Standardní regresní analýza ve STATISTICA. Regresní statistika
Předpokládá se, že - nezávislé proměnné (prediktory, vysvětlující proměnné) ovlivňují hodnoty - závislých proměnných (odpovědi, vysvětlující proměnné). Podle dostupných empirických dat je potřeba sestrojit funkci, která by přibližně popisovala změnu při změně:
.
Předpokládá se, že množina přípustných funkcí, ze kterých se vybírá, je parametrická:
 ,
,
kde je neznámý parametr (obecně řečeno vícerozměrný). Při konstrukci to budeme předpokládat
 , (1)
, (1)
kde první člen je pravidelná změna z a druhý je náhodná složka s nulovým průměrem; je podmíněné očekávání za známé podmínky a nazývá se regrese na .
Nechat n krát se měří hodnoty faktorů a odpovídající hodnoty proměnné y; předpokládá se, že
(2)
(druhý index X odkazuje na číslo faktoru a první odkazuje na číslo pozorování); také se předpokládá, že
 (3)
(3)
těch. jsou nekorelované náhodné proměnné. Vztahy (2) se pohodlně zapisují v maticové formě:
, (4)
Kde  - sloupcový vektor hodnot závislých proměnných, t- transpoziční symbol,
- sloupcový vektor hodnot závislých proměnných, t- transpoziční symbol,  - sloupcový vektor (rozměry k) neznámé regresní koeficienty, - vektor náhodných odchylek,
- sloupcový vektor (rozměry k) neznámé regresní koeficienty, - vektor náhodných odchylek,

-matice ; PROTI i-tý řádek obsahuje hodnoty nezávislých proměnných v i pozorování, první proměnná je konstanta rovna 1.
na začátek
Odhad regresních koeficientů
Sestrojme odhad pro vektor tak, aby se vektor odhadů závislé proměnné minimálně lišil (ve smyslu druhé mocniny normy rozdílu) od vektoru daných hodnot:
.
Řešením je (pokud je hodnost matice k+1) školní známka
 (5)
(5)
Je snadné zkontrolovat, zda je nezaujatý.
na začátek
Kontrola adekvátnosti sestrojeného regresního modelu
Mezi hodnotou , hodnotou z regresního modelu a hodnotou triviálního odhadu výběrového průměru existuje následující vztah:
 ,
,
kde .
Termín na levé straně v zásadě definuje celkovou chybu průměru. První výraz na pravé straně () definuje chybu spojenou s regresním modelem a druhý () chybu spojenou s náhodnými odchylkami a nevysvětleným sestaveným modelem.
Rozdělením obou částí na plnou variaci hráčů  , získáme koeficient determinace:
, získáme koeficient determinace:
 (6)
(6)
Koeficient ukazuje kvalitu přizpůsobení regresního modelu pozorovaným hodnotám. Jestliže , pak regrese na nezlepší kvalitu predikce ve srovnání s triviální predikcí.
Druhý extrémní případ znamená přesnou shodu: všechny , tj. všechny pozorovací body leží v regresní rovině.
Hodnota však roste s nárůstem počtu proměnných (regresorů) v regresi, což neznamená zlepšení kvality predikce, a proto se zavádí upravený koeficient determinace
 (7)
(7)
Jeho použití je správnější pro porovnávání regresí při změně počtu proměnných (regresorů).
Intervaly spolehlivosti pro regresní koeficienty. Směrodatná chyba odhadu je hodnota, pro kterou je odhad
 (8)
(8)
kde je diagonální prvek matice Z. Pokud jsou chyby normálně rozloženy, pak díky vlastnostem 1) a 2) výše, statistika
 (9)
(9)
rozdělené podle Studentova zákona se stupni volnosti, a tedy nerovností
, (10)
kde je kvantil úrovně tohoto rozdělení, udává interval spolehlivosti pro s hladinou spolehlivosti .
Testování hypotézy o nulových hodnotách regresních koeficientů. Testovat hypotézu o absenci jakéhokoli lineárního vztahu mezi a souborem faktorů, tzn. o současné rovnosti k nule všech koeficientů kromě koeficientů s konstantou se používá statistika
 , (11)
, (11)
distribuováno, je-li pravda, podle Fisherova zákona s k a stupně volnosti. odmítnut, pokud
 (12)
(12)
kde je kvantil úrovně.
na začátek
Popis dat a prohlášení o problému
Zdrojový datový soubor tube_dataset.sta obsahuje 10 proměnných a 33 pozorování. Viz Obr. 1.

Rýže. 1. Počáteční datová tabulka ze souboru tube_dataset.sta
Název pozorování udává časový interval: čtvrtletí a rok (před bodem a za bodem). Každé pozorování obsahuje data pro odpovídající časový interval. 10 proměnná "Quarter" duplikuje číslo čtvrtletí v názvu pozorování. Seznam proměnných je uveden níže.

Cílová: Sestavte regresní model pro proměnnou č. 9 „Spotřeba potrubí“.
Kroky řešení:
1) Nejprve provedeme průzkumnou analýzu dostupných dat pro odlehlé hodnoty a nevýznamná data (sestavení spojnicových grafů a rozptylových grafů).
2) Ověřme přítomnost možných závislostí mezi pozorováními a mezi proměnnými (konstrukce korelačních matic).
3) Pokud budou pozorování tvořit skupiny, pak pro každou skupinu sestavíme regresní model pro proměnnou „Spotřeba potrubí“ (vícenásobná regrese).
Přečíslujme proměnné v pořadí v tabulce. Závislá proměnná (odezva) se bude nazývat proměnná "Spotřeba potrubí". Všechny ostatní proměnné nazýváme nezávislými (prediktory).
na začátek
Řešení problému krok za krokem
Krok 1. Rozptylové diagramy (viz obr. 2.) neodhalily žádné zjevné odlehlé hodnoty. Na mnoha grafech je přitom dobře patrná lineární závislost. Chybí také údaje pro „Spotřebu potrubí“ za 4 čtvrtletí roku 2000.

Rýže. 2. Bodový graf závislé proměnné (#9) a počtu jamek (#8)
Číslo za symbolem E ve značkách podél osy X udává mocninu čísla 10, která určuje pořadí hodnot proměnné č. 8 (Počet provozních vrtů). V tomto případě se bavíme o hodnotě cca 100 000 jamek (10 až 5. mocnina).
Na rozptylovém diagramu na obr. 3 (viz níže) jasně ukazuje 2 mračna bodů a každý z nich má jasný lineární vztah.
Je zřejmé, že proměnná č. 1 bude pravděpodobně zahrnuta do regresního modelu, protože naším úkolem je přesně identifikovat lineární vztah mezi prediktory a odezvou.

Rýže. 3. Bodový graf závislé proměnné (#9) a Investice do ropného průmyslu (#1)
Krok 2 Sestavme spojnicové grafy všech proměnných v závislosti na čase. Z grafů je vidět, že údaje pro mnoho proměnných se velmi liší v závislosti na čísle čtvrtletí, ale růst z roku na rok zůstává.
Získaný výsledek potvrzuje předpoklady získané na základě Obr. 3.

Rýže. 4. Spojnicový graf 1. proměnné versus čas
Zejména na Obr. 4 je spojnicový graf pro první proměnnou.
Krok 3 Podle výsledků Obr. 3 a Obr. 4, rozdělujeme pozorování do 2 skupin, podle proměnné č. 10 "Čtvrtletí". První skupina bude obsahovat údaje za 1. a 4. čtvrtletí a druhá - údaje za 2. a 3. čtvrtletí.
K rozdělení pozorování podle čtvrtletí do 2 tabulek použijeme položku Data/Podmnožina/Náhodné. Zde, jako pozorování, musíme specifikovat podmínky pro hodnoty proměnné QUARTER. Vidět rýže. 5.
Podle zadaných podmínek budou pozorování zkopírována do nové tabulky. V řádku níže můžete upřesnit konkrétní počty pozorování, ale v našem případě to bude trvat dlouho.

Rýže. 5. Výběr podmnožiny pozorování z tabulky
Jako danou podmínku nastavíme:
V10 = 1 NEBO V10 = 4
V10 je 10. proměnná v tabulce (V0 je sloupec pozorování). V podstatě každé pozorování v tabulce kontrolujeme, zda patří do 1. nebo 4. čtvrtletí nebo ne. Pokud chceme vybrat jinou podmnožinu pozorování, můžeme buď změnit podmínku na:
V10=2 NEBO V10=3
nebo přesunout první podmínku do vylučujících pravidel.
kliknutím OK, dostaneme nejprve tabulku s daty pouze za Q1 a Q4 a následně tabulku s daty za Q2 a Q3. Uložme je pod názvy 1_4.sta A 2_3.sta přes kartu Soubor/Uložit jako.
Dále budeme pracovat se dvěma tabulkami a výsledky regresní analýzy pro obě tabulky lze porovnat.
Krok 4 Pro každou ze skupin sestavíme korelační matici, abychom otestovali předpoklad lineárního vztahu a zohlednili možné silné korelace mezi proměnnými při sestavování regresního modelu. Vzhledem k tomu, že chybí data, byla vytvořena korelační matice s možností párového odstranění chybějících dat. Viz Obr. 6.

Rýže. 6. Korelační matice pro prvních 9 proměnných dle dat 1. a 4. čtvrtletí
Zejména z korelační matice je zřejmé, že některé proměnné spolu velmi silně korelují.
Je třeba poznamenat, že spolehlivost velkých korelačních hodnot je možná pouze v případě, že v původní tabulce nejsou žádné odlehlé hodnoty. Proto musí být v korelační analýze zohledněny bodové grafy pro závisle proměnnou a všechny ostatní proměnné.
Například proměnná #1 a #2 (Investice do ropného a plynárenského průmyslu). Viz obr.7 (nebo např. obr. 8).

Rýže. 7. Bodový graf pro proměnné #1 a #2

Rýže. 8. Bodový graf pro proměnné #1 a #7
Tato závislost se dá snadno vysvětlit. Zřetelný je i vysoký korelační koeficient mezi objemy těžby ropy a plynu.
Při sestavování regresního modelu je třeba vzít v úvahu vysoký korelační koeficient mezi proměnnými (multikolinearita). Zde může docházet k velkým chybám při výpočtu regresních koeficientů (špatně podmíněná matice při výpočtu odhadu přes nejmenší čtverce).
Zde jsou nejčastější způsoby opravy multikolinearita:
1) Ridge regrese.
Tato možnost se nastavuje při vytváření vícenásobné regrese. Číslo je malé kladné číslo. Odhad nejmenších čtverců se v tomto případě rovná:
 ,
,
Kde Y je vektor s hodnotami závislé proměnné, X je matice obsahující hodnoty prediktoru ve sloupcích a je maticí identity řádu n + 1. (n je počet prediktorů v modelu).
Špatná kondice matice je výrazně snížena při ridge regresi.
2) Vyloučení jedné z vysvětlujících proměnných.
V tomto případě je z analýzy vyloučena jedna vysvětlující proměnná, která má vysoký párový korelační koeficient (r>0,8) s jiným prediktorem.
3) Použití postupných postupů se začleněním/vyloučením prediktoru.
Obvykle se v takových případech používá buď hřebenová regrese (uvádí se jako možnost při konstrukci násobku), nebo se na základě korelačních hodnot vyloučí vysvětlující proměnné s vysokým párovým korelačním koeficientem (r > 0,8), nebo se postupná regrese s inkluzními / vylučovacími proměnnými.
Krok 5 Nyní vytvoříme regresní model pomocí karty rozbalovací nabídky ( Analýza/Vícenásobná regrese). Jako závislou proměnnou označujeme „Spotřeba potrubí“, jako nezávislou - vše ostatní. Viz Obr. 9.

Rýže. 9. Sestavení vícenásobné regrese pro tabulku 1_4.sta
Vícenásobnou regresi lze provést krok za krokem. V tomto případě model krok za krokem zahrne (nebo vyloučí) proměnné, které v tomto kroku nejvíce (nejméně) přispívají k regresi.
Také tato volba umožňuje zastavit se na kroku, kdy koeficient determinace ještě není největší, ale všechny proměnné modelu jsou již významné. Viz Obr. 10.

Rýže. 10. Sestavení vícenásobné regrese pro tabulku 1_4.sta
Zvláště stojí za zmínku, že postupná inkluzní regrese v případě, kdy je počet proměnných větší než počet pozorování, je jediným způsobem, jak vytvořit regresní model.
Nastavení volného členu regresního modelu na nulu se používá, pokud samotná myšlenka modelu implikuje nulovou hodnotu odezvy, když se ukáže, že všechny prediktory jsou rovny 0. Nejčastěji k takovým situacím dochází v ekonomických problémech.
V našem případě do modelu zahrneme volný termín.

Rýže. 11. Sestavení vícenásobné regrese pro tabulku 1_4.sta
Jako parametry modelu volíme Krok za krokem s výjimkou(Fon = 11, Foff = 10), s hřebenovou regresí (lambda = 0,1). A pro každou skupinu postavíme regresní model. Viz obr.11.
Výsledky ve formuláři Konečná regresní tabulka(viz také obr. 14) jsou znázorněny na obr. 12 a obr. 13. Získají se v posledním kroku regrese.
Krok 6Kontrola přiměřenosti modelu
Všimněte si, že navzdory významnosti všech proměnných v regresním modelu (p-level< 0.05 – подсвечены красным цветом), коэффициент детерминации R2 существенно меньше у первой группы наблюдений.
Koeficient determinace ve skutečnosti ukazuje, jaký podíl rozptylu odpovědi je vysvětlen vlivem prediktorů v konstruovaném modelu. Čím blíže je R2 k 1, tím je model lepší.
Fisherova F-statistika se používá k testování hypotézy o nulových hodnotách regresních koeficientů (tj. absence jakéhokoli lineárního vztahu mezi a sadou faktorů, kromě koeficientu). Hypotéza je zamítnuta na nízké hladině významnosti.
V našem případě (viz obr. 12) je hodnota F-statistiky = 13,249 na hladině významnosti p< 0,00092, т.е. гипотеза об отсутствии линейной связи отклоняется.

Rýže. 12. Výsledky regresní analýzy dat za 1. a 4. čtvrtletí

Rýže. 13. Výsledky regresní analýzy dat za 2. a 3. čtvrtletí
Krok 7 Nyní pojďme analyzovat zbytky výsledného modelu. Výsledky získané z analýzy reziduí jsou důležitým doplňkem hodnoty koeficientu determinace při kontrole adekvátnosti sestrojeného modelu.
Pro jednoduchost budeme uvažovat pouze skupinu rozdělenou na čtvrtiny s čísly 2 a 3, protože druhá skupina je studována podobným způsobem.
V okně zobrazeném na Obr. 14, tab Zbytkové/předpovězené/pozorované hodnoty zmáčknout tlačítko Analýza reziduí a poté klikněte na tlačítko Zůstává a předpovězeno. (Viz obr. 15)
Knoflík Analýza reziduí bude aktivní pouze v případě, že je regrese získána v posledním kroku. Častěji je důležité získat regresní model, ve kterém jsou všechny prediktory významné, než pokračovat v budování modelu (zvyšování koeficientu determinace) a získávat nevýznamné prediktory.
V tomto případě, kdy se regrese nezastaví na posledním kroku, můžete uměle nastavit počet kroků v regresi.

Rýže. 14. Okno s výsledky vícenásobné regrese pro data za 2. a 3. čtvrtletí

Rýže. 15. Rezidua a predikované hodnoty regresního modelu podle dat 2. a 3. čtvrtletí
Dovolte nám okomentovat výsledky uvedené na Obr. 15. Důležitý je sloupec s zbytky(rozdíl prvních 2 sloupců). Velká rezidua v mnoha pozorováních a přítomnost pozorování s malým reziduem může indikovat druhé jako odlehlou hodnotu.
Jinými slovy, zbytková analýza je potřebná, aby bylo možné snadno odhalit odchylky od předpokladů, které ohrožují platnost výsledků analýzy.

Rýže. 16. Rezidua a predikované hodnoty regresního modelu podle dat za 2 a 3 čtvrtletí + 2 meze intervalu spolehlivosti 0,95
Na závěr uvádíme graf znázorňující data získaná z tabulky na Obr. 16. Zde přidány 2 proměnné: UCB a LCB - 0,95 top. a nižší dov. interval.
UBC=V2+1,96*V6
LBC=V2-1,96*V6
A odstranil poslední čtyři pozorování.
Vytvořme spojnicový graf s proměnnými ( Ploty/2M Ploty/Line Ploty pro proměnné)
1) Pozorovaná hodnota (V1)
2) Předpokládaná hodnota (V2)
3) UCB (V9)
4) LCB (V10)
Výsledek je znázorněn na Obr. 17. Nyní je zřejmé, že sestrojený regresní model poměrně dobře odráží skutečnou spotřebu potrubí, zejména na výsledcích z nedávné minulosti.
To znamená, že v blízké budoucnosti mohou být skutečné hodnoty aproximovány těmi modelovými.
Všimněme si jednoho důležitého bodu. Při prognózování pomocí regresních modelů je vždy důležitý podkladový časový interval. V uvažovaném problému byly vybrány čtvrtiny.
V souladu s tím budou při vytváření prognózy předpokládané hodnoty získány také po čtvrtletích. Pokud potřebujete získat předpověď na rok, budete muset předpovídat na 4 čtvrtletí a na konci se nahromadí velká chyba.
Podobný problém lze řešit obdobným způsobem, zpočátku pouze agregací dat ze čtvrtletí na roky (například zprůměrováním). Pro tento problém není přístup příliš správný, protože zbude pouze 8 pozorování, která budou použita k sestavení regresního modelu. Viz obr.18.

Rýže. 17. Pozorované a předpovězené hodnoty spolu s horní 0,95. a nižší důvěra intervaly (údaje za 2 a 3 čtvrtletí)

Rýže. 18. Pozorované a předpovězené hodnoty spolu s horní 0,95. a nižší důvěra intervaly (údaje podle let)
Nejčastěji se tento přístup používá při agregaci dat po měsících, s počátečními daty po dnech.
Je třeba mít na paměti, že všechny metody regresní analýzy mohou detekovat pouze numerické vztahy, a nikoli základní kauzální vztahy. Odpověď na otázku o významnosti proměnných ve výsledném modelu tedy zůstává na odborníkovi v této oblasti, který je zejména schopen zohlednit vliv faktorů, které nemusí být v této tabulce zahrnuty.
V jeho dílech sahá až do roku 1908. Popsal to na příkladu práce agenta prodávajícího nemovitosti. Specialista na prodej domů ve svých poznámkách vedl záznamy o široké škále vstupních dat pro každou konkrétní budovu. Na základě výsledků aukce bylo určeno, který faktor měl největší vliv na cenu transakce.
Analýza velký počet nabídky daly zajímavé výsledky. Konečnou cenu ovlivnilo mnoho faktorů, které někdy vedly k paradoxním závěrům a dokonce přímo „odlehlým“, když byl dům s vysokým počátečním potenciálem prodán za nižší cenový ukazatel.
Druhým příkladem aplikace takové analýzy je práce, která byla pověřena stanovením odměn zaměstnanců. Složitost úkolu spočívala v tom, že bylo požadováno nerozdělovat pevnou částku všem, ale striktně odpovídat její hodnotě konkrétní vykonané práci. Vznik mnoha problémů s prakticky podobným řešením si vyžádal jejich podrobnější studium na matematické úrovni.
Významné místo bylo věnováno sekci "regresní analýza", která byla kombinována praktické metody používá se ke studiu závislostí, které spadají pod pojem regrese. Tyto vztahy jsou pozorovány mezi údaji získanými v průběhu statistických studií.
Mezi mnoha úkoly, které je třeba vyřešit, si klade tři hlavní cíle: definici regresní rovnice obecný pohled; vytváření odhadů parametrů, které jsou neznámé, které jsou součástí regresní rovnice; testování statistických regresních hypotéz. V průběhu studia vztahu, který vzniká mezi dvojicí veličin získaných v důsledku experimentálních pozorování a tvořících řadu (množinu) typu (x1, y1), ..., (xn, yn), spoléhají na ustanovení regresní teorie a předpokládají, že pro jednu veličinu Y je dodrženo určité rozdělení pravděpodobnosti, zatímco druhé X zůstává pevné.
Výsledek Y závisí na hodnotě proměnné X, tato závislost může být určena různými vzory, přičemž přesnost získaných výsledků je ovlivněna povahou pozorování a účelem analýzy. Experimentální model je založen na určitých předpokladech, které jsou zjednodušené, ale věrohodné. Hlavní podmínkou je, že parametr X je řízená hodnota. Jeho hodnoty jsou nastaveny před začátkem experimentu.
Je-li při experimentu použita dvojice nekontrolovaných proměnných XY, pak se regresní analýza provádí stejným způsobem, ale k interpretaci výsledků, během nichž se studuje vztah zkoumaných náhodných proměnných, se používají metody. matematické statistiky nejsou abstraktním tématem. Své uplatnění v životě nacházejí v různých oblastech lidské činnosti.
Ve vědecké literatuře našel termín lineární regresní analýza široké použití pro definici výše uvedené metody. Pro proměnnou X se používá termín regresor nebo prediktor a závislé proměnné Y se také nazývají kriteriální proměnné. Tato terminologie odráží pouze matematickou závislost proměnných, nikoli však kauzálně-kauzální vztahy.
Regresní analýza je nejběžnější metodou používanou při zpracování výsledků široké škály pozorování. Fyzické a biologické závislosti jsou studovány pomocí prostředků tato metoda, realizuje se jak v ekonomice, tak v technice. Modely využívá řada dalších oblastí regresní analýza. disperzní analýza, Statistická analýza multidimenzionální úzce spolupracovat s tímto způsobem studia.
y=F(X), kdy každá hodnota nezávisle proměnné X odpovídá jedné konkrétní hodnotě veličiny y, s regresním vztahem ke stejné hodnotě X může v závislosti na případu odpovídat různým hodnotám množství y. Pokud u každé hodnoty existuje n i (\displaystyle n_(i)) hodnoty y i 1 …y v 1 velikost y, pak závislost aritmetického průměru y ¯ i = (y i 1 + . . . + y i n 1) / n i (\displaystyle (\bar (y))_(i)=(y_(i1)+...+y_(in_(1)))) /n_(i)) z x = x i (\displaystyle x=x_(i)) a je regresí ve statistickém smyslu tohoto termínu.Encyklopedický YouTube
-
1 / 5
Tento termín poprvé použil ve statistice Francis Galton (1886) v souvislosti se studiem dědičnosti lidských fyzických vlastností. Lidská výška byla brána jako jedna z charakteristik; zatímco bylo zjištěno, že obecně byli synové vysokých otců nepřekvapivě vyšší než synové otců nízkého vzrůstu. Zajímavější bylo, že odchylka ve výšce synů byla menší než odchylka ve výšce otců. Existovala tedy tendence k návratu růstu synů k průměru ( regrese k průměrnosti), tedy "regrese". Tato skutečnost byla prokázána výpočtem průměrné výšky synů otců, kteří jsou 56 palců vysocí, výpočtem průměrné výšky synů otců, kteří jsou 58 palců vysocí, a tak dále. průměrné výšky otců. Body (přibližně) leží na přímce s kladným sklonem menším než 45°; je důležité, aby regrese byla lineární.
Popis
Předpokládejme, že existuje vzorek z dvourozměrného rozdělení dvojice náhodných proměnných ( X, Y). Přímka v rovině ( x, y) byla selektivní obdobou funkce
g (x) = E (Y ∣ X = x) . (\displaystyle g(x)=E(Y\mid X=x).) E (Y ∣ X = x) = μ 2 + ϱ σ 2 σ 1 (x − μ 1) , (\displaystyle E(Y\mid X=x)=\mu _(2)+\varrho (\frac ( \sigma _(2))(\sigma _(1)))(x-\mu _(1)),) v a r (Y ∣ X = x) = σ 2 2 (1 − ϱ 2) . (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).)V tomto příkladu regrese Y na X je lineární funkcí . Pokud regrese Y na X je odlišná od lineární, pak jsou dané rovnice lineární aproximací skutečné regresní rovnice.
Obecně platí, že regrese jedné náhodné proměnné do druhé nemusí být nutně lineární. Není také nutné se omezovat na pár náhodných proměnných. Statistické problémy regrese souvisí s určením obecného tvaru regresní rovnice, konstruováním odhadů neznámých parametrů obsažených v regresní rovnici a testováním statistických hypotéz o regresi. Tyto problémy jsou posuzovány v rámci regresní analýzy.
Jednoduchý příklad regrese Y Podle X je vztah mezi Y A X, což je vyjádřeno poměrem: Y=u(X)+ε, kde u(X)=E(Y | X=X), A náhodné proměnné X a ε jsou nezávislé. Tato reprezentace je užitečná, když je plánován experiment ke studiu funkční konektivity. y=u(X) mezi nenáhodnými proměnnými y A X. V praxi jsou obvykle regresní koeficienty v rovnici y=u(X) jsou neznámé a jsou odhadnuty z experimentálních dat.
Lineární regrese
Představte si závislost y z X ve formě lineárního modelu prvního řádu:
y = β 0 + β 1 x + ε. (\displaystyle y=\beta _(0)+\beta _(1)x+\varepsilon .)Budeme předpokládat, že hodnoty X jsou určeny bez chyby, β 0 a β 1 jsou parametry modelu a ε je chyba, jejíž rozdělení se řídí normálním zákonem s nulovou střední a konstantní odchylkou σ 2 . Hodnoty parametrů β nejsou předem známy a musí být určeny ze souboru experimentálních hodnot ( x i, y i), i=1, …, n. Můžeme tedy napsat:
y i ^ = b 0 + b 1 x i, i = 1 , … , n (\displaystyle (\widehat (y_(i)))=b_(0)+b_(1)x_(i),i=1,\ tečky, n)kde znamená hodnotu předpokládanou modelem y daný X, b 0 a b 1 - vzorové odhady parametrů modelu. Také definujeme e i = y i − y i ^ (\displaystyle e_(i)=y_(i)-(\widehat (y_(i))))- hodnota aproximační chyby pro i (\displaystyle i) pozorování.
Metoda nejmenších čtverců dává následující vzorce pro výpočet parametrů tohoto modelu a jejich odchylek:
b 1 = ∑ i = 1 n (x i − x ¯) (y i − y ¯) ∑ i = 1 n (x i − x ¯) 2 = c o v (x , y) σ x 2 ; (\displaystyle b_(1)=(\frac (\sum _(i=1)^(n)(x_(i)-(\bar (x)))(y_(i)-(\bar (y) )))(\sum _(i=1)^(n)(x_(i)-(\bar (x)))^(2)))=(\frac (\mathrm (cov) (x,y ))(\sigma _(x)^(2)));) b 0 = y ¯ − b 1 x ¯ ; (\displaystyle b_(0)=(\bar (y))-b_(1)(\bar (x));) s e 2 = ∑ i = 1 n (y i − y ^) 2 n − 2 ; (\displaystyle s_(e)^(2)=(\frac (\sum _(i=1)^(n)(y_(i)-(\widehat (y)))^(2))(n- 2));) s b 0 = s e 1 n + x ¯ 2 ∑ i = 1 n (x i − x ¯) 2 ; (\displaystyle s_(b_(0))=s_(e)(\sqrt ((\frac (1)(n))+(\frac ((\bar (x))^(2))(\sum _ (i=1)^(n)(x_(i)-(\bar (x)))^(2)))));) s b 1 = s e 1 ∑ i = 1 n (x i − x ¯) 2 , (\displaystyle s_(b_(1))=s_(e)(\sqrt (\frac (1)(\součet _(i=1) )^(n)(x_(i)-(\bar (x)))^(2)))),)zde jsou průměry definovány jako obvykle: x ¯ = ∑ i = 1 n x i n (\displaystyle (\bar (x))=(\frac (\sum _(i=1)^(n)x_(i))(n))), y ¯ = ∑ i = 1 n y i n (\displaystyle (\bar (y))=(\frac (\sum _(i=1)^(n)y_(i))(n))) A s e 2 označuje regresní reziduum, což je odhad rozptylu σ 2, pokud je model správný.
Obdobně se používají směrodatné chyby regresních koeficientů standardní chyba průměr - najít intervaly spolehlivosti a testovat hypotézy. Studentovo kritérium používáme např. k testování hypotézy, že regresní koeficient je roven nule, tedy že je pro model nevýznamný. Studentské statistiky: t = b / s b (\displaystyle t=b/s_(b)). Pokud pravděpodobnost pro získanou hodnotu a n−2 stupně volnosti jsou dostatečně malé, např.<0,05 - гипотеза отвергается. Напротив, если нет оснований отвергнуть гипотезу о равенстве нулю, скажем, b 1 (\displaystyle b_(1))- je důvod přemýšlet o existenci požadované regrese, alespoň v této podobě, nebo o sběru dalších pozorování. Pokud je volný termín roven nule b 0 (\displaystyle b_(0)), pak přímka prochází počátkem a odhad sklonu je
b = ∑ i = 1 n x i y i ∑ i = 1 n x i 2 (\displaystyle b=(\frac (\sum _(i=1)^(n)x_(i)y_(i))(\součet _(i= 1)^(n)x_(i)^(2)))),a jeho standardní chyba
s b = s e 1 ∑ i = 1 n x i 2 . (\displaystyle s_(b)=s_(e)(\sqrt (\frac (1)(\sum _(i=1)^(n)x_(i)^(2)))).)Obvykle nejsou známy skutečné hodnoty regresních koeficientů β 0 a β 1. Známé jsou pouze jejich odhady b 0 a b 1. Jinými slovy, skutečná přímka regrese může jít jinak než ta, která je postavena na vzorových datech. Můžete vypočítat oblast spolehlivosti pro regresní přímku. Za jakoukoli hodnotu X odpovídající hodnoty y distribuován normálně. Průměr je hodnota regresní rovnice y ^ (\displaystyle (\widehat(y))). Nejistotu jeho odhadu charakterizuje standardní regresní chyba:
s y ^ = s e 1 n + (x − x ¯) 2 ∑ i = 1 n (x i − x ¯) 2 ; (\displaystyle s_(\widehat (y))=s_(e)(\sqrt ((\frac (1)(n))+(\frac ((x-(\bar (x)))^(2) )(\sum _(i=1)^(n)(x_(i)-(\bar (x)))^(2)))))));)Nyní můžete vypočítat -procentní interval spolehlivosti pro hodnotu regresní rovnice v daném bodě X:
y ^ − t (1 − α / 2, n − 2) s y ^< y < y ^ + t (1 − α / 2 , n − 2) s y ^ {\displaystyle {\widehat {y}}-t_{(1-\alpha /2,n-2)}s_{\widehat {y}}Kde t(1−α/2, n−2) - t-Hodnota rozdělení studentů. Obrázek ukazuje 10bodovou regresní přímku (plné tečky) a také oblast 95% spolehlivosti regresní přímky, která je ohraničena tečkovanými čarami. S 95% pravděpodobností lze tvrdit, že skutečná čára je někde uvnitř této oblasti. Nebo jinak, pokud shromáždíme podobné soubory dat (označené kroužky) a postavíme na nich regresní čáry (označené modře), pak v 95 případech ze 100 tyto čáry neopustí oblast spolehlivosti. (Pro vizualizaci klikněte na obrázek) Všimněte si, že některé body jsou mimo oblast spolehlivosti. To je zcela přirozené, protože mluvíme o oblasti spolehlivosti regresní přímky, nikoli o hodnotách samotných. Rozptyl hodnot je součtem rozptylu hodnot kolem regresní přímky a nejistoty polohy této přímky samotné, konkrétně:
s Y = s e 1 m + 1 n + (x − x ¯) 2 ∑ i = 1 n (x i − x ¯) 2 ; (\displaystyle s_(Y)=s_(e)(\sqrt ((\frac (1)(m))+(\frac (1)(n))+(\frac ((x-(\bar (x) )))^(2))(\součet _(i=1)^(n)(x_(i)-(\bar (x)))^(2)))))));)Tady m- násobnost měření y daný X. A 100 ⋅ (1 − α 2) (\displaystyle 100\cdot \left(1-(\frac (\alpha )(2))\right))-procentní interval spolehlivosti (interval předpovědi) pro průměr m hodnoty y vůle:
y ^ − t (1 − α / 2, n − 2) s Y< y < y ^ + t (1 − α / 2 , n − 2) s Y {\displaystyle {\widehat {y}}-t_{(1-\alpha /2,n-2)}s_{Y}Na obrázku je tato oblast s 95% spolehlivostí m=1 je ohraničen plnými čarami. Tato oblast zahrnuje 95 % všech možných hodnot veličiny y ve zkoumaném rozmezí hodnot X.
Ještě pár statistik
Lze důsledně prokázat, že pokud je podmíněné očekávání E (Y ∣ X = x) (\displaystyle E(Y\mid X=x)) nějaká dvourozměrná náhodná proměnná ( X, Y) je lineární funkcí x (\displaystyle x), pak musí být toto podmíněné očekávání zastoupeno ve formuláři E (Y ∣ X = x) = μ 2 + ϱ σ 2 σ 1 (x − μ 1) (\displaystyle E(Y\mid X=x)=\mu _(2)+\varrho (\frac (\ sigma _(2))(\sigma _(1)))(x-\mu _(1))), Kde E(X)=μ 1 , E(Y)=μ 2, var( X)=σ 1 2, var( Y)=σ 2 2, kor( X, Y)=ρ.
Navíc pro dříve zmíněný lineární model Y = β 0 + β 1 X + ε (\displaystyle Y=\beta _(0)+\beta _(1)X+\varepsilon ), Kde X (\displaystyle X) a jsou nezávislé náhodné proměnné a ε (\displaystyle \varepsilon ) má nulová očekávání (a libovolné rozdělení), lze to dokázat E (Y ∣ X = x) = β 0 + β 1 x (\displaystyle E(Y\mid X=x)=\beta _(0)+\beta _(1)x). Potom pomocí výše uvedené rovnosti můžeme získat vzorce pro a: β 1 = ϱ σ 2 σ 1 (\displaystyle \beta _(1)=\varrho (\frac (\sigma _(2))(\sigma _(1)))),
β 0 = μ 2 − β 1 μ 1 (\displaystyle \beta _(0)=\mu _(2)-\beta _(1)\mu _(1))
Pokud je odněkud a priori známo, že množina náhodných bodů v rovině je generována lineárním modelem, ale s neznámými koeficienty β 0 (\displaystyle \beta _(0)) A β 1 (\displaystyle \beta _(1)), můžeme získat bodové odhady těchto koeficientů pomocí uvedených vzorců. K tomu, v těchto vzorcích místo matematických očekávání, rozptyly a korelace náhodných veličin X A Y musíte nahradit jejich nezkreslené odhady. Získané odhadové vzorce se přesně shodují se vzorci odvozenými na základě metody nejmenších čtverců.
Hlavním rysem regresní analýzy je, že ji lze použít k získání konkrétních informací o formě a povaze vztahu mezi zkoumanými proměnnými.
Posloupnost fází regresní analýzy
Podívejme se krátce na fáze regresní analýzy.
Formulace úkolu. V této fázi se tvoří předběžné hypotézy o závislosti studovaných jevů.
Definice závislých a nezávislých (vysvětlujících) proměnných.
Sběr statistických dat. Data musí být shromážděna pro každou z proměnných obsažených v regresním modelu.
Formulace hypotézy o formě spojení (jednoduché nebo vícenásobné, lineární nebo nelineární).
Definice regresní funkce (spočívá ve výpočtu číselných hodnot parametrů regresní rovnice)
Hodnocení přesnosti regresní analýzy.
Interpretace získaných výsledků. Výsledky regresní analýzy jsou porovnány s předběžnými hypotézami. Hodnotí se správnost a věrohodnost získaných výsledků.
Predikce neznámých hodnot závislé proměnné.
Pomocí regresní analýzy je možné vyřešit problém prognózování a klasifikace. Prediktivní hodnoty se počítají nahrazením hodnot vysvětlujících proměnných do regresní rovnice. Klasifikační problém je vyřešen tímto způsobem: regresní přímka rozděluje celou množinu objektů do dvou tříd a část množiny, kde je hodnota funkce větší než nula, patří do jedné třídy a část, kde je menší než nula patří do jiné třídy.
Úkoly regresní analýzy
Zvažte hlavní úkoly regresní analýzy: stanovení formy závislosti, určení regresní funkce, odhad neznámých hodnot závislé proměnné.
Ustavení formy závislosti.
Povaha a forma vztahu mezi proměnnými mohou tvořit následující typy regrese:
pozitivní lineární regrese (vyjádřená jako rovnoměrný růst funkce);
pozitivní rovnoměrně se zrychlující regrese;
pozitivní rovnoměrně rostoucí regrese;
negativní lineární regrese (vyjádřená jako jednotný pokles funkce);
negativní rovnoměrně zrychlená klesající regrese;
negativní rovnoměrně klesající regrese.
Popsané odrůdy se však obvykle nenacházejí v čisté formě, ale ve vzájemné kombinaci. V tomto případě se hovoří o kombinovaných formách regrese.
Definice regresní funkce.
Druhým úkolem je zjistit vliv hlavních faktorů nebo příčin na závisle proměnnou za stejných podmínek a s vyloučením vlivu náhodných prvků na závislou proměnnou. regresní funkce definována jako matematická rovnice toho či onoho typu.
Odhad neznámých hodnot závislé proměnné.
Řešení tohoto problému je redukováno na řešení problému jednoho z následujících typů:
Odhad hodnot závislé proměnné v rámci uvažovaného intervalu výchozích dat, tzn. chybějící hodnoty; to řeší problém interpolace.
Odhad budoucích hodnot závislé proměnné, tzn. nalezení hodnot mimo daný interval počátečních dat; tím je problém extrapolace vyřešen.
Oba problémy jsou řešeny dosazením nalezených odhadů parametrů hodnot nezávislých proměnných do regresní rovnice. Výsledkem řešení rovnice je odhad hodnoty cílové (závislé) proměnné.
Podívejme se na některé předpoklady, o které se regresní analýza opírá.
Předpoklad linearity, tzn. předpokládá se, že vztah mezi uvažovanými proměnnými je lineární. V tomto příkladu jsme tedy vytvořili bodový graf a byli jsme schopni vidět jasný lineární vztah. Pokud na bodovém grafu proměnných vidíme jasnou absenci lineární spojení, tj. existuje nelineární vztah, měly by být použity nelineární metody analýzy.
Předpoklad normality zbytky. Předpokládá, že rozložení rozdílu mezi předpokládanými a pozorovanými hodnotami je normální. Chcete-li vizuálně určit povahu distribuce, můžete použít histogramy zbytky.
Při použití regresní analýzy je třeba vzít v úvahu její hlavní omezení. Spočívá v tom, že regresní analýza umožňuje detekovat pouze závislosti, nikoli vztahy, které jsou základem těchto závislostí.
Regresní analýza umožňuje posoudit míru asociace mezi proměnnými výpočtem očekávané hodnoty proměnné na základě několika známých hodnot.
Regresní rovnice.
Regresní rovnice vypadá takto: Y=a+b*X
Pomocí této rovnice je proměnná Y vyjádřena jako konstanta a a sklon přímky (nebo sklonu) b násobený hodnotou proměnné X. Konstanta a se také nazývá průsečík a sklon je regrese koeficient nebo B-faktor.
Ve většině případů (pokud ne vždy) existuje určitý rozptyl pozorování o regresní přímce.
Zbytek je odchylka jednotlivého bodu (pozorování) od regresní přímky (predikované hodnoty).
Chcete-li vyřešit problém regresní analýzy v MS Excel, vyberte z nabídky Servis"Analytický balíček" a nástroj pro regresní analýzu. Zadejte vstupní intervaly X a Y. Vstupní interval Y je rozsah analyzovaných závislých dat a musí obsahovat jeden sloupec. Vstupní interval X je rozsah nezávislých dat, která mají být analyzována. Počet vstupních rozsahů nesmí překročit 16.
Na výstupu procedury ve výstupním rozsahu získáme report uvedený v tabulka 8.3a-8,3v.
VÝSLEDEK
Tabulka 8.3a. Regresní statistika
Regresní statistika
Více R
R-čtverec
Normalizovaný R-čtverec
standardní chyba
Pozorování
Nejprve zvažte horní část výpočtů uvedených v tabulka 8.3a, - regresní statistika.
Hodnota R-čtverec, nazývané také míra jistoty, charakterizuje kvalitu výsledné regresní přímky. Tato kvalita je vyjádřena mírou korespondence mezi původními daty a regresním modelem (vypočtenými daty). Míra jistoty je vždy v rámci intervalu .
Ve většině případů hodnota R-čtverec je mezi těmito hodnotami, nazývá se extrémní, tzn. mezi nulou a jedničkou.
Pokud je hodnota R-čtverec blízko jednoty, to znamená, že sestrojený model vysvětluje téměř veškerou variabilitu odpovídajících proměnných. Naopak hodnota R-čtverec, blízko nule, znamená špatnou kvalitu zkonstruovaného modelu.
V našem příkladu je míra jistoty 0,99673, což indikuje velmi dobrou shodu regresní přímky s původními daty.
množné číslo R - koeficient vícenásobné korelace R - vyjadřuje míru závislosti nezávisle proměnných (X) a závislé proměnné (Y).
Více R rovná se druhé odmocnině koeficientu determinace, tato hodnota nabývá hodnot v rozsahu od nuly do jedné.
V jednoduché lineární regresní analýze množné číslo R rovna Pearsonově korelačnímu koeficientu. Opravdu, množné číslo R v našem případě se rovná Pearsonově korelačnímu koeficientu z předchozího příkladu (0,998364).
Tabulka 8.3b. Regresní koeficienty
Kurzy
standardní chyba
t-statistika
Y-průsečík
Proměnná X1
* Je uvedena zkrácená verze výpočtů
Nyní zvažte střední část výpočtů uvedených v tabulka 8.3b. Zde je uveden regresní koeficient b (2,305454545) a posun podél osy y, tzn. konstanta a (2,694545455).
Na základě výpočtů můžeme napsat regresní rovnici takto:
Y= x*2,305454545 + 2,694545455
Směr vztahu mezi proměnnými je určen na základě znamének (záporných nebo kladných) regresních koeficientů (koeficient b).
Pokud je znaménko regresního koeficientu kladné, bude vztah mezi závisle proměnnou a nezávisle proměnnou kladný. V našem případě je znaménko regresního koeficientu kladné, tedy i vztah kladný.
Pokud je znaménko regresního koeficientu záporné, je vztah mezi závisle proměnnou a nezávisle proměnnou záporný (inverzní).
V tabulka 8.3c. jsou prezentovány výstupní výsledky zbytky. Aby se tyto výsledky objevily v přehledu, je nutné při spuštění nástroje "Regrese" aktivovat zaškrtávací políčko "Residuals".
ZBÝVAJÍCÍ ODBĚR
Tabulka 8.3c. Zůstává
Pozorování
Předpokládaný Y
Zůstává
Standardní zůstatky
Pomocí této části zprávy můžeme vidět odchylky každého bodu od sestrojené regresní přímky. Největší absolutní hodnota zbytek v našem případě - 0,778, nejmenší - 0,043. Pro lepší interpretaci těchto dat použijeme graf původních dat a sestrojenou regresní přímku uvedenou na Obr. rýže. 8.3. Jak vidíte, regresní přímka je poměrně přesně „přizpůsobena“ hodnotám původních dat.
Je třeba vzít v úvahu, že uvažovaný příklad je poměrně jednoduchý a zdaleka ne vždy je možné kvalitativně sestrojit lineární regresní přímku.
Rýže. 8.3. Počáteční data a regresní přímka
Problém odhadu neznámých budoucích hodnot závislé proměnné na základě známých hodnot nezávislé proměnné zůstal nezvažován, tzn. prognostický úkol.
S regresní rovnicí se problém předpovědi redukuje na řešení rovnice Y= x*2,305454545+2,694545455 se známými hodnotami x. Jsou uvedeny výsledky predikce závislé proměnné Y o šest kroků dopředu v tabulce 8.4.
Tabulka 8.4. Výsledky predikce proměnné Y
Y (předpovězeno)
V důsledku použití regresní analýzy v balíčku Microsoft Excel tedy:
sestavil regresní rovnici;
stanovena forma závislosti a směr vztahu mezi proměnnými - pozitivní lineární regrese, která je vyjádřena rovnoměrným růstem funkce;
stanovil směr vztahu mezi proměnnými;
posoudil kvalitu výsledné regresní přímky;
byli schopni vidět odchylky vypočtených dat od dat původního souboru;
předpověděl budoucí hodnoty závislé proměnné.
Li regresní funkce je definován, interpretován a odůvodněn a posouzení přesnosti regresní analýzy splňuje požadavky, lze předpokládat, že sestrojený model a prediktivní hodnoty jsou dostatečně spolehlivé.
Takto získané predikované hodnoty jsou průměrné hodnoty, které lze očekávat.
V tomto článku jsme shrnuli hlavní charakteristiky deskriptivní statistika a mezi nimi takové pojmy jako průměrná hodnota,medián,maximum,minimální a další charakteristiky variace dat.
Proběhla také krátká diskuse o konceptu emisí. Uvažované charakteristiky odkazují na tzv. explorativní analýzu dat, její závěry se nemusí vztahovat na běžnou populaci, ale pouze na datový vzorek. Průzkumná analýza dat se používá k vyvozování primárních závěrů a vytváření hypotéz o populaci.
Zvažovány byly také základy korelační a regresní analýzy, jejich úkoly a možnosti praktického využití.
Hlavní cíl regresní analýzy spočívá v určení analytické formy vztahu, ve kterém je změna výsledného atributu způsobena vlivem jednoho nebo více faktorových znamének a množina všech ostatních faktorů, které také ovlivňují výsledný atribut, je brána jako konstantní a průměrné hodnoty .
Úkoly regresní analýzy:
a) Ustavení formy závislosti. Co se týče povahy a formy vztahu mezi jevy, existují pozitivní lineární a nelineární a negativní lineární a nelineární regrese.
b) Definice regresní funkce ve formě matematické rovnice toho či onoho typu a stanovení vlivu vysvětlujících proměnných na závisle proměnnou.
c) Odhad neznámých hodnot závislé proměnné. Pomocí regresní funkce můžete reprodukovat hodnoty závislé proměnné v intervalu daných hodnot vysvětlujících proměnných (t.j. řešit interpolační problém) nebo vyhodnocovat průběh procesu mimo zadaný interval (t.j. vyřešit extrapolační problém). Výsledkem je odhad hodnoty závislé proměnné.Párová regrese - rovnice vztahu dvou proměnných y a x: , kde y je závislá proměnná (efektivní znaménko); x - nezávislá, vysvětlující proměnná (vlastnost-faktor).
Existují lineární a nelineární regrese.
Regrese, které jsou nelineární z hlediska odhadovaných parametrů: Sestavení regresní rovnice se redukuje na odhad jejích parametrů. Pro odhad parametrů regresí, které jsou v parametrech lineární, se používá metoda nejmenších čtverců (LSM). LSM umožňuje získat takové odhady parametrů, při kterých je součet kvadrátů odchylek skutečných hodnot výsledného znaku y od teoretických minimální, tzn.
Lineární regrese: y = a + bx + ε
Nelineární regrese jsou rozděleny do dvou tříd: regrese, které jsou nelineární s ohledem na vysvětlující proměnné zahrnuté v analýze, ale lineární s ohledem na odhadované parametry, a regrese, které jsou nelineární s ohledem na odhadované parametry.
Regrese, které jsou nelineární ve vysvětlujících proměnných: .
.
Pro lineární a nelineární rovnice redukovatelné na lineární se pro a a b řeší následující systém:
Můžete použít hotové vzorce, které vyplývají z tohoto systému:
Těsnost souvislosti mezi zkoumanými jevy se odhaduje pomocí lineárního koeficientu párové korelace pro lineární regresi:
a korelační index - pro nelineární regresi:
Hodnocení kvality sestrojeného modelu bude dáno koeficientem (indexem) determinace a také průměrnou aproximační chybou.
Průměrná chyba aproximace je průměrná odchylka vypočítaných hodnot od skutečných: .
.
Přípustný limit hodnot - ne více než 8-10%.
Průměrný koeficient pružnosti ukazuje, o kolik procent se v průměru změní výsledek y od své průměrné hodnoty, když se faktor x změní o 1 % od své průměrné hodnoty:
.Úkolem analýzy rozptylu je analyzovat rozptyl závislé proměnné:
,
kde je celkový součet čtverců odchylek;
- součet čtverců odchylek v důsledku regrese („vysvětlené“ nebo „faktoriální“);
- zbytkový součet kvadrátů odchylek.
Podíl rozptylu vysvětleného regresí na celkovém rozptylu efektivního znaku y charakterizuje koeficient (index) determinace R2:
Koeficient determinace je druhou mocninou koeficientu nebo indexu korelace.F-test - hodnocení kvality regresní rovnice - spočívá v testování hypotézy Ale o statistické nevýznamnosti regresní rovnice a indikátoru těsnosti souvislosti. Za tímto účelem se provede porovnání skutečné F skutečnosti a kritické (tabulkové) F tabulky hodnot Fisherova F-kritéria. F fact se určí z poměru hodnot faktoriálu a zbytkových rozptylů vypočtených pro jeden stupeň volnosti:
 ,
,
kde n je počet jednotek populace; m je počet parametrů pro proměnné x.
F tabulka je maximální možná hodnota kritéria pod vlivem náhodných faktorů pro dané stupně volnosti a hladinu významnosti a. Úroveň významnosti a - pravděpodobnost zamítnutí správné hypotézy za předpokladu, že je pravdivá. Obvykle se a považuje za rovné 0,05 nebo 0,01.
Pokud F tabulka< F факт, то Н о - гипотеза о случайной природе оцениваемых характеристик отклоняется и признается их статистическая значимость и надежность. Если F табл >F je fakt, pak hypotéza H o není zamítnuta a je uznána statistická nevýznamnost, nespolehlivost regresní rovnice.
Pro posouzení statistické významnosti regresních a korelačních koeficientů se vypočítá Studentův t-test a intervaly spolehlivosti pro každý z ukazatelů. Je předložena hypotéza H o náhodné povaze indikátorů, tzn. o jejich nepatrném rozdílu od nuly. Posouzení významnosti regresních a korelačních koeficientů pomocí Studentova t-testu se provádí porovnáním jejich hodnot s velikostí náhodné chyby:
; ; .
Náhodné chyby parametrů lineární regrese a korelačního koeficientu určují vzorce:
Porovnáním skutečných a kritických (tabulkových) hodnot t-statistiky - t tabl a t fact - přijímáme nebo zamítáme hypotézu H o.
Vztah mezi Fisherovým F-testem a Studentovou t-statistikou je vyjádřen rovností
Pokud t tabulka< t факт то H o отклоняется, т.е. a, b и не случайно отличаются от нуля и сформировались под влиянием систематически действующего фактора х. Если t табл >t skutečnost, že hypotéza H o není zamítnuta a je rozpoznána náhodná povaha vzniku a, b nebo.
Pro výpočet intervalu spolehlivosti určíme mezní chybu D pro každý indikátor:
, .
Vzorce pro výpočet intervalů spolehlivosti jsou následující:
; ;
; ;
Pokud nula spadá do hranic intervalu spolehlivosti, tzn. Pokud je spodní mez záporná a horní mez kladná, předpokládá se, že odhadovaný parametr je nulový, protože nemůže současně nabývat kladných i záporných hodnot.
Předpovědní hodnota je určena dosazením odpovídající (předpovědní) hodnoty do regresní rovnice. Průměrná standardní chyba prognózy se vypočítá: ,
,
Kde
a interval spolehlivosti prognózy je vytvořen: ;
;  ;
; 
Kde .
.Příklad řešení
Úkol číslo 1. Pro sedm území regionu Ural Pro 199X jsou známy hodnoty dvou znaků.
Stůl 1.
Požadované: 1. Chcete-li charakterizovat závislost y na x, vypočítejte parametry následujících funkcí:
a) lineární;
b) mocninný zákon (dříve bylo nutné provést postup linearizace proměnných logaritmováním obou částí);
c) demonstrativní;
d) rovnostranná hyperbola (musíte také přijít na to, jak tento model předlinearizovat).
2. Vyhodnoťte každý model pomocí střední aproximační chyby a Fisherova F-testu.Řešení (Možnost č. 1)
Pro výpočet parametrů aab lineární regrese (výpočet lze provést pomocí kalkulačky).
řešit soustavu normálních rovnic s ohledem na A A b:
Na základě počátečních údajů počítáme :
:
y X yx x2 y2 A i l 68,8 45,1 3102,88 2034,01 4733,44 61,3 7,5 10,9 2 61,2 59,0 3610,80 3481,00 3745,44 56,5 4,7 7,7 3 59,9 57,2 3426,28 3271,84 3588,01 57,1 2,8 4,7 4 56,7 61,8 3504,06 3819,24 3214,89 55,5 1,2 2,1 5 55,0 58,8 3234,00 3457,44 3025,00 56,5 -1,5 2,7 6 54,3 47,2 2562,96 2227,84 2948,49 60,5 -6,2 11,4 7 49,3 55,2 2721,36 3047,04 2430,49 57,8 -8,5 17,2 Celkový 405,2 384,3 22162,34 21338,41 23685,76 405,2 0,0 56,7 St hodnota (celkem/n) 57,89 54,90 3166,05 3048,34 3383,68 X X 8,1 s 5,74 5,86 X X X X X X s2 32,92 34,34 X X X X X X 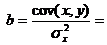

Regresní rovnice: y= 76,88 - 0,35X. Se zvýšením průměrné denní mzdy o 1 rub. podíl výdajů na nákup potravinářských výrobků se snižuje v průměru o 0,35 % bodu.
Vypočítejte lineární koeficient párové korelace:
Komunikace je umírněná, obrácená.
Definujme koeficient determinace:
12,7% odchylka ve výsledku je vysvětlena odchylkou x faktoru. Dosazení skutečných hodnot do regresní rovnice X, určit teoretické (vypočtené) hodnoty . Najděte hodnotu průměrné aproximační chyby:
V průměru se vypočtené hodnoty odchylují od skutečných o 8,1 %.
Vypočítejme F-kritérium:
od 1< F < ¥ , je třeba zvážit F -1 .
Výsledná hodnota ukazuje na nutnost přijmout hypotézu Ale ouha náhodný charakter odhalené závislosti a statistická nevýznamnost parametrů rovnice a ukazatele těsnosti spoje.
1b. Sestavení výkonového modelu předchází procedura linearizace proměnných. V příkladu se linearizace provádí logaritmováním obou stran rovnice:
KdeY=lg(y), X=lg(x), C=lg(a).Pro výpočty používáme data v tabulce. 1.3.
Tabulka 1.3
Y X YX Y2 x2 A i 1 1,8376 1,6542 3,0398 3,3768 2,7364 61,0 7,8 60,8 11,3 2 1,7868 1,7709 3,1642 3,1927 3,1361 56,3 4,9 24,0 8,0 3 1,7774 1,7574 3,1236 3,1592 3,0885 56,8 3,1 9,6 5,2 4 1,7536 1,7910 3,1407 3,0751 3,2077 55,5 1,2 1,4 2,1 5 1,7404 1,7694 3,0795 3,0290 3,1308 56,3 -1,3 1,7 2,4 6 1,7348 1,6739 2,9039 3,0095 2,8019 60,2 -5,9 34,8 10,9 7 1,6928 1,7419 2,9487 2,8656 3,0342 57,4 -8,1 65,6 16,4 Celkový 12,3234 12,1587 21,4003 21,7078 21,1355 403,5 1,7 197,9 56,3 Průměrná hodnota 1,7605 1,7370 3,0572 3,1011 3,0194 X X 28,27 8,0 σ 0,0425 0,0484 X X X X X X X σ2 0,0018 0,0023 X X X X X X X Vypočítejte C a b:
Dostaneme lineární rovnici: .
.
Jeho potencováním získáme:
Dosazením do této rovnice skutečnými hodnotami X, získáme teoretické hodnoty výsledku. Na jejich základě vypočítáme ukazatele: těsnost spoje - index korelace a průměrnou chybu aproximace
Charakteristiky mocninného modelu naznačují, že popisuje vztah poněkud lépe než lineární funkce.1c. Konstrukce rovnice exponenciální křivky
předchází postup pro linearizaci proměnných při logaritmování obou částí rovnice:

Pro výpočty používáme data z tabulky.Y X Yx Y2 x2 A i 1 1,8376 45,1 82,8758 3,3768 2034,01 60,7 8,1 65,61 11,8 2 1,7868 59,0 105,4212 3,1927 3481,00 56,4 4,8 23,04 7,8 3 1,7774 57,2 101,6673 3,1592 3271,84 56,9 3,0 9,00 5,0 4 1,7536 61,8 108,3725 3,0751 3819,24 55,5 1,2 1,44 2,1 5 1,7404 58,8 102,3355 3,0290 3457,44 56,4 -1,4 1,96 2,5 6 1,7348 47,2 81,8826 3,0095 2227,84 60,0 -5,7 32,49 10,5 7 1,6928 55,2 93,4426 2,8656 3047,04 57,5 -8,2 67,24 16,6 Celkový 12,3234 384,3 675,9974 21,7078 21338,41 403,4 -1,8 200,78 56,3 St zn. 1,7605 54,9 96,5711 3,1011 3048,34 X X 28,68 8,0 σ 0,0425 5,86 X X X X X X X σ2 0,0018 34,339 X X X X X X X Hodnoty regresních parametrů A a Včinil:
Získá se lineární rovnice: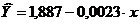 .
Výslednou rovnici potencujeme a zapisujeme v obvyklém tvaru:
.
Výslednou rovnici potencujeme a zapisujeme v obvyklém tvaru:
Těsnost spojení odhadujeme pomocí korelačního indexu: