovat spoustu písem, dokonce podporuje ručně psané varianty (ačkoli jsem to osobně nezkoušel, myslím, že je nepravděpodobné, že by ručně psanou verzi dobře poznal, pokud nemáte dokonalý kaligrafický rukopis). Více podrobností o práci s ním bude popsáno níže. Zde poznamenáváme, že článek bude hovořit o práci v programu verze 11.
Obvykle, různé verze ABBYY FineReader se od sebe příliš neliší. Totéž můžete snadno udělat v jiném. Hlavní rozdíly mohou být v pohodlí, rychlosti programu a jeho možnostech. Například více rané verze odmítnout otevřít PDF dokument a DJVU...
3) Dokumenty ke skenování
Ano, je to tak, rozhodl jsem se dát dokumenty do samostatného sloupce. Ve většině případů se skenují některé učebnice, noviny, články, časopisy atd. ty knihy a literaturu, která je žádaná. K čemu jdu? Z osobní zkušenosti mohu říci, že mnoho z toho, co chcete skenovat, je pravděpodobně již na netu! Kolikrát jsem já osobně ušetřil čas, když jsem našel tu či onu knihu již naskenovanou na netu. Stačilo jen zkopírovat text do dokumentu a dále s ním pracovat.
Z této jednoduché rady - než něco naskenujete, zkontrolujte, zda již někdo skenoval a nemusíte ztrácet čas.
2. Možnosti skenování textu
Zde nebudu mluvit o vašich ovladačích pro skener, o programech, které s ním byly dodány, protože všechny modely skenerů jsou jiné, software je také všude jiný a hádat, natož jasně ukázat, jak operaci provést, je nereálné.
Všechny skenery ale mají stejné nastavení, které může výrazně ovlivnit rychlost a kvalitu vaší práce. Pojďme si o nich zde promluvit. Uvedu v pořadí.
1) Kvalita skenování - DPI
Nejprve nastavte kvalitu skenování v možnostech alespoň na 300 DPI. Je vhodné dokonce více exponovat, pokud je to možné. Čím vyšší je DPI, tím jasnější bude váš obrázek, a proto bude další zpracování rychlejší. Navíc, čím vyšší je kvalita skenování, tím méně chyb budete muset později opravovat.
Nejlepší volba obvykle poskytuje 300-400 DPI.
2) Chroma
Tento parametr výrazně ovlivňuje dobu skenování (mimochodem ovlivňuje i DPI, ale ty jsou tak silné a pouze když uživatel nastaví vysoké hodnoty).
Obvykle existují tři režimy:
Černá a bílá (skvělé pro prostý text);
Šedá (vhodná pro text s tabulkami a obrázky);
Barva (pro barevné časopisy, knihy, obecně dokumenty, kde je důležitá barva).
Doba skenování obvykle závisí na volbě barvy. Koneckonců, pokud je váš dokument velký, pak i dalších 5-10 sekund na stránce jako celku bude mít za následek slušný čas ...
3) Fotky
Dokument získáte nejen naskenováním, ale také vyfotografováním. V tomto případě budete mít zpravidla jiné problémy: zkreslení obrazu, rozmazání. Z tohoto důvodu může být zapotřebí delší další úprava a zpracování přijatého textu. Osobně nedoporučuji pro tento obchod používat fotoaparáty.
Je důležité si uvědomit, že ne každý takový dokument lze rozpoznat, protože. kvalita skenování může být extrémně nízká…
3. Rozpoznávání textu dokumentu
Po otevření obrázku v ABBYY FineReader program zpravidla automaticky začne vybírat oblasti a rozpoznávat je. Ale někdy to dělá špatně. Za tímto účelem zvážíme výběr požadovaných oblastí ručně.
Důležité! Ne každý hned pochopí, že po otevření dokumentu v programu se vlevo v okně, ve kterém vybíráte různé oblasti, zobrazí původní dokument. Po kliknutí na tlačítko „rozpoznat“ vám program v okně vpravo zobrazí hotový text. Po rozpoznání je mimochodem vhodné zkontrolovat text na chyby ve stejném FineReaderu.
3.1 Text
Tato oblast se používá ke zvýraznění textu. Obrázky a tabulky by z něj měly být vyloučeny. Vzácná a neobvyklá písma budou muset být zadána ručně...
Chcete-li zvýraznit textovou oblast, věnujte pozornost liště v horní části FineReaderu. Je zde tlačítko "T" (viz obrázek níže, ukazatel myši je právě na tomto tlačítku). Klikněte na něj a poté na obrázku níže vyberte úhledně obdélníkovou oblast, ve které se text nachází. Mimochodem, v některých případech musíte vytvořit textové bloky 2-3 a někdy 10-12 na stránku, protože. formátování textu může být různé a jeden obdélník nemůže vybrat celou oblast.
Je důležité si uvědomit, že obrázky by neměly spadat do textové oblasti! To vám později ušetří spoustu času...
3.2 Obrázky
Používá se ke zvýraznění obrázků a těch oblastí, které jsou obtížně rozpoznatelné kvůli špatné kvalitě nebo neobvyklému písmu.
Na níže uvedeném snímku obrazovky je ukazatel myši na tlačítku používaném k výběru oblasti „obrázku“. Mimochodem, v této oblasti lze vybrat naprosto jakoukoli část stránky a FineReader ji pak vloží do dokumentu jako běžný obrázek. Tito. jen "hloupě" kopírovat...
Obvykle se tato oblast používá ke zvýraznění špatně naskenovaných tabulek, ke zvýraznění nestandardního textu a fontů, samozřejmě obrázků.
3.3 Tabulky
Snímek obrazovky níže ukazuje tlačítko pro výběr tabulek. Vlastně to osobně používám jen zřídka. Faktem je, že budete muset celkem běžně kreslit (vlastně) každou čáru na stole a ukazovat, co a jak do programu. Pokud je stůl malý a není v příliš dobré kvalitě, doporučuji k tomuto účelu využít plochu "obrázek". Ušetříte tak spoustu času a pak můžete rychle vytvořit tabulku ve Wordu na základě obrázku.
3.4 Nepotřebné prvky
Je důležité poznamenat. Někdy jsou na stránce zbytečné prvky, které překážejí v rozpoznání textu, nebo vůbec neumožňují vybrat požadovanou oblast. Pomocí "gumy" je lze zcela odstranit.
Chcete-li to provést, přejděte do režimu úpravy obrázků.
Vyberte nástroj guma a vyberte nechtěnou oblast. Bude vymazán a na jeho místě bude bílý list papíru.
Mimochodem, doporučuji tuto možnost využívat co nejčastěji. Vyzkoušejte všechny textové oblasti, které jste vybrali, kde nepotřebujete kus textu, nebo jsou tam nějaké zbytečné tečky, rozmazání, deformace – smažte gumou. Díky tomu bude rozpoznávání rychlejší!
4. Rozpoznávání souborů PDF/DJVU
Obecně se tento formát rozpoznávání nebude nijak lišit od ostatních - tzn. Dá se s tím pracovat stejně jako s obrázky. Jediná věc je, že program by neměl být příliš stará verze, pokud soubory PDF/DJVU nelze otevřít, aktualizujte verzi na 11.
Malá rada. Po otevření dokumentu ve FineReaderu – automaticky začne dokument rozpoznávat. V souborech PDF/DJVU často není v celém dokumentu určitá oblast stránky potřeba! Chcete-li odstranit takovou oblast na všech stránkách, postupujte takto:
1. Přejděte do sekce pro úpravy obrázků.
2. Zapněte možnost „oříznout“.
3. Zvýrazněte požadovanou oblast na všech stránkách.
4. Klepněte na tlačítko použít na všechny stránky a ořízněte.
5. Zkontrolujte chyby a uložte výsledky práce
Zdálo by se, jaké další problémy by mohly nastat, když byly všechny oblasti vybrány a poté rozpoznány - vezměte to a uložte ... Nebylo to tam!
Nejprve musíte zkontrolovat dokument!
Chcete-li to povolit, po rozpoznání bude v okně vpravo tlačítko „kontrola“, viz snímek obrazovky níže. Po jeho stisknutí Software FineReader automaticky vám ukáže ty oblasti, kde měl program chyby a nemohl spolehlivě určit konkrétní znak. Budete si muset pouze vybrat, buď souhlasíte s názorem programu, nebo zadáte svou postavu.
Mimochodem, zhruba v polovině případů, přibližně, vám program nabídne hotové správné slovo – budete muset pouze vybrat požadovanou možnost myší.

Za druhé, po kontrole je třeba zvolit formát, ve kterém uložíte výsledek své práce.
Zde vám FineReader umožňuje otočit se na maximum: můžete jednoduše přenášet informace do Wordu jeden na jednoho nebo je můžete uložit v jednom z desítek formátů. Rád bych ale upozornil na další důležitý aspekt. Ať už zvolíte jakýkoli formát, důležitější je vybrat typ kopie! Zvažte nejzajímavější možnosti ...
Přesná kopie
Všechny oblasti, které jste vybrali na stránce v rozpoznaném dokumentu, budou přesně odpovídat zdrojovému dokumentu. Velmi pohodlná možnost když vám záleží na tom, abyste neztratili formátování textu. Mimochodem, fonty budou také velmi podobné originálu. Při této možnosti doporučuji přenést dokument do Wordu, abyste tam mohli pokračovat v další práci.
Upravitelná kopie
Tato možnost je dobrá, protože získáte již naformátovanou verzi textu. Tito. odrážky s "kilometrem", který mohl být v původním dokumentu - nenajdete. Užitečná možnost když informace výrazně upravíte.
Je pravda, že byste si neměli vybírat, zda je pro vás důležité zachovat styl designu, písma, odsazení. Někdy, pokud rozpoznání nebylo příliš úspěšné, může se váš dokument kvůli změněnému formátování „zkosit“. V tomto případě je vhodné zvolit přesnou kopii.
Prostý text
Možnost pro ty, kteří potřebují pouze text ze stránky bez všeho ostatního. Vhodné pro dokumenty bez obrázků a tabulek.
Tento článek o skenování a rozpoznávání dokumentu skončil. Doufám, že s těmito jednoduché tipy můžete svůj problém vyřešit...