Standard regression analysis in STATISTICA. Regression statistics
It is assumed that - independent variables (predictors, explanatory variables) influence the values of - dependent variables (responses, explained variables). According to the available empirical data, it is required to construct a function that would approximately describe the change when changing:
.
It is assumed that the set of admissible functions from which is selected is parametric:
 ,
,
where is an unknown parameter (generally speaking, multidimensional). When constructing, we will assume that
 , (1)
, (1)
where the first term is a natural change from , and the second is a random component with zero average; is the conditional mathematical expectation given the known and is called regression on .
Let n times the values of the factors and the corresponding values of the variable are measured y; it is assumed that
(2)
(second index at x refers to the factor number, and the first refers to the observation number); it is also assumed that
 (3)
(3)
those. - uncorrelated random variables. It is convenient to write relations (2) in matrix form:
, (4)
Where  - column vector of values of the dependent variable, t- transposition symbol,
- column vector of values of the dependent variable, t- transposition symbol,  - column vector (dimensions k) unknown regression coefficients, - vector of random deviations,
- column vector (dimensions k) unknown regression coefficients, - vector of random deviations,

-matrix; V i The th line contains the values of the independent variables in i th observation, the first variable is a constant equal to 1.
to the beginning
Estimation of regression coefficients
Let us construct an estimate for the vector so that the vector of estimates of the dependent variable differs minimally (in the sense of the squared norm of the difference) from the vector of given values:
.
The solution is (if the rank of the matrix is k+1) grade
 (5)
(5)
It is easy to check that it is unbiased.
to the beginning
Checking the adequacy of the constructed regression model
There is the following relationship between the value , the value from the regression model and the value of the trivial estimate of the sample mean:
 ,
,
Where .
Essentially, the term on the left side defines the overall error relative to the mean. The first term on the right side () determines the error associated with the regression model, and the second () determines the error associated with random deviations and the unexplained model built.
Dividing both parts into a complete variation of players  , we obtain the coefficient of determination:
, we obtain the coefficient of determination:
 (6)
(6)
The coefficient shows the quality of fit of the regression model to the observed values. If , then regression does not improve the quality of prediction compared to trivial prediction.
The other extreme case means an exact fit: all , i.e. all observation points lie on the regression plane.
However, the value increases with the number of variables (regressors) in the regression, which does not mean an improvement in the quality of prediction, and therefore an adjusted coefficient of determination is introduced
 (7)
(7)
Its use is more correct for comparing regressions when the number of variables (regressors) changes.
Confidence intervals for regression coefficients. The standard error of the estimate is the value for which the estimate
 (8)
(8)
where is the diagonal element of the matrix Z. If the errors are normally distributed, then, due to properties 1) and 2) given above, the statistics
 (9)
(9)
distributed according to Student's law with degrees of freedom, and therefore the inequality
, (10)
where is the quantile of the level of this distribution, specifies the confidence interval for with the confidence level.
Testing the hypothesis about zero values of regression coefficients. To test the hypothesis about the absence of any linear relationship between and a set of factors, i.e. about the simultaneous equality to zero of all coefficients, except for coefficients, when a constant is used, statistics is used
 , (11)
, (11)
distributed, if true, according to Fisher's law with k and degrees of freedom. rejected if
 (12)
(12)
where is the quantile of the level.
to the beginning
Description of data and problem statement
Source data file tube_dataset.sta contains 10 variables and 33 observations. See fig. 1.

Rice. 1. Initial data table from the file tube_dataset.sta
The name of the observations indicates the time interval: quarter and year (before and after the point, respectively). Each observation contains data for the corresponding time interval. 10, the “Quarter” variable duplicates the quarter number in the observation name. The list of variables is given below.

Target: Build a regression model for variable No. 9 “Pipe consumption”.
Solution steps:
1) First, we will conduct an exploratory analysis of the available data for outliers and insignificant data (construction of line graphs and scatter plots).
2) Let's check the presence of possible dependencies between observations and between variables (construction of correlation matrices).
3) If observations form groups, then for each group we will build a regression model for the variable “Pipe consumption” (multiple regression).
Let's renumber the variables in order in the table. The dependent variable (response) will be called the “Pipe consumption” variable. Let's call all other variables independent (predictors).
to the beginning
Solving the problem step by step
Step 1. The scatterplots (see Fig. 2) did not reveal any obvious outliers. At the same time, many graphs clearly show a linear relationship. There are also missing data for “Pipe Consumption” in 4 quarters of 2000.

Rice. 2. Scatter diagram of the dependent variable (No. 9) and the number of wells (No. 8)
The number after the symbol E in the marks along the X axis indicates the power of 10, which determines the order of the values of variable No. 8 (Number of operating wells). In this case we are talking about a value of about 100,000 wells (10 to the 5th power).
In the scatterplot in Fig. 3 (see below) 2 clouds of points are clearly visible, and each of them has a clear linear relationship.
It is clear that variable No. 1 will most likely be included in the regression model, because Our task is to identify precisely the linear relationship between the predictors and the response.

Rice. 3. Scatterplot of the dependent variable (No. 9) and Investment in the oil industry (No. 1)
Step 2. Let's build linear graphs of all variables depending on time. The graphs show that data for many variables varies greatly depending on the quarter number, but the growth continues from year to year.
The obtained result confirms the assumptions obtained on the basis of Fig. 3.

Rice. 4. Line graph of the 1st variable versus time
In particular, in Fig. 4 a linear graph is plotted for the first variable.
Step 3. According to the results of Fig. 3 and fig. 4, we divide the observations into 2 groups, according to variable No. 10 “Quarter”. The first group will include data for quarters 1 and 4, and the second group will include data for quarters 2 and 3.
To split observations according to quarters into 2 tables, use the item Data/Subset/Random. Here, as observations, we need to indicate conditions on the values of the QUARTER variable. See rice. 5.
According to the specified conditions, observations will be copied to a new table. In the line below you can indicate specific observation numbers, but in our case this will take a lot of time.

Rice. 5. Selecting a subset of observations from the table
As a given condition, we set:
V10 = 1 OR V10 = 4
V10 is the 10th variable in the table (V0 is the observation column). Essentially, we check each observation in the table whether it belongs to the 1st or 4th quarter or not. If we want to select a different subset of observations, we can either change the condition to:
V10 = 2 OR V10 = 3
or move the first condition to the exclusion rules.
Clicking OK, we will first receive a table with data only for the 1st and 4th quarter, and then a table with data for the 2nd and 3rd quarter. Let's save them under names 1_4.sta And 2_3.sta via tab File/Save As.
Next, we will work with two tables and the results of regression analysis for both tables can be compared.
Step 4. We will construct a correlation matrix for each of the groups in order to check the assumption of linear dependence and take into account possible strong correlations between variables when constructing a regression model. Since there are missing data, the correlation matrix was constructed with the option of pairwise deletion of missing data. See fig. 6.

Rice. 6. Correlation matrix for the first 9 variables based on data from the 1st and 4th quarters
From the correlation matrix in particular, it is clear that some variables are very strongly correlated with each other.
It is worth noting that the reliability of large correlation values is only possible if there are no outliers in the original table. Therefore, scatterplots for the dependent variable and all other variables must be taken into account in correlation analysis.
For example, variable No. 1 and No. 2 (Investment in the oil and gas industries, respectively). See Fig. 7 (or, for example, Fig. 8).

Rice. 7. Scatter diagram for variable No. 1 and No. 2

Rice. 8. Scatter diagram for variable No. 1 and No. 7
This dependence is easily explained. The high correlation coefficient between oil and gas production volumes is also clear.
A high correlation coefficient between variables (multicollinearity) must be taken into account when constructing a regression model. Here, large errors can occur when calculating regression coefficients (poorly conditioned matrix when calculating estimates using OLS).
Here are the most common solutions multicollinearity:
1) Ridge regression.
This option is set when building multiple regression. The number is a small positive number. The OLS estimate in this case is equal to:
 ,
,
Where Y– vector with the values of the dependent variable, X is a matrix containing the values of predictors in columns, and is an identity matrix of order n+1. (n is the number of predictors in the model).
The ill-conditioning of the matrix with ridge regression is significantly reduced.
2) Elimination of one of the explanatory variables.
In this case, one explanatory variable that has a high pairwise correlation coefficient (r>0.8) with another predictor is excluded from the analysis.
3) Using stepwise procedures with inclusion/exclusion of predictors.
Typically, in such cases, either ridge regression is used (it is set as an option when constructing a multiple regression), or, based on the correlation values, explanatory variables that have a high pairwise correlation coefficient (r > 0.8) are excluded, or stepwise regression with inclusion/exclusion variables.
Step 5. Now let's build a regression model using the drop-down menu tab ( Analysis/Multiple Regression). We will indicate “Pipe consumption” as the dependent variable, and all the others as independent variables. See fig. 9.

Rice. 9. Construction of multiple regression for table 1_4.sta
Multiple regression can be done step by step. In this case, the model will step by step include (or exclude) variables that make the largest (smallest) contribution to the regression at a given step.
This option also allows you to stop at a step when the coefficient of determination is not yet the greatest, but all the variables of the model are already significant. See fig. 10.

Rice. 10. Construction of multiple regression for table 1_4.sta
It is especially worth noting that stepwise regression with inclusion, in the case where the number of variables is greater than the number of observations, is the only way to build a regression model.
Setting a zero value for the free term of a regression model is used if the very idea of the model implies a zero response value when all predictors are equal to 0. Most often, such situations occur in economic problems.
In our case, we will include the free term in the model.

Rice. 11. Construction of multiple regression for table 1_4.sta
As model parameters we choose Step by step with exception(Fon = 11, Foff = 10), with ridge regression (lambda = 0.1). And for each group we will build a regression model. See Figure 11.
Results in the form Final regression table(see also Fig. 14) are presented in Fig. 12 and Fig. 13. They are obtained at the last regression step.
Step 6.Checking the adequacy of the model
Please note that, despite the significance of all variables in the regression model (p-level< 0.05 – подсвечены красным цветом), коэффициент детерминации R2 существенно меньше у первой группы наблюдений.
The coefficient of determination essentially shows what proportion of the response variance is explained by the influence of predictors in the constructed model. The closer R2 is to 1, the better the model.
Fisher's F-statistics is used to test the hypothesis about zero values of regression coefficients (i.e., the absence of any linear relationship between and a set of factors except the coefficient). The hypothesis is rejected at a low level of significance.
In our case (see Fig. 12), the F-statistic value = 13.249 at the p significance level< 0,00092, т.е. гипотеза об отсутствии линейной связи отклоняется.

Rice. 12. Results of regression analysis of data for the 1st and 4th quarter

Rice. 13. Results of regression analysis of data for the 2nd and 3rd quarters
Step 7 Now let's analyze the residuals of the resulting model. The results obtained from the analysis of residuals are an important addition to the value of the coefficient of determination when checking the adequacy of the constructed model.
For simplicity, we will consider only the group divided into blocks numbered 2 and 3, because the second group is studied in a similar way.
In the window shown in Fig. 14, on tab Residuals/predicted/observed values click on the button Residue analysis, and then click on the button Remains and predicted. (See Fig. 15)
Button Residue analysis will be active only if the regression is obtained in the last step. More often it turns out to be important to obtain a regression model in which all predictors are significant than to continue building the model (increasing the coefficient of determination) and obtain insignificant predictors.
In this case, when the regression does not stop at the last step, you can artificially set the number of steps in the regression.

Rice. 14. Window with multiple regression results for data for the 2nd and 3rd quarters

Rice. 15. Residuals and predicted values of the regression model based on data from the 2nd and 3rd quarters
Let us comment on the results presented in Fig. 15. The important column is Remnants(difference of the first 2 columns). Large residuals for many observations and the presence of an observation with a small residual may indicate the latter as an outlier.
In other words, residual analysis is needed so that deviations from assumptions that threaten the validity of the analysis results can be easily detected.

Rice. 16. Residuals and predicted values of the regression model based on data from quarters 2 and 3 + 2 limits of 0.95 confidence interval
At the end we present a graph illustrating the data obtained from the table in Fig. 16. Here 2 variables are added: UCB and LCB – 0.95 top. and lower Dov. interval.
UBC = V2+1.96*V6
LBC = V2-1.96*V6
And the last four observations were deleted.
Let's build a linear graph with variables ( Graphs/2M Graphs/Line graphs for variables)
1) Observed value (V1)
2) Predicted value (V2)
3) UCB (V9)
4) LCB (V10)
The result is shown in Fig. 17. Now it is clear that the constructed regression model reflects the real consumption of pipes quite well, especially based on the results of the recent past.
This means that in the near future the real values may be approximated by the model ones.
Let us note one important point. In forecasting using regression models, the base time interval is always important. In the problem under consideration, neighborhoods were selected.
Accordingly, when constructing a forecast, the predicted values will also be obtained by quarter. If you need to get a forecast for the year, you will have to forecast for 4 quarters and at the end a big error will accumulate.
A similar problem can be solved in a similar way, first by only aggregating data from quarters to years (for example, by averaging). For this task, the approach is not very correct, since there will only be 8 observations left on which the regression model will be built. See Figure 18.

Rice. 17. Observed and predicted values together with 0.95 top. and lower trust at intervals (data for 2nd and 3rd quarters)

Rice. 18. Observed and predicted values together with 0.95 top. and lower trust intervals (data by year)
Most often, this approach is used when aggregating data by month, with initial data by day.
It should be remembered that all methods of regression analysis can detect only numerical dependencies, and not the underlying causal relationships. Therefore, the answer to the question about the significance of the variables in the resulting model remains with an expert in this field, who, in particular, is able to take into account the influence of factors that may not be included in this table.
In his works dating back to 1908. He described it using the example of the work of an agent selling real estate. In his records, the house sales specialist kept track of a wide range of input data for each specific building. Based on the results of the auction, it was determined which factor had the greatest influence on the transaction price.
Analysis large quantity deals given interesting results. The final price was influenced by many factors, sometimes leading to paradoxical conclusions and even obvious “outliers” when a house with high initial potential was sold at a reduced price.
The second example of the application of such an analysis is the work of which was entrusted with determining employee remuneration. The complexity of the task lay in the fact that it required not the distribution of a fixed amount to everyone, but its strict correspondence to the specific work performed. The appearance of many problems with practically similar solutions required a more detailed study of them at the mathematical level.
A significant place was allocated to the section “regression analysis”, it combined practical methods, used to study dependencies that fall under the concept of regression. These relationships are observed between data obtained from statistical studies.
Among the many problems to be solved, he sets three main goals: determining the regression equation general view; constructing estimates of parameters that are unknowns that are part of the regression equation; testing of statistical regression hypotheses. In the course of studying the relationship that arises between a pair of quantities obtained as a result of experimental observations and constituting a series (set) of the type (x1, y1), ..., (xn, yn), they rely on the provisions of regression theory and assume that for one quantity Y there is a certain probability distribution, while the other X remains fixed.
The result Y depends on the value of the variable X; this dependence can be determined by various patterns, while the accuracy of the results obtained is influenced by the nature of the observations and the purpose of the analysis. The experimental model is based on certain assumptions that are simplified but plausible. The main condition is that the parameter X is a controlled quantity. Its values are set before the start of the experiment.
If a pair of uncontrolled variables XY is used during the experiment, then regression analysis is carried out in the same way, but methods are used to interpret the results, during which the relationship of the random variables under study is studied mathematical statistics are not an abstract topic. They find application in life in various spheres of human activity.
In the scientific literature, the term linear regression analysis is widely used to define the above method. For variable X, the term regressor or predictor is used, and dependent Y variables are also called criterion variables. This terminology reflects only the mathematical dependence of the variables, but not the cause-and-effect relationship.
Regression analysis is the most common method used in processing the results of a wide variety of observations. Physical and biological dependencies are studied by means this method, it is implemented both in economics and technology. Lots of other fields use models regression analysis. Analysis of variance, statistical analysis multidimensional work closely with this method of study.
y=f(x), when each value of the independent variable x corresponds to one specific value of quantity y, with regression connection to the same value x may correspond depending on the case to different values of the quantity y. If for each value there is n i (\displaystyle n_(i)) values y i 1 …y in 1 magnitude y, then the dependence of the arithmetic averages y ¯ i = (y i 1 + . . . + y i n 1) / n i (\displaystyle (\bar (y))_(i)=(y_(i1)+...+y_(in_(1))) /n_(i)) from x = x i (\displaystyle x=x_(i)) and is a regression in the statistical sense of the term.Encyclopedic YouTube
-
1 / 5
This term in statistics was first used by Francis Galton (1886) in connection with the study of the inheritance of human physical characteristics. Human height was taken as one of the characteristics; it was found that, in general, the sons of tall fathers, not surprisingly, turned out to be taller than the sons of short fathers. What was more interesting was that the variation in the heights of sons was smaller than the variation in the heights of fathers. This is how the tendency of sons’ heights to return to average was manifested ( regression to mediocrity), that is, “regression”. This fact was demonstrated by calculating the average height of the sons of fathers whose height is 56 inches, by calculating the average height of the sons of fathers who are 58 inches tall, etc. The results were then plotted on a plane, along the ordinate axis of which the average height of the sons was plotted. , and on the x-axis - the values of the average height of fathers. The points (approximately) lie on a straight line with a positive angle of inclination less than 45°; it is important that the regression was linear.
Description
Suppose we have a sample from a bivariate distribution of a pair of random variables ( X, Y). Straight line in plane ( x, y) was a selective analogue of the function
g (x) = E (Y ∣ X = x) . (\displaystyle g(x)=E(Y\mid X=x).) E (Y ∣ X = x) = μ 2 + ϱ σ 2 σ 1 (x − μ 1) , (\displaystyle E(Y\mid X=x)=\mu _(2)+\varrho (\frac ( \sigma _(2))(\sigma _(1)))(x-\mu _(1)),) v a r (Y ∣ X = x) = σ 2 2 (1 − ϱ 2) . (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).)In this example regression Y on X is a linear function. If regression Y on X is different from linear, then the given equations are a linear approximation of the true regression equation.
In general, a regression of one random variable on another is not necessarily linear. It is also not necessary to limit yourself to a couple of random variables. Statistical regression problems involve determining the general form of the regression equation, constructing estimates of the unknown parameters included in the regression equation, and testing statistical hypotheses about the regression. These problems are addressed within the framework of regression analysis.
A simple example regression Y By X is the relationship between Y And X, which is expressed by the relation: Y=u(X)+ε, where u(x)=E(Y | X=x), A random variables X and ε are independent. This representation is useful when designing an experiment to study functional connectivity y=u(x) between non-random quantities y And x. In practice, usually the regression coefficients in Eq. y=u(x) are unknown and are estimated from experimental data.
Linear regression
Let's imagine the dependence y from x in the form of a first order linear model:
y = β 0 + β 1 x + ε . (\displaystyle y=\beta _(0)+\beta _(1)x+\varepsilon .)We will assume that the values x are determined without error, β 0 and β 1 are the model parameters, and ε is the error, the distribution of which obeys the normal law with zero mean value and constant deviation σ 2. The values of the parameters β are not known in advance and must be determined from a set of experimental values ( x i, y i), i=1, …, n. Thus we can write:
y i ^ = b 0 + b 1 x i , i = 1 , … , n (\displaystyle (\widehat (y_(i)))=b_(0)+b_(1)x_(i),i=1,\ dots,n)where means the value predicted by the model y given x, b 0 and b 1 - sample estimates of model parameters. Let us also define e i = y i − y i ^ (\displaystyle e_(i)=y_(i)-(\widehat (y_(i))))- approximation error value for i (\displaystyle i) th observation.
The least squares method gives the following formulas for calculating the parameters of a given model and their deviations:
b 1 = ∑ i = 1 n (x i − x ¯) (y i − y ¯) ∑ i = 1 n (x i − x ¯) 2 = c o v (x , y) σ x 2 ; (\displaystyle b_(1)=(\frac (\sum _(i=1)^(n)(x_(i)-(\bar (x)))(y_(i)-(\bar (y) )))(\sum _(i=1)^(n)(x_(i)-(\bar (x)))^(2)))=(\frac (\mathrm (cov) (x,y ))(\sigma _(x)^(2)));) b 0 = y ¯ − b 1 x ¯ ; (\displaystyle b_(0)=(\bar (y))-b_(1)(\bar (x));) s e 2 = ∑ i = 1 n (y i − y ^) 2 n − 2 ; (\displaystyle s_(e)^(2)=(\frac (\sum _(i=1)^(n)(y_(i)-(\widehat (y)))^(2))(n- 2));) s b 0 = s e 1 n + x ¯ 2 ∑ i = 1 n (x i − x ¯) 2 ; (\displaystyle s_(b_(0))=s_(e)(\sqrt ((\frac (1)(n))+(\frac ((\bar (x))^(2))(\sum _ (i=1)^(n)(x_(i)-(\bar (x)))^(2)))));) s b 1 = s e 1 ∑ i = 1 n (x i − x ¯) 2 , (\displaystyle s_(b_(1))=s_(e)(\sqrt (\frac (1)(\sum _(i=1 )^(n)(x_(i)-(\bar (x)))^(2)))),)here the average values are determined as usual: x ¯ = ∑ i = 1 n x i n (\displaystyle (\bar (x))=(\frac (\sum _(i=1)^(n)x_(i))(n))), y ¯ = ∑ i = 1 n y i n (\displaystyle (\bar (y))=(\frac (\sum _(i=1)^(n)y_(i))(n))) And s e 2 denotes the regression residual, which is an estimate of the variance σ 2 if the model is correct.
Standard errors of regression coefficients are used similarly standard error average - to find confidence intervals and test hypotheses. We use, for example, the Student’s test to test the hypothesis that the regression coefficient is equal to zero, that is, that it is insignificant for the model. Student statistics: t = b / s b (\displaystyle t=b/s_(b)). If the probability for the obtained value and n−2 degrees of freedom is quite small, for example,<0,05 - гипотеза отвергается. Напротив, если нет оснований отвергнуть гипотезу о равенстве нулю, скажем, b 1 (\displaystyle b_(1))- there is reason to think about the existence of the desired regression, at least in this form, or about collecting additional observations. If the free term is equal to zero b 0 (\displaystyle b_(0)), then the straight line passes through the origin and the estimate of the slope is equal to
b = ∑ i = 1 n x i y i ∑ i = 1 n x i 2 (\displaystyle b=(\frac (\sum _(i=1)^(n)x_(i)y_(i))(\sum _(i= 1)^(n)x_(i)^(2)))),and its standard error
s b = s e 1 ∑ i = 1 n x i 2 . (\displaystyle s_(b)=s_(e)(\sqrt (\frac (1)(\sum _(i=1)^(n)x_(i)^(2)))).)Usually the true values of the regression coefficients β 0 and β 1 are not known. Only their estimates are known b 0 and b 1. In other words, the true regression line may work differently than the one built from sample data. You can calculate the confidence region for the regression line. For any value x corresponding values y normally distributed. The average is the value of the regression equation y ^ (\displaystyle (\widehat (y))). The uncertainty of its estimate is characterized by the standard regression error:
s y ^ = s e 1 n + (x − x ¯) 2 ∑ i = 1 n (x i − x ¯) 2 ; (\displaystyle s_(\widehat (y))=s_(e)(\sqrt ((\frac (1)(n))+(\frac ((x-(\bar (x)))^(2) )(\sum _(i=1)^(n)(x_(i)-(\bar (x)))^(2)))));)Now you can calculate the -percentage confidence interval for the value of the regression equation at point x:
y ^ − t (1 − α / 2 , n − 2) s y ^< y < y ^ + t (1 − α / 2 , n − 2) s y ^ {\displaystyle {\widehat {y}}-t_{(1-\alpha /2,n-2)}s_{\widehat {y}}Where t(1−α/2, n−2) - t-value of the Student distribution. The figure shows a regression line constructed using 10 points (solid dots), as well as the 95% confidence region of the regression line, which is limited by dotted lines. With 95% probability we can say that the true line is located somewhere inside this area. Or otherwise, if we collect similar data sets (indicated by circles) and build regression lines on them (indicated in blue), then in 95 cases out of 100 these straight lines will not leave the confidence region. (Click on the picture to visualize) Please note that some points were outside the confidence region. This is completely natural, since we are talking about the confidence region of the regression line, and not the values themselves. The spread of values consists of the spread of values around the regression line and the uncertainty of the position of this line itself, namely:
s Y = s e 1 m + 1 n + (x − x ¯) 2 ∑ i = 1 n (x i − x ¯) 2 ; (\displaystyle s_(Y)=s_(e)(\sqrt ((\frac (1)(m))+(\frac (1)(n))+(\frac ((x-(\bar (x )))^(2))(\sum _(i=1)^(n)(x_(i)-(\bar (x)))^(2)))));)Here m- frequency of measurement y given x. AND 100 ⋅ (1 − α 2) (\displaystyle 100\cdot \left(1-(\frac (\alpha )(2))\right))-percentage confidence interval (forecast interval) for the average of m values y will:
y ^ − t (1 − α / 2 , n − 2) s Y< y < y ^ + t (1 − α / 2 , n − 2) s Y {\displaystyle {\widehat {y}}-t_{(1-\alpha /2,n-2)}s_{Y}In the figure, this 95% confidence region at m=1 is limited by solid lines. 95% of all possible values of the quantity fall into this area y in the studied range of values x.
Some more statistics
It can be strictly proven that if the conditional expectation E (Y ∣ X = x) (\displaystyle E(Y\mid X=x)) some two-dimensional random variable ( X, Y) is a linear function of x (\displaystyle x), then this conditional expectation is necessarily representable in the form E (Y ∣ X = x) = μ 2 + ϱ σ 2 σ 1 (x − μ 1) (\displaystyle E(Y\mid X=x)=\mu _(2)+\varrho (\frac (\ sigma _(2))(\sigma _(1)))(x-\mu _(1))), Where E(X)=μ 1 , E(Y)=μ 2 , var( X)=σ 1 2 , var( Y)=σ 2 2 , cor( X, Y)=ρ.
Moreover, for the previously mentioned linear model Y = β 0 + β 1 X + ε (\displaystyle Y=\beta _(0)+\beta _(1)X+\varepsilon ), Where X (\displaystyle X) and are independent random variables, and ε (\displaystyle \varepsilon) has zero expectation (and arbitrary distribution), it can be proven that E (Y ∣ X = x) = β 0 + β 1 x (\displaystyle E(Y\mid X=x)=\beta _(0)+\beta _(1)x). Then, using the previously stated equality, we can obtain formulas for and: β 1 = ϱ σ 2 σ 1 (\displaystyle \beta _(1)=\varrho (\frac (\sigma _(2))(\sigma _(1)))),
β 0 = μ 2 − β 1 μ 1 (\displaystyle \beta _(0)=\mu _(2)-\beta _(1)\mu _(1))
If from somewhere it is known a priori that a set of random points on the plane is generated by a linear model, but with unknown coefficients β 0 (\displaystyle \beta _(0)) And β 1 (\displaystyle \beta _(1)), you can obtain point estimates of these coefficients using the specified formulas. To do this, instead of mathematical expectations, variances and correlations of random variables, these formulas X And Y we need to substitute their unbiased estimates. The resulting estimation formulas will exactly coincide with the formulas derived based on the least squares method.
The main feature of regression analysis: with its help, you can obtain specific information about what form and nature the relationship between the variables under study has.
Sequence of stages of regression analysis
Let us briefly consider the stages of regression analysis.
Problem formulation. At this stage, preliminary hypotheses about the dependence of the phenomena under study are formed.
Definition of dependent and independent (explanatory) variables.
Collection of statistical data. Data must be collected for each of the variables included in the regression model.
Formulation of a hypothesis about the form of connection (simple or multiple, linear or nonlinear).
Definition regression functions (consists in calculating the numerical values of the parameters of the regression equation)
Assessing the accuracy of regression analysis.
Interpretation of the results obtained. The obtained results of regression analysis are compared with preliminary hypotheses. The correctness and credibility of the results obtained are assessed.
Predicting unknown values of a dependent variable.
Using regression analysis, it is possible to solve the problem of forecasting and classification. Predicted values are calculated by substituting the values of explanatory variables into the regression equation. The classification problem is solved in this way: the regression line divides the entire set of objects into two classes, and that part of the set where the function value is greater than zero belongs to one class, and the part where it is less than zero belongs to another class.
Regression Analysis Problems
Let's consider the main tasks of regression analysis: establishing the form of dependence, determining regression functions, estimation of unknown values of the dependent variable.
Establishing the form of dependence.
The nature and form of the relationship between variables can form the following types of regression:
positive linear regression (expressed in uniform growth of the function);
positive uniformly increasing regression;
positive uniformly increasing regression;
negative linear regression (expressed as a uniform decline in the function);
negative uniformly accelerated decreasing regression;
negative uniformly decreasing regression.
However, the described varieties are usually not found in pure form, but in combination with each other. In this case, we talk about combined forms of regression.
Definition of the regression function.
The second task comes down to finding out the effect on the dependent variable of the main factors or causes, all other things being equal, and subject to the exclusion of the influence of random elements on the dependent variable. Regression function is defined in the form of a mathematical equation of one type or another.
Estimation of unknown values of the dependent variable.
The solution to this problem comes down to solving a problem of one of the following types:
Estimation of the values of the dependent variable within the considered interval of the initial data, i.e. missing values; in this case, the interpolation problem is solved.
Estimation of future values of the dependent variable, i.e. finding values outside the specified interval of the source data; in this case, the problem of extrapolation is solved.
Both problems are solved by substituting the found parameter estimates for the values of independent variables into the regression equation. The result of solving the equation is an estimate of the value of the target (dependent) variable.
Let's look at some of the assumptions that regression analysis relies on.
Linearity assumption, i.e. the relationship between the variables under consideration is assumed to be linear. So, in this example, we plotted a scatterplot and were able to see a clear linear relationship. If on the scatter diagram of variables we see a clear absence linear connection, i.e. If there is a nonlinear relationship, nonlinear analysis methods should be used.
Normality Assumption leftovers. It assumes that the distribution of the difference between predicted and observed values is normal. To visually determine the nature of the distribution, you can use histograms leftovers.
When using regression analysis, its main limitation should be considered. It consists in the fact that regression analysis allows us to detect only dependencies, and not the connections underlying these dependencies.
Regression analysis allows you to estimate the strength of the relationship between variables by calculating the estimated value of a variable based on several known values.
Regression equation.
The regression equation looks like this: Y=a+b*X
Using this equation, the variable Y is expressed in terms of a constant a and the slope of the line (or slope) b, multiplied by the value of the variable X. The constant a is also called the intercept term, and the slope is the regression coefficient or B-coefficient.
In most cases (if not always) there is a certain scatter of observations relative to the regression line.
Remainder is the deviation of an individual point (observation) from the regression line (predicted value).
To solve the problem of regression analysis in MS Excel, select from the menu Service"Analysis package" and the Regression analysis tool. We set the input intervals X and Y. The input interval Y is the range of dependent analyzed data, it must include one column. The input interval X is the range of independent data that needs to be analyzed. The number of input ranges should not exceed 16.
At the output of the procedure in the output range we obtain the report given in table 8.3a-8.3v.
CONCLUSION OF RESULTS
Table 8.3a. Regression statistics
Regression statistics
Plural R
R-square
Normalized R-squared
Standard error
Observations
Let's first look at the top part of the calculations presented in table 8.3a, - regression statistics.
Magnitude R-square, also called the measure of certainty, characterizes the quality of the resulting regression line. This quality is expressed by the degree of correspondence between the source data and the regression model (calculated data). The measure of certainty is always within the interval.
In most cases the value R-square is between these values, called extreme, i.e. between zero and one.
If the value R-square close to unity, this means that the constructed model explains almost all the variability in the corresponding variables. Conversely, the meaning R-square, close to zero, means poor quality of the constructed model.
In our example, the measure of certainty is 0.99673, which indicates a very good fit of the regression line to the original data.
plural R - multiple correlation coefficient R - expresses the degree of dependence of the independent variables (X) and the dependent variable (Y).
Plural R is equal to the square root of the coefficient of determination; this quantity takes values in the range from zero to one.
In simple linear regression analysis plural R equal to the Pearson correlation coefficient. Really, plural R in our case, it is equal to the Pearson correlation coefficient from the previous example (0.998364).
Table 8.3b. Regression coefficients
Odds
Standard error
t-statistic
Y-intersection
Variable X 1
* A truncated version of the calculations is provided
Now consider the middle part of the calculations presented in table 8.3b. Here the regression coefficient b (2.305454545) and the displacement along the ordinate axis are given, i.e. constant a (2.694545455).
Based on the calculations, we can write the regression equation as follows:
Y= x*2.305454545+2.694545455
The direction of the relationship between variables is determined based on the signs (negative or positive) of the regression coefficients (coefficient b).
If the sign of the regression coefficient is positive, the relationship between the dependent variable and the independent variable will be positive. In our case, the sign of the regression coefficient is positive, therefore, the relationship is also positive.
If the sign of the regression coefficient is negative, the relationship between the dependent variable and the independent variable is negative (inverse).
IN table 8.3c. output results are presented leftovers. In order for these results to appear in the report, you must activate the “Residuals” checkbox when running the “Regression” tool.
WITHDRAWAL OF THE REST
Table 8.3c. Leftovers
Observation
Predicted Y
Leftovers
Standard balances
Using this part of the report, we can see the deviations of each point from the constructed regression line. Largest absolute value remainder in our case - 0.778, the smallest - 0.043. To better interpret these data, we will use the graph of the original data and the constructed regression line presented in rice. 8.3. As you can see, the regression line is quite accurately “fitted” to the values of the original data.
It should be taken into account that the example under consideration is quite simple and it is not always possible to qualitatively construct a linear regression line.
Rice. 8.3. Source data and regression line
The problem of estimating unknown future values of the dependent variable based on known values of the independent variable has remained unconsidered, i.e. forecasting problem.
Having a regression equation, the forecasting problem is reduced to solving the equation Y= x*2.305454545+2.694545455 with known values of x. The results of predicting the dependent variable Y six steps ahead are presented in table 8.4.
Table 8.4. Results of forecasting variable Y
Y(predicted)
Thus, as a result of using regression analysis in Microsoft Excel, we:
built a regression equation;
established the form of dependence and direction of connection between variables - positive linear regression, which is expressed in a uniform growth of the function;
established the direction of the relationship between the variables;
assessed the quality of the resulting regression line;
were able to see deviations of the calculated data from the data of the original set;
predicted future values of the dependent variable.
If regression function defined, interpreted and justified, and the assessment of the accuracy of the regression analysis meets the requirements, the constructed model and predicted values can be considered to have sufficient reliability.
The predicted values obtained in this way are the average values that can be expected.
In this work we reviewed the main characteristics descriptive statistics and among them such concepts as average value,median,maximum,minimum and other characteristics of data variation.
The concept was also briefly discussed emissions. The characteristics considered relate to the so-called exploratory data analysis; its conclusions may not apply to the general population, but only to a sample of data. Exploratory data analysis is used to obtain primary conclusions and form hypotheses about the population.
The basics of correlation and regression analysis, their tasks and possibilities for practical use were also discussed.
The main purpose of regression analysis consists in determining the analytical form of communication in which the change in the effective characteristic is due to the influence of one or more factor characteristics, and the set of all other factors that also influence the effective characteristic are taken as constant and average values.
Regression Analysis Problems:
a) Establishing the form of dependence. Regarding the nature and form of the relationship between phenomena, a distinction is made between positive linear and nonlinear and negative linear and nonlinear regression.
b) Determining the regression function in the form of a mathematical equation of one type or another and establishing the influence of explanatory variables on the dependent variable.
c) Estimation of unknown values of the dependent variable. Using the regression function, you can reproduce the values of the dependent variable within the interval of specified values of the explanatory variables (i.e., solve the interpolation problem) or evaluate the course of the process outside the specified interval (i.e., solve the extrapolation problem). The result is an estimate of the value of the dependent variable.Paired regression is an equation for the relationship between two variables y and x: , where y is the dependent variable (resultative attribute); x is an independent explanatory variable (feature-factor).
There are linear and nonlinear regressions.
Regressions that are nonlinear with respect to the estimated parameters: The construction of a regression equation comes down to estimating its parameters. To estimate the parameters of regressions linear in parameters, the least squares method (OLS) is used. The least squares method makes it possible to obtain such parameter estimates at which the sum of squared deviations of the actual values of the resultant characteristic y from the theoretical ones is minimal, i.e.
Linear regression: y = a + bx + ε
Nonlinear regressions are divided into two classes: regressions that are nonlinear with respect to the explanatory variables included in the analysis, but linear with respect to the estimated parameters, and regressions that are nonlinear with respect to the estimated parameters.
Regressions that are nonlinear in explanatory variables: .
.
For linear and nonlinear equations reducible to linear ones, the following system is solved with respect to a and b:
You can use ready-made formulas that follow from this system:
The closeness of the connection between the phenomena being studied is assessed by the linear coefficient of pair correlation for linear regression:
and correlation index - for nonlinear regression:
The quality of the constructed model will be assessed by the coefficient (index) of determination, as well as the average error of approximation.
Average approximation error - average deviation of calculated values from actual ones: .
.
The permissible limit of values is no more than 8-10%.
The average elasticity coefficient shows by what percentage on average the result y will change from its average value when the factor x changes by 1% from its average value:
.The purpose of analysis of variance is to analyze the variance of the dependent variable:
,
where is the total sum of squared deviations;
- the sum of squared deviations due to regression (“explained” or “factorial”);
- residual sum of squared deviations.
The share of variance explained by regression in the total variance of the resulting characteristic y is characterized by the coefficient (index) of determination R2:
The coefficient of determination is the square of the coefficient or correlation index.The F-test - assessing the quality of the regression equation - consists of testing the hypothesis No about the statistical insignificance of the regression equation and the indicator of the closeness of the relationship. To do this, a comparison is made between the actual F fact and the critical (tabular) F table values of the Fisher F-criterion. F fact is determined from the ratio of the values of factor and residual variances calculated per degree of freedom:
 ,
,
where n is the number of population units; m is the number of parameters for variables x.
F table is the maximum possible value of the criterion under the influence of random factors at given degrees of freedom and significance level a. The significance level a is the probability of rejecting the correct hypothesis, provided that it is true. Typically a is taken to be 0.05 or 0.01.
If F table< F факт, то Н о - гипотеза о случайной природе оцениваемых характеристик отклоняется и признается их статистическая значимость и надежность. Если F табл >F fact, then the hypothesis H o is not rejected and the statistical insignificance and unreliability of the regression equation is recognized.
To assess the statistical significance of regression and correlation coefficients, Student's t-test and confidence intervals for each indicator are calculated. A hypothesis is put forward about the random nature of the indicators, i.e. about their insignificant difference from zero. Assessing the significance of regression and correlation coefficients using Student's t-test is carried out by comparing their values with the magnitude of the random error:
; ; .
Random errors of the linear regression parameters and the correlation coefficient are determined by the formulas:
Comparing the actual and critical (tabular) values of t-statistics - t table and t fact - we accept or reject the hypothesis H o.
The relationship between the Fisher F-test and the Student t-statistic is expressed by the equality
If t table< t факт то H o отклоняется, т.е. a, b и не случайно отличаются от нуля и сформировались под влиянием систематически действующего фактора х. Если t табл >t is a fact that the hypothesis H o is not rejected and the random nature of the formation of a, b or is recognized.
To calculate the confidence interval, we determine the maximum error D for each indicator:
, .
The formulas for calculating confidence intervals are as follows:
; ;
; ;
If zero falls within the confidence interval, i.e. If the lower limit is negative and the upper limit is positive, then the estimated parameter is taken to be zero, since it cannot simultaneously take both positive and negative values.
The forecast value is determined by substituting the corresponding (forecast) value into the regression equation. The average standard error of the forecast is calculated: ,
,
Where
and a confidence interval for the forecast is constructed: ;
;  ;
; 
Where .
.Example solution
Task No. 1. For seven territories of the Ural region in 199X, the values of two characteristics are known.
Table 1.
Required: 1. To characterize the dependence of y on x, calculate the parameters of the following functions:
a) linear;
b) power (you must first perform the procedure of linearization of the variables by taking the logarithm of both parts);
c) demonstrative;
d) an equilateral hyperbola (you also need to figure out how to pre-linearize this model).
2. Evaluate each model using the average error of approximation and Fisher's F test.Solution (Option No. 1)
To calculate parameters a and b of linear regression (calculation can be done using a calculator).
solve a system of normal equations for A And b:
Based on the initial data, we calculate :
:
y x yx x 2 y 2 A i l 68,8 45,1 3102,88 2034,01 4733,44 61,3 7,5 10,9 2 61,2 59,0 3610,80 3481,00 3745,44 56,5 4,7 7,7 3 59,9 57,2 3426,28 3271,84 3588,01 57,1 2,8 4,7 4 56,7 61,8 3504,06 3819,24 3214,89 55,5 1,2 2,1 5 55,0 58,8 3234,00 3457,44 3025,00 56,5 -1,5 2,7 6 54,3 47,2 2562,96 2227,84 2948,49 60,5 -6,2 11,4 7 49,3 55,2 2721,36 3047,04 2430,49 57,8 -8,5 17,2 Total 405,2 384,3 22162,34 21338,41 23685,76 405,2 0,0 56,7 Wed. meaning (Total/n) 57,89 54,90 3166,05 3048,34 3383,68 X X 8,1 s 5,74 5,86 X X X X X X s 2 32,92 34,34 X X X X X X 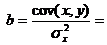

Regression equation: y = 76,88 - 0,35X. With an increase in the average daily wage by 1 rub. the share of expenses for the purchase of food products decreases by an average of 0.35% points.
Let's calculate the linear pair correlation coefficient:
The connection is moderate, inverse.
Let's determine the coefficient of determination:
The 12.7% variation in the result is explained by the variation in the x factor. Substituting actual values into the regression equation X, let's determine the theoretical (calculated) values . Let's find the value of the average approximation error:
On average, calculated values deviate from actual ones by 8.1%.
Let's calculate the F-criterion:
since 1< F < ¥ , should be considered F -1 .
The resulting value indicates the need to accept the hypothesis But oh the random nature of the identified dependence and the statistical insignificance of the parameters of the equation and the indicator of the closeness of the connection.
1b. The construction of a power model is preceded by the procedure of linearization of variables. In the example, linearization is performed by taking logarithms of both sides of the equation:
WhereY=lg(y), X=lg(x), C=lg(a).For calculations we use the data in table. 1.3.
Table 1.3
Y X YX Y2 X 2 A i 1 1,8376 1,6542 3,0398 3,3768 2,7364 61,0 7,8 60,8 11,3 2 1,7868 1,7709 3,1642 3,1927 3,1361 56,3 4,9 24,0 8,0 3 1,7774 1,7574 3,1236 3,1592 3,0885 56,8 3,1 9,6 5,2 4 1,7536 1,7910 3,1407 3,0751 3,2077 55,5 1,2 1,4 2,1 5 1,7404 1,7694 3,0795 3,0290 3,1308 56,3 -1,3 1,7 2,4 6 1,7348 1,6739 2,9039 3,0095 2,8019 60,2 -5,9 34,8 10,9 7 1,6928 1,7419 2,9487 2,8656 3,0342 57,4 -8,1 65,6 16,4 Total 12,3234 12,1587 21,4003 21,7078 21,1355 403,5 1,7 197,9 56,3 Average value 1,7605 1,7370 3,0572 3,1011 3,0194 X X 28,27 8,0 σ 0,0425 0,0484 X X X X X X X σ 2 0,0018 0,0023 X X X X X X X Let's calculate C and b:
We get a linear equation: .
.
Having performed its potentiation, we get:
Substituting actual values into this equation X, we obtain theoretical values of the result. Using them, we will calculate the indicators: tightness of connection - correlation index and average approximation error
The characteristics of the power-law model indicate that it describes the relationship somewhat better than the linear function.1c. Constructing the equation of an exponential curve
preceded by a procedure for linearizing variables by taking logarithms of both sides of the equation:

For calculations we use the table data.Y x Yx Y2 x 2 A i 1 1,8376 45,1 82,8758 3,3768 2034,01 60,7 8,1 65,61 11,8 2 1,7868 59,0 105,4212 3,1927 3481,00 56,4 4,8 23,04 7,8 3 1,7774 57,2 101,6673 3,1592 3271,84 56,9 3,0 9,00 5,0 4 1,7536 61,8 108,3725 3,0751 3819,24 55,5 1,2 1,44 2,1 5 1,7404 58,8 102,3355 3,0290 3457,44 56,4 -1,4 1,96 2,5 6 1,7348 47,2 81,8826 3,0095 2227,84 60,0 -5,7 32,49 10,5 7 1,6928 55,2 93,4426 2,8656 3047,04 57,5 -8,2 67,24 16,6 Total 12,3234 384,3 675,9974 21,7078 21338,41 403,4 -1,8 200,78 56,3 Wed. zn. 1,7605 54,9 96,5711 3,1011 3048,34 X X 28,68 8,0 σ 0,0425 5,86 X X X X X X X σ 2 0,0018 34,339 X X X X X X X Values of regression parameters A and IN amounted to:
The resulting linear equation is: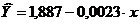 .
Let us potentiate the resulting equation and write it in the usual form:
.
Let us potentiate the resulting equation and write it in the usual form:
We will evaluate the closeness of the connection through the correlation index: