Fog computing instead of cloud computing: a new concept for data distribution. Briefly and clearly about “fog computing”
July 01, 2016
Kommersant learned about a new order from the president: relevant departments and Rostelecom should begin preparing the infrastructure for “fog computing.” Let's figure out what " fog computing”, and what infrastructure they need.
What's happened?
The Administration of the President of the Russian Federation instructed the Ministry of Telecom and Mass Communications, the Ministry of Industry and Trade, Rostelecom and the Agency for Strategic Initiatives to prepare the infrastructure of “fog computing” (literal translation from the English “fog computing”). This was reported by Kommersant with reference to its own sources in the government.
According to the publication’s source, the initiative to work in this area comes from Rostelecom and ASI. The idea of Fog computing belongs to Cisco Systems.
What is Fog Computing? Short
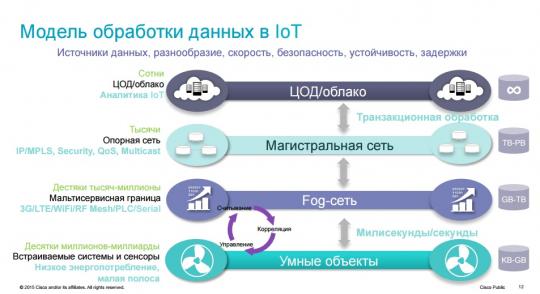
This is the name of a whole complex of technologies similar to cloud technologies, but closer to the “ground”. Fog Computing necessary condition for the implementation of the Internet of things.
"Foggy"– because the processing of information from devices does not take place in the Data Processing Center (cloud), but in computing centers (droplets), which are located at the “infrastructure boundaries”, that is, as close as possible to the device.
Fog Computing architecture expands cloud technologies to the physical “world of things”. Fog Computing allows you to shift computing, network functions storing information at the edge of the infrastructure.
Two paragraphs below, Cisco’s manager for the development of new technologies, Igor Girkin, explains in his fingers what “fog computing” is.
What does it mean to “prepare the infrastructure”?
Here is what Kommersant writes about this:
“It was instructed to work on the introduction of “fog computing” into the Russian economy, as well as the creation of software and hardware systems necessary for the operation of the “fog computing” infrastructure”“Kommersant quotes an unnamed source.
The results of completing the assignment must be presented in October. The ministries have already begun consultations with companies that are involved in the Internet of Things and are familiar with fog computing technologies.
Why does Russia need Fog Computing?
Fog computing is necessary for further development“Internet of things”, the market size of which will almost triple by 2020 and, according to IDC forecast, will exceed $7 billion.
The Agency for Strategic Initiatives is engaged, in particular, in identifying promising markets in which domestic companies could occupy a significant niche. Probably ASI saw in new technology potential. Which is good.
In November 2015, Cisco, Microsoft, Dell, ARM, Intel and Princeton University founded the OpenFog Consortsium to create an open architecture that would provide scalability and interoperability across devices.
Igor Girkin
Cisco Emerging Technologies Manager
Excerpts from a speech at the Connected Russia conference
“The number of devices connected to the Internet is growing, and the problem arises of how to quickly and reliably connect not only new devices, but also the legacy base. Look in your closet under the sink, there are counters there. They are not IP, and they know nothing about IP. However, there are wires there that you can connect them to. All this equipment needs to be connected. For what? For various reasons. This, of course, is both monetization of services and convenience.
If we put, say, a sensor on an elderly person, and it does not work for some time, this still does not mean anything. Maybe a person is sitting and reading a book. Needed additional sensors, information from the sensors must be correlated right there - either in the apartment or in the house - and a decision must be made - indeed, the person is lying immobilized, no longer breathing, or just sitting.”

The traditional communication system today looks like this: there is a client device, and there is a data center. By the time the data reaches the data center, it may become outdated. In some cases, the delay does not matter, and sometimes it can become critical.
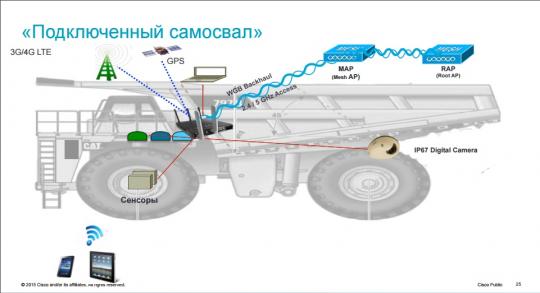
“It is clear that if a dog runs around with a collar that transmits information about its location and whether its heart is beating or not, the owner, if he is sitting far from the dog, will receive information from the data center. But if we are talking about machine-to-machine communication in the modern sense, then it is desirable that the device be connected as close as possible to intelligent nodes with distributed computing.”
Controllers have been known for a long time, but they do not provide network interaction, which means they cannot accept the most adequate and effective solutions. In addition, it is generally unclear how to connect the so-called legacy devices to the network. Various companies are developing different devices, but they try to make them as standardized as possible.
“The concept of fog computing not only implies the transfer of intelligence closer to the end device, but also allows you to connect this end device with any interfaces. People can develop interfaces themselves, they can provide these interfaces with the necessary tools thanks to virtualization, and connect the device to the network. Make IoT – Internet of Things.”
Examples of Fog computing by Cisco

The software backbone will likely include a hypervisor capable of consolidating the power of the fog network and presenting them as a single multiprocessor system. This approach was already used in the OpenMosix OS at one time. The resources requested by the consumer (another “drop”) will be allocated in the form virtual machine, in which, for example, a bare-metal Java machine runs. It deploys the application package, runs the application, and so on...
Particularly worth mentioning is the role of droplet computers as a “user terminal” - this is the only scenario when some kind of peripheral is connected to the droplet. I see it as some kind of shell devices, like SmartDocks from Motorola: shell-smartphone, shell-tablet, shell-laptop, shell-desktop. The laptop shell and the desktop shell can easily accommodate several modules, and thus carry a multi-node private cluster, a “cloud of fog”. And the person turns into a real PAN.
With this approach, upgrading the system turns into simply connecting new nodes. If droplet nodes are the size of a microSD card, future system unit it may well be a three-liter jar with plates wireless power at the ends, and a thin thread of optics to a huge monitor.
In such a situation, “three kilograms of counterfeit servers” no longer looks like nonsense.
Summarizing the above, it can be noted that we will not see “fog PCs” and “fog networks” until the following requirements are met:
Availability of highly efficient (in W/MIPS) SoCs of common architecture (ARM, x86, AMD64) with minimal wiring at an extremely low price ($2 - $10)
- Standardization and distribution of consolidating hypervisors
- Widespread distribution of IPv6 and high-speed interfaces - both cable and wireless.
- Availability of cheap and capacious autonomous power sources (at least an order of magnitude more capacious than lithium-ion batteries)
The issues of authentication, authorization, and sharing of “droplet” resources by several “fog networks” remained behind the scenes.
Fog computing was talked about more or less loudly last year, and now this direction is gradually emerging into the market light.
This is still the same supply of services, applications, data, computing power and virtual storages through the network, only in the case of fog, a fundamental emphasis is placed on the fact that all these services are provided absolutely distributed, without any compromises in terms of the mandatory availability of each node of the fog (technically - mesh-) network, which can fail at any time, but It’s okay: there will be millions and billions of such nodes (“droplets” in Fog Computing terminology).
By the way, with the infrastructure infrastructure. -- cloud computing, which formally lacks the most important concept of a “node,” is perhaps why it is subject to such fierce criticism at the level of terminology. But Digital Fog, in its truest sense, is a huge number of drops, each of which is a microchip that can function autonomously for several years and perform certain calculations upon request. Such drops can be scattered at every step, scattered on the table, carried in pockets, etc. Some cyberpunk games have a similar concept of "leveling up" - where a character's abilities are determined by the number of chips he can use to develop himself.
Technically, Fog Computing involves the use of exclusively distributed software systems and parallel programming environments supporting billions of nodes.
Main disadvantage cloud computing- this is the last mile, slow delivery of service to the user from a specific data center without delays. This principle is replaced by providing it with systems that combine the rate of fire local systems and the power of the clouds. The everything-as-a-service model can finally realize the slogan “data from any device, any time, anywhere in the world.”
But what is it that is clearly noticeable for end user difference between fog and cloud?
Delivering data physically closer to the user. Now the necessary data from the American cloud data center is being sent to my gadget across the world. And in the fog they will be stored on my coffee table, cached automatically and completely unnoticed, and loaded with lightning speed through local network. Particularly effective in this context are fog services that provide streaming services (for example, online movies) - in particular, due to the caching of films in local fogs (remember, by analogy, the local file “garbage dumps” with terabytes of software that once existed with each provider, from where necessary software could be loaded at lightning speed).
- geographical reference of clouds to a specific area. Even if the data center is physically located next door to my organization, which processes Big Data, these flows will go to it across the entire planet (70% through channels in Western Europe and the USA, controlled by the NSA))). And fog technology will make it possible to organize a fog service directly in the office, which will be connected to the data center almost directly, and without expensive fuss with laying optical fiber.
- operation and administration will be significantly simplified mobile devices- now their number and the load on them are growing rapidly, and fog allows you to significantly speed up the delivery of the necessary data to smartphones and at the same time maintain total control over their work and, for example, determine the location of an employee in the corporate fog with any accuracy.
- it is important that fog is starting to be implemented throughout the vertical - from the bottom to the top management and from ordinary shops to the largest online services. All of them are extremely interested in the high-speed delivery of their data to users intensively using their gadgets around the world, but when the organization has 1-2 data centers, this process turns into a technological nightmare.
- real possibility of seamless integration of fog and cloud! Today, it is quite possible to isolate user data so that it “lives” on the edge of the cloud, standing out in geographically local fogs.
You can also say this: clouds are something that lives infrastructurally in a data center. Fog is something that lives on earth, right next to us. In addition, all experts note the very high security of the fog system - due to the complex process of distributed processing of data broken into pieces by a huge number of nodes.
By and large, Fog Computing is the last intermediate stage between cloud computing and the Internet of Things, or even the Internet of Everything.
Most cloud computing services fall into three general groups: infrastructure as a service (IaaS), platform as a service (PaaS), and software as a service (SaaS). Such services are sometimes called a cloud computing stack because they stack on top of each other. If you find out what they are and how they differ from each other, it will be easier for you to realize your business goals.
Infrastructure as a Service (IaaS)
Platform as a Service (PaaS)
PaaS refers to cloud computing services that provide an on-demand environment for developing, testing, delivering applications software and management of them. PaaS makes it easier for developers quick creation web applications or mobile applications without having to deal with the underlying infrastructure of servers, storage, networking and databases required for development. More information see What is PaaS?
Software as a service (SaaS)
SaaS is a method of delivering application software over the Internet on demand and usually on a subscription basis. In a SaaS scheme, cloud providers host and manage the software and underlying infrastructure, and handle all maintenance, including software updates and security patches. Users connect to the application over the Internet, usually using a web browser on their phone, tablet, or PC. For more information, see
If it seems to you that you can’t see anything in the picture, then I will answer, the picture clearly shows fog! ;) In connection with emerging from the forced, stagnant silence, I am publishing my small futurological essay.
Hooray! What the Bolsheviks were afraid to ask for so long has happened! Following cloud computing, today we are ushering in the era of fog computing!
Fog computing - and it sounds kind of foggy. I’ll try to convey this paradigm in a nutshell to a reader unarmed with Wikipedia and Google. For the armed, we will have to say that this phrase has already been ruined by one of the types of cloud computing, which is fundamentally no different from them.
So, fog computing. As you might guess, “fog” is, like “cloud,” some connected distributed computing power. Let's apply a differential approach to the cloud and assume that instead of one discrete cloud node (yes, there are no nodes in real clouds and this is where the falsity of this term lies) consisting of: processor, RAM, ROM, input/output devices, we have a scalar field (distribution in volume density) computing power, RAM and permanent memory, as well as a vector field of data streams.
At this point you can exhale and I’ll try further without these problems. Computers are getting smaller. Computers are getting cheaper. Now an MP3 player has computing power orders of magnitude greater than the first computer created to solve extremely important military and scientific problems. I am silent about the size and most importantly - energy consumption. Now the density of computing devices is so high that it is just right to apply to it statistical methods. I once saw an excellent article where the total calculation was given. power of devices in the context of computing. power of one device and it turned out that all the power is not in supercomputers, but in cheap mobile phones.
As computers become cheaper, communication systems also become cheaper. Bluetooth is available almost everywhere and I’m not sure that my sneakers don’t have it. And right now there are no obstacles left for all these weak little computers to unite into one big purple computing fog.
The “fog” is based on a “drop” - a microcontroller chip with memory and an interface for data transfer on board, and a chip wireless communication Mesh type (sensor network). The “drop” receives power from a small battery, which nevertheless will last for a couple of years of operation with regular breaks for sleep (picoPower from Atmel rules). The “drop” can be connected to input devices (sensors of all kinds, from temperature and voltage to position in space and the level of ultraviolet radiation) and output devices (LEDs, LCD and ice indicators, dry contacts, etc.) Already smacks of Skynet, not Is it true?
“And when we are two steps away from a pile of fabulous riches...” - as the hero of the famous cartoon musical sang, the most interesting thing remains - information that is not directly related to these same sensors can be stored and processed in this network. Obviously, for most tasks the performance of modern microcontrollers is more than enough and we get a field of excess computing power. And, as you know, there is never too much money, ammunition and computing power.
This is the kind of thing we get. Let's see if S. Lem was right in his “Futurological Congress” and I was right in the computational fog?